
好久没更新了,对不起关注我的朋友!本文灵感来源于做一个公司网站的项目。
我在做官网的时候只知道Nuxt是Vue的SSR框架,也知道Vue项目需要做SEO优化,需要用到SSR技术,所以就自己开发了。在叙述之前先列一个提纲,方便大家选择性阅读。
SSR原理应用 SEO优化处理 SSR原理应用
SSR(side)服务端渲染对于前端开发者来说已经很熟悉了,但是很多人对于具体的概念以及整个配置如何实现还是比较困惑的,本文讲解了以下几点
为什么要用SSR,它和浏览器渲染有什么不同,起什么作用?SSR概念
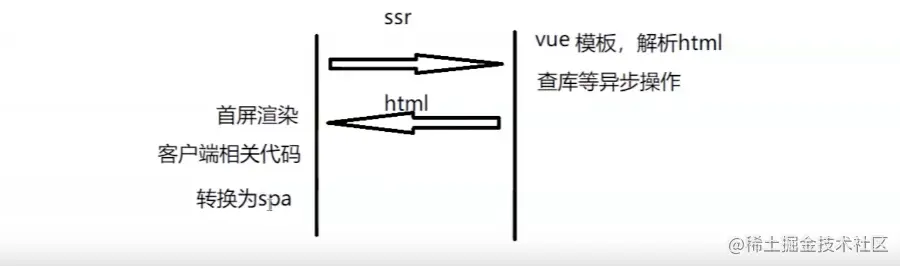
将 Vue 组件在服务器上渲染成 HTML 字符串并发送给浏览器,最终将这些静态标签“激活”成可交互的应用程序的过程称为服务端渲染。
传统的asp、jsp等网页渲染技术都是客户端向服务器发送请求,服务器通过查找数据库等操作拼出HTML,返回给客户端,在浏览器中进行渲染。
