
前言
最近帮忙参与一个HVV的项目,目标比较大,想先通过自动化跑一下,把漏掉的补上,自动化需要传入主域名列表,拿到控股公司列表之后准备批量查询这些公司的注册域名信息。
然而,我尝试过之前收集的ICP备案查询工具,发现它们都存在以下一个问题:
不符合预期,比如通过一些第三方网站API查询,数据不是最新的,导致达不到目标。
配置麻烦,参数麻烦,太重,使用太复杂,效果也不好。
如果不更新和维护,它将根本无法使用。
下午的图像
于是花了一晚上的时间寻找一个还算靠谱的方法,简单分享给大家,据说得到的数据都是从官方#//index.php 实时查询出来的。
使用物品
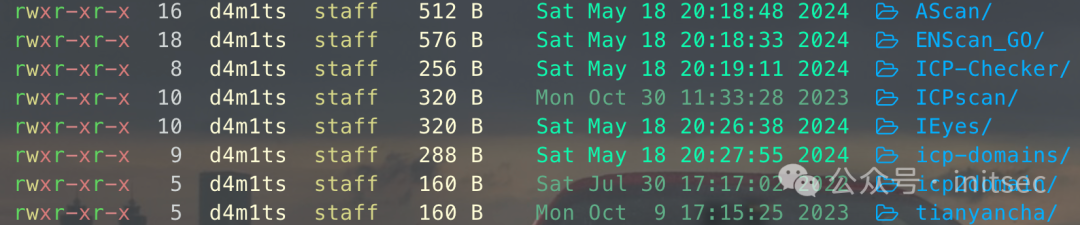
所用到的项目就贴一张介绍图吧,有兴趣的可以看一下。
自动编码,版本(yolo8+未转换孪生神经网络,非生产环境),性能提升,支持更换模型,数据集为手动生成,存在错误。权重文件可以训练两次,欢迎大家贡献更好的模型或者提供更真实、更全面的数据集来优化模型。此发布方式不适用于生产环境
但实际使用过程中会发现问题:如果只部署一个,多次使用后大概率会出错,估计是被反爬虫机制识别了。