在如今的SPA框架中,比如Vue框架,当客户端发出请求时,服务端只返回一个HTML结构:
只有执行完Vue.js之后,配置的数据才会被渲染出来,执行过程中有些代码会进行Axois异步请求,向服务器发送请求,服务器返回相应数据才能继续渲染。
所以对于SPA项目来说,1.首屏渲染速度慢 2.对SEO不友好

SSR 是传统 Web 渲染技术与 SPA 之间的一种折衷:
如何建立一个可以实现 SSR 的项目
1.创建vue ssr项目
vue create ssr
安装依赖项
渲染器:vue--
Node.js 服务器:
npm i vue-server-renderer express -D
2.在创建的项目中添加文件夹,并创建index.js文件
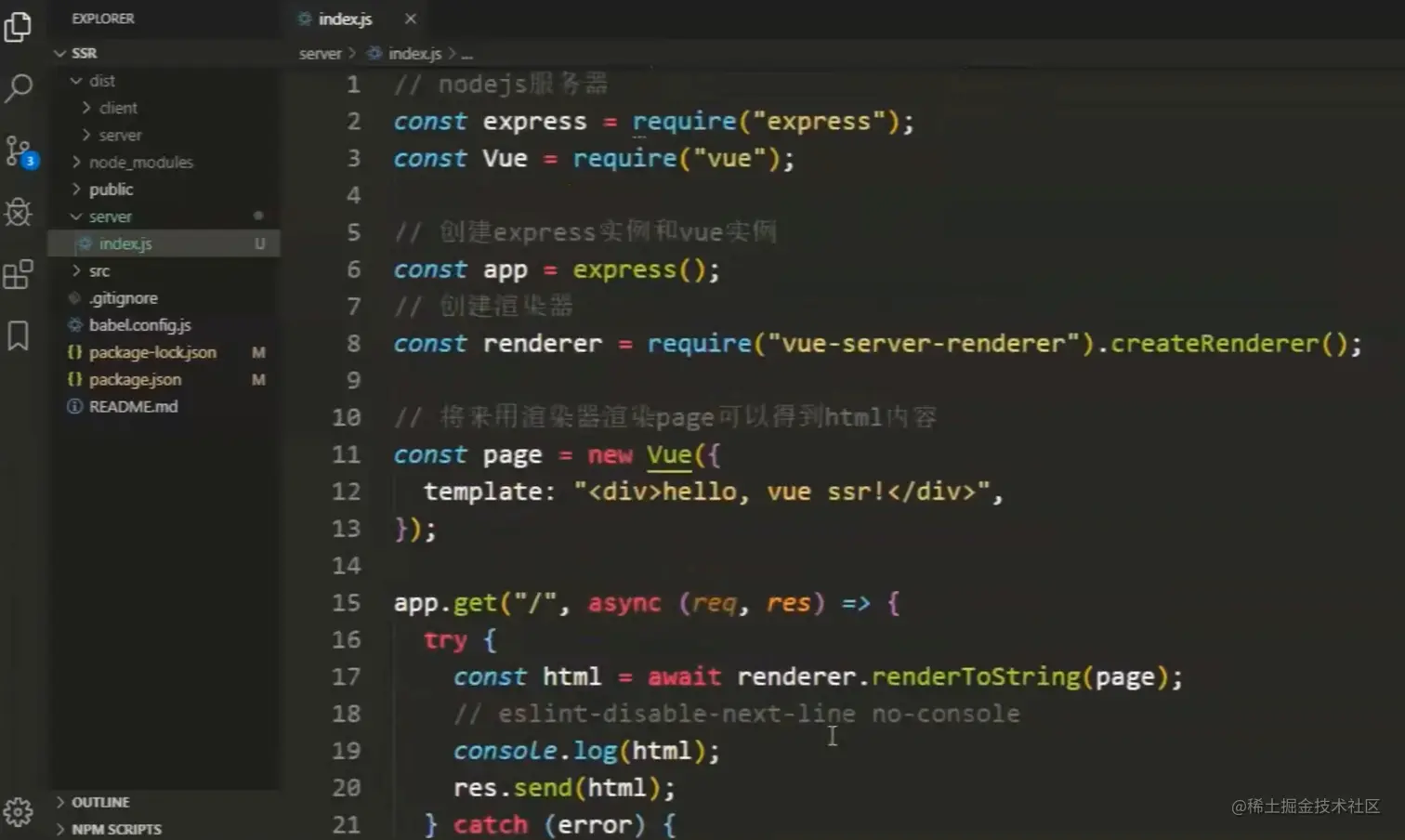
const express = require('express');