这时候有的老板肯定会说:我出动很多部队,能解决吗?
事实确实如此,但是服务器成本太高,所以创建了下面的衍生内容部分。
图像-pm 衍生
如果只是讲怎么搭建和使用这个东西的话我觉得没必要写出来,看一看就行了,这里我主要给大家一些思路,如何尽可能的降低自己的成本。
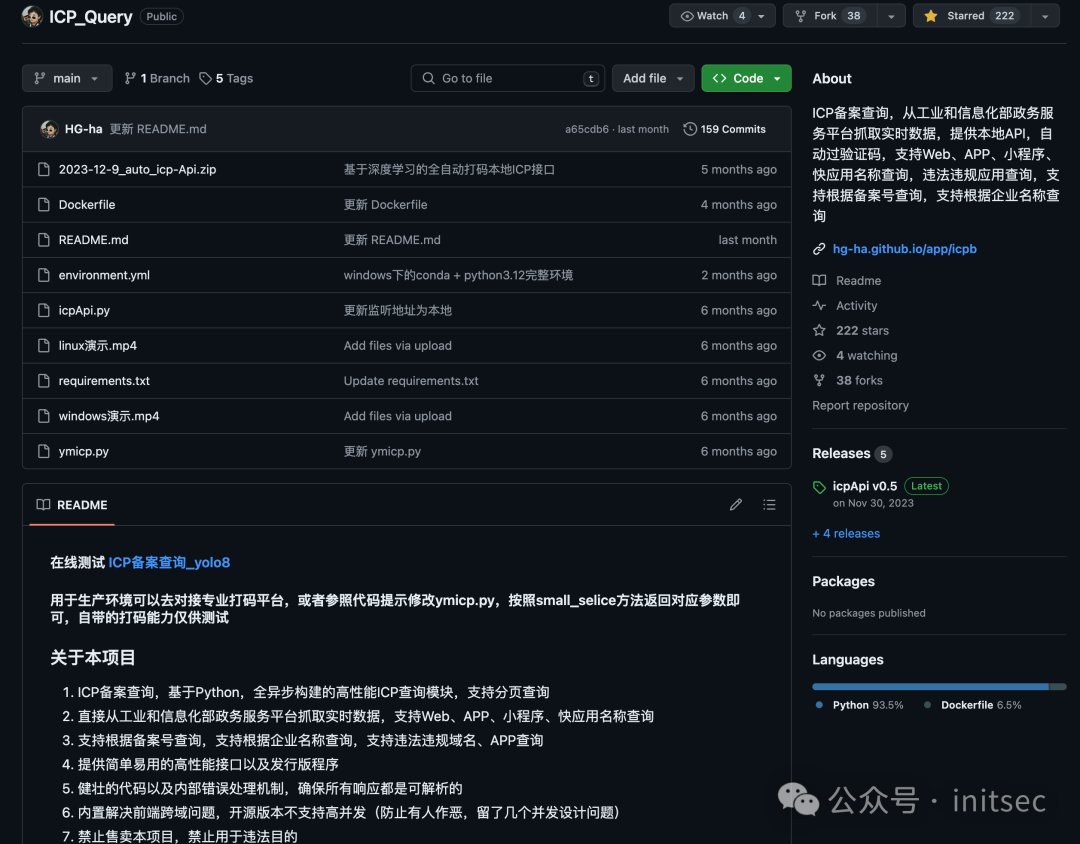
通过查看文档,我们发现这个东西是可以直接build的,build完之后就可以直接使用了,流程如下:
# 拉取镜像
docker pull yiminger/ymicp:yolo8_latest
# 运行并转发容器16181端口到本地所有地址
docker run -d -p 16181:16181 yiminger/ymicp:yolo8_latest
# 使用
curl http://127.0.0.1:16181/query/web?search=baidu.com
curl http://127.0.0.1:16181/query/web?search=深圳市腾讯计算机系统有限公司&pageNum=3&pageSize=20