const Vue = require('vue');
const app = express();
const renderer = require('vue-server-renderer').createRenderer();
const port = 3000;
const page = new Vue({
data(){
return{
title:'技术直男星辰'
}
},
template:`
{{title}}
hello, vue ssr!
`
});
app.get('/',async (req,res)=>{
try {
const html = await renderer.renderToString(page)
res.send(html)
} catch(err){
res.status(500).send('服务器内部错误');
}
});
app.linsten(port,()=>{
console.log(`渲染服务器在${port}端口成功运行`)
})
在目录下执行一个简单的ssr,就设置好了
node ./index.js
开发中肯定会用到路由,所以需要创建一个文件夹。注意,这和我们以前创建路由的方式不一样,不是直接实例化一个路由进行配置,而是需要写一个工厂函数返回实例化的路由,因为每次用户请求都要创建新的路由,如果不重新创建的话就会产生混乱,这也是服务器负载增加的原因。
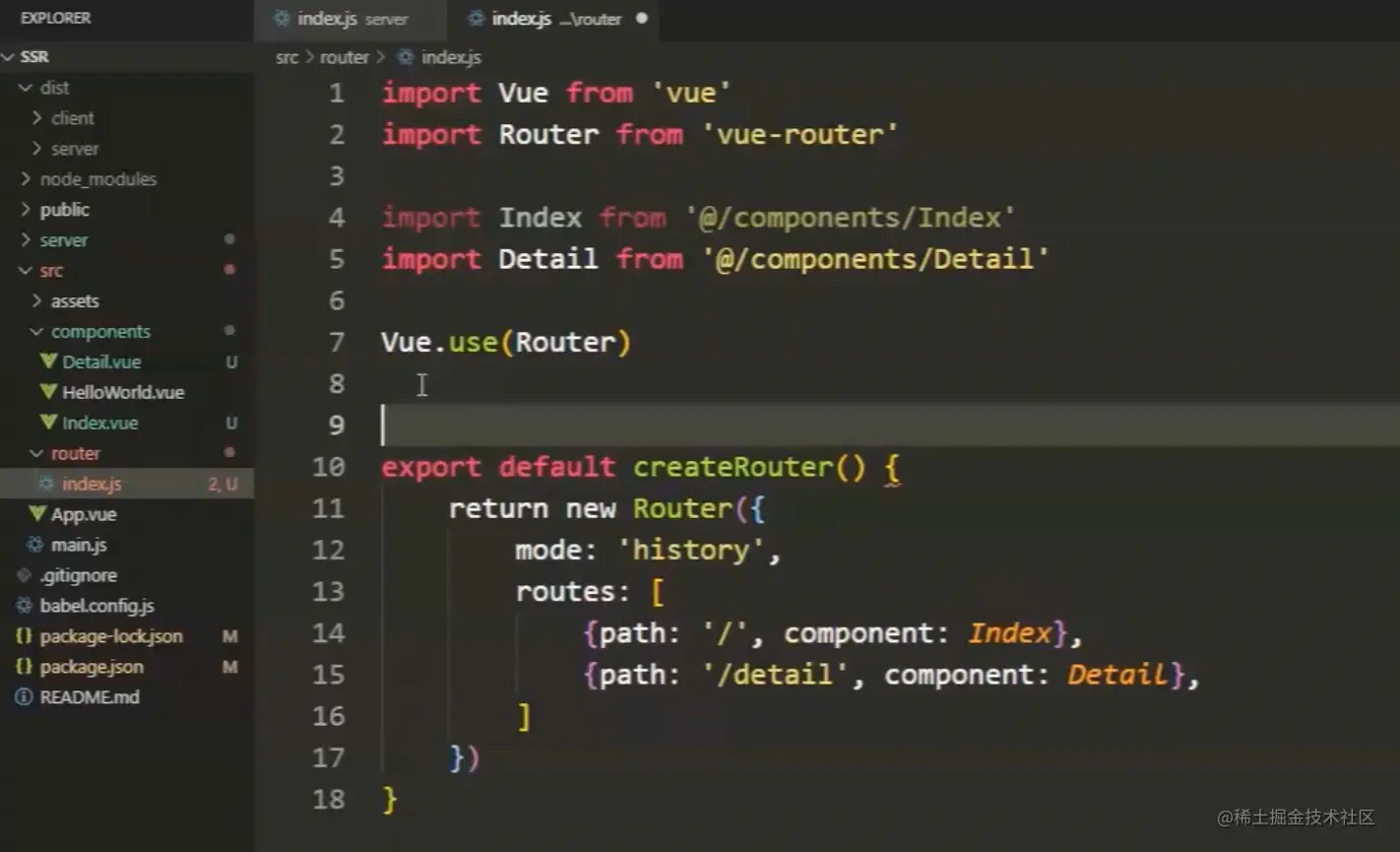
import Router from 'vue-router'
import Index form '@/components/Index';
import Detail form '@/components/Detial';
export default createRouter()=> {
return new Router({