这里有什么问题呢?经常搞卖淫的同学都知道,这里是没有任何授权的,也就是说你可以直接使用别人建好的平台。
那么如何找到别人搭建的平台呢?最快的方法当然是通过网络搜索引擎。
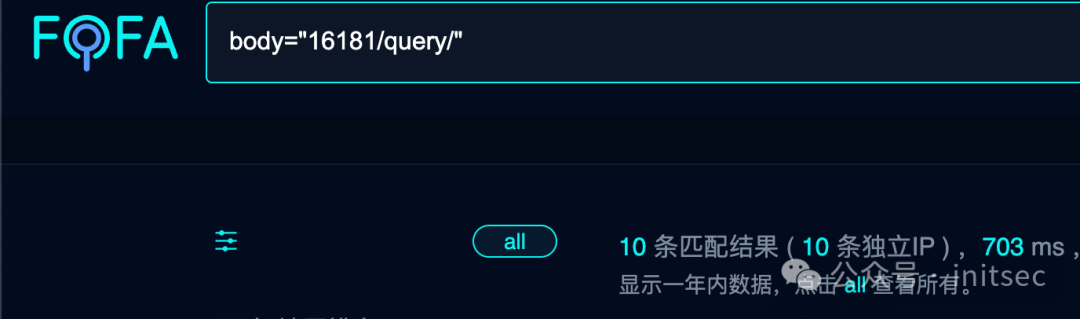
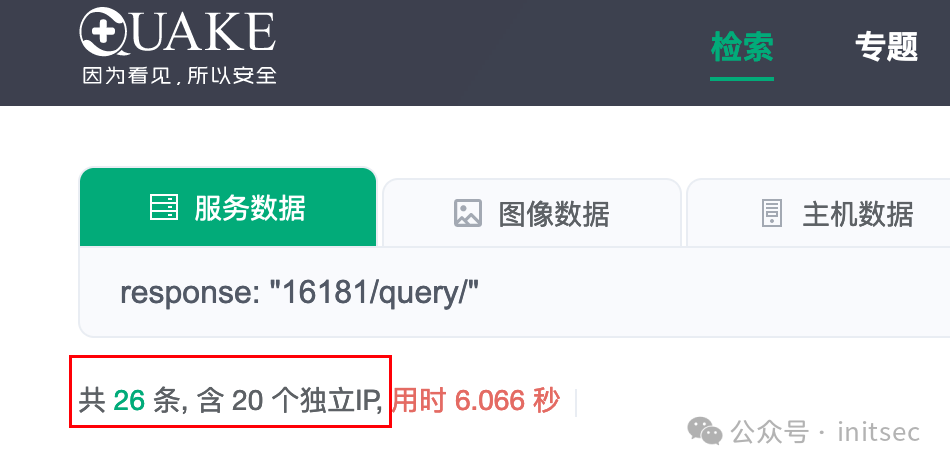
我自己构建了一个,发现了以下特点:
fofa: body="16181/query/"
quark: response: "16181/query/"
虽然不多,但是足够了。
下午的图像
下午的图像
这时候你只需要把这些平台整合起来,循环调用,拦截的问题就会大大减少。
代码
循环调用肯定是离不开代码实现的,但是在写代码的时候一定会遇到一些小问题,这里我就把技巧分享给大家,看图就好。
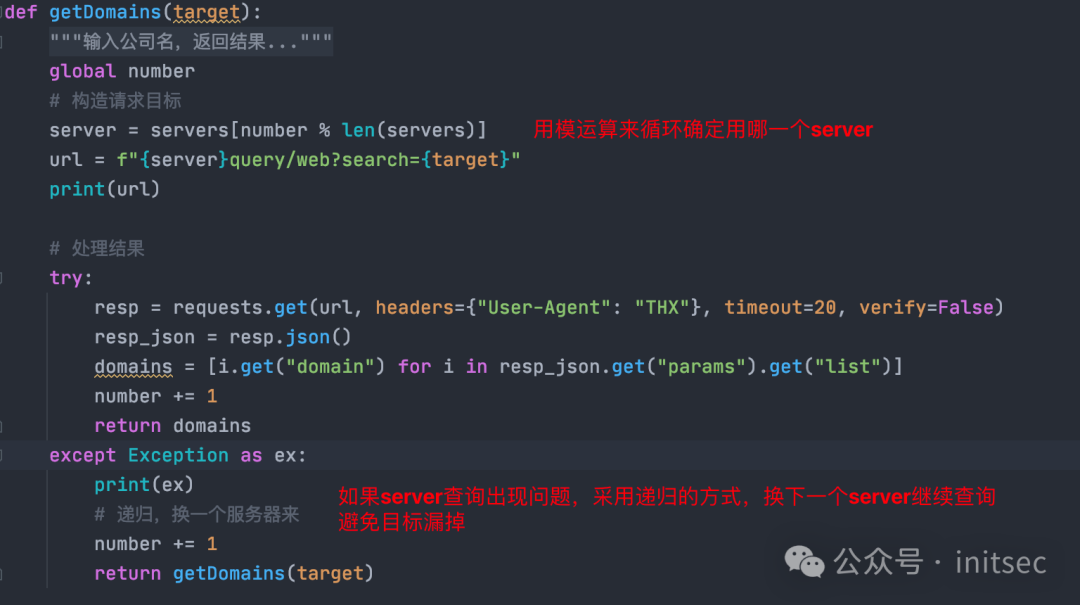
下午的图像
效果如下:
下午的图像
上面给出了核心函数,如果需要完整代码来上手,可以使用公众号回复“”获取。
-结尾-
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 