mode:'history',
routes:[
{path:'/',component:Index},
{path:'/detail',component:Detail},
]
})
}
但是这样还不够,我们可以看到SSR的构建过程需要两个入口和一个公共入口,可以理解为项目中的main.js。
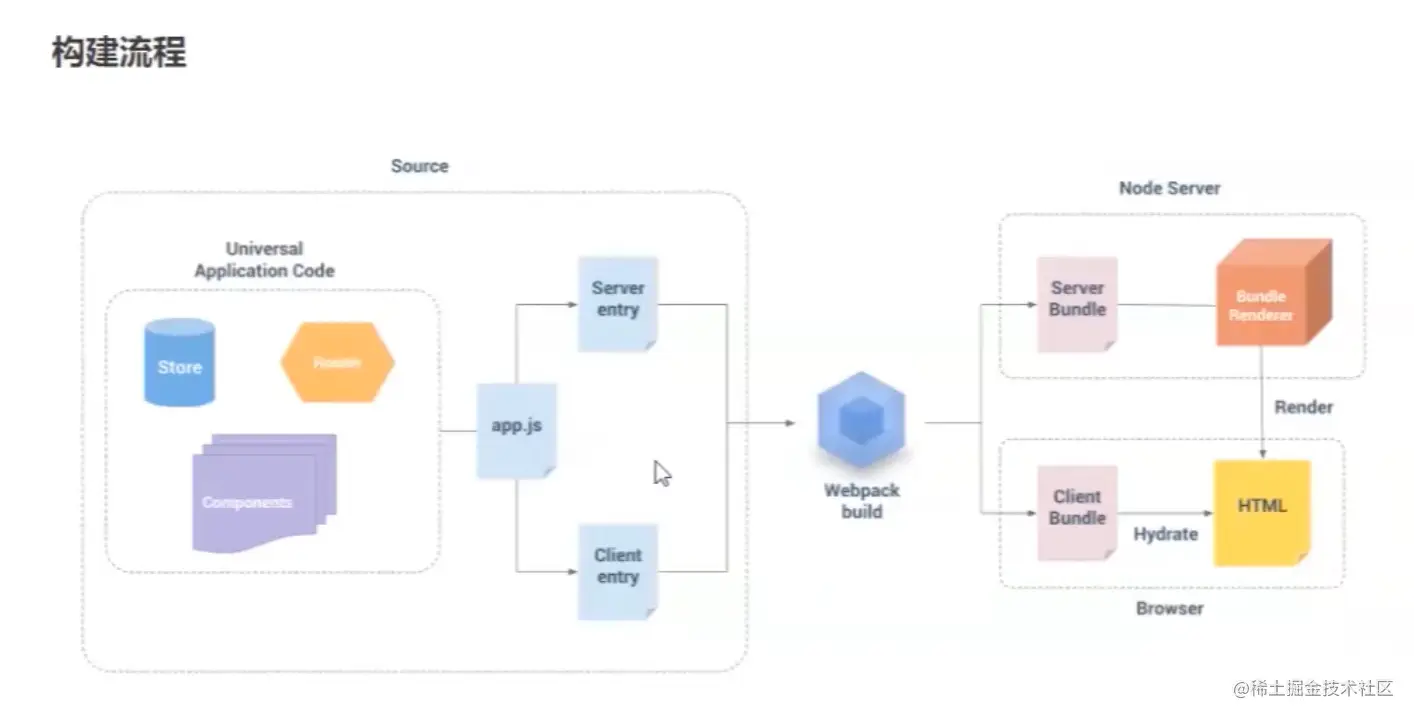
在src下创建app.js entry-serve.js entry-.js
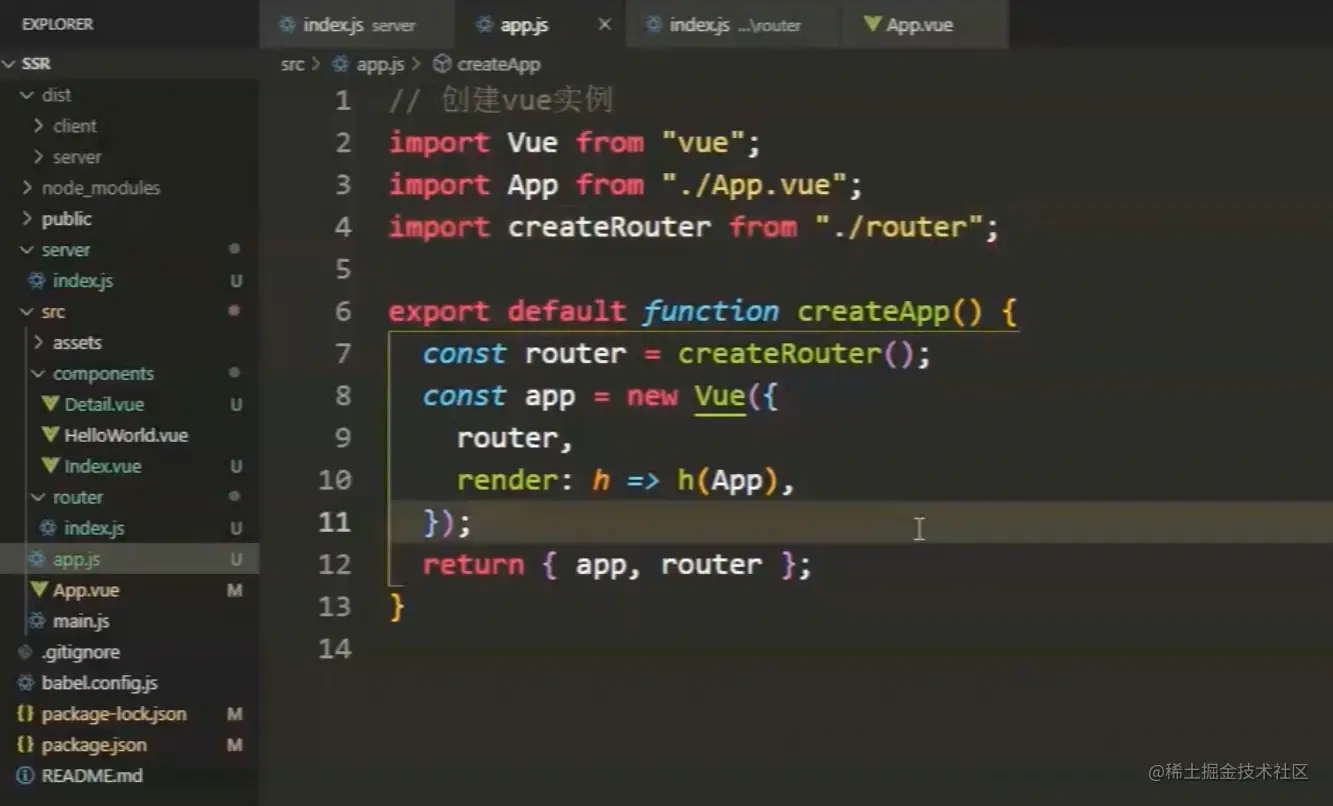
应用程序.js
app 是通用入口,由于是在服务端,所以不需要在 Vue 实例后面加 $mount 进行挂载
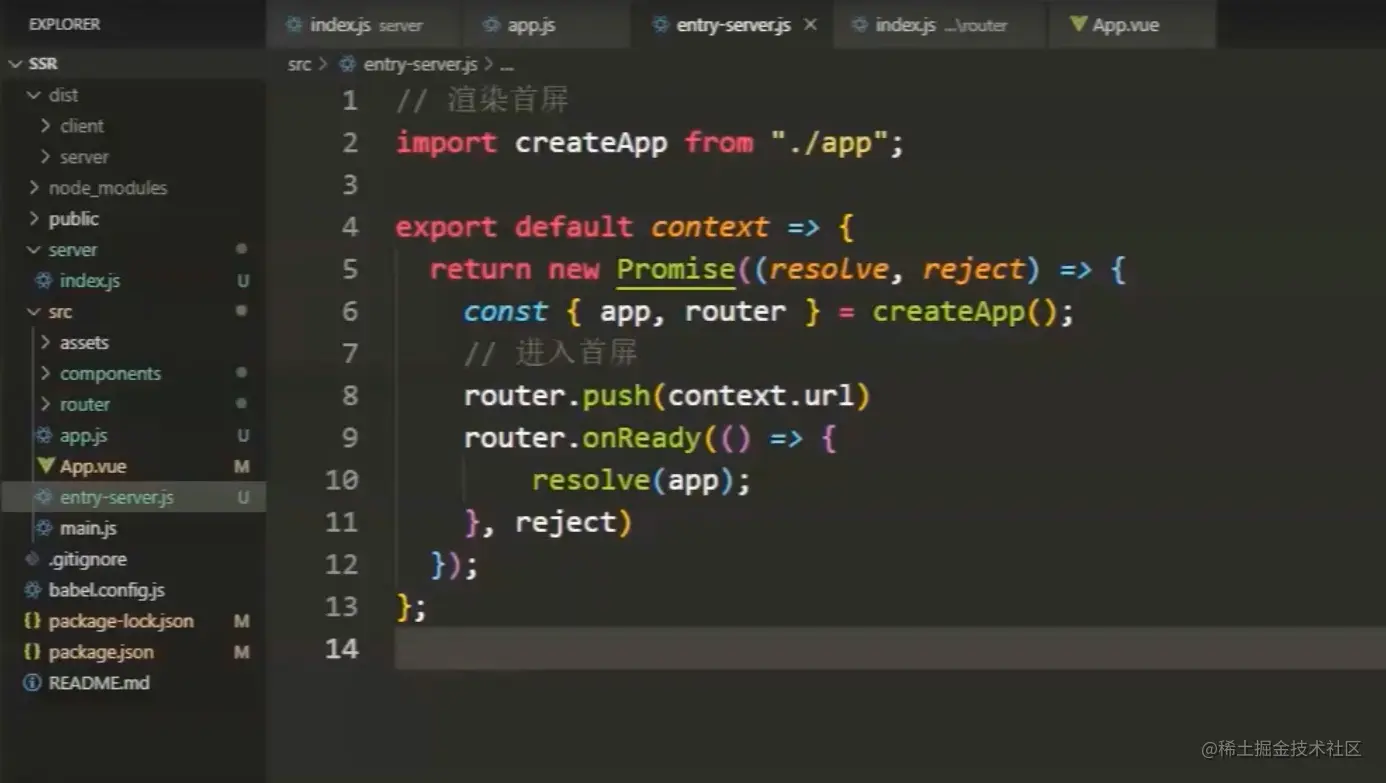
入口-.js
服务端入口从app.js引入,通过处理异步问题,可以在用户输入URL时返回执行成功的Vue实例。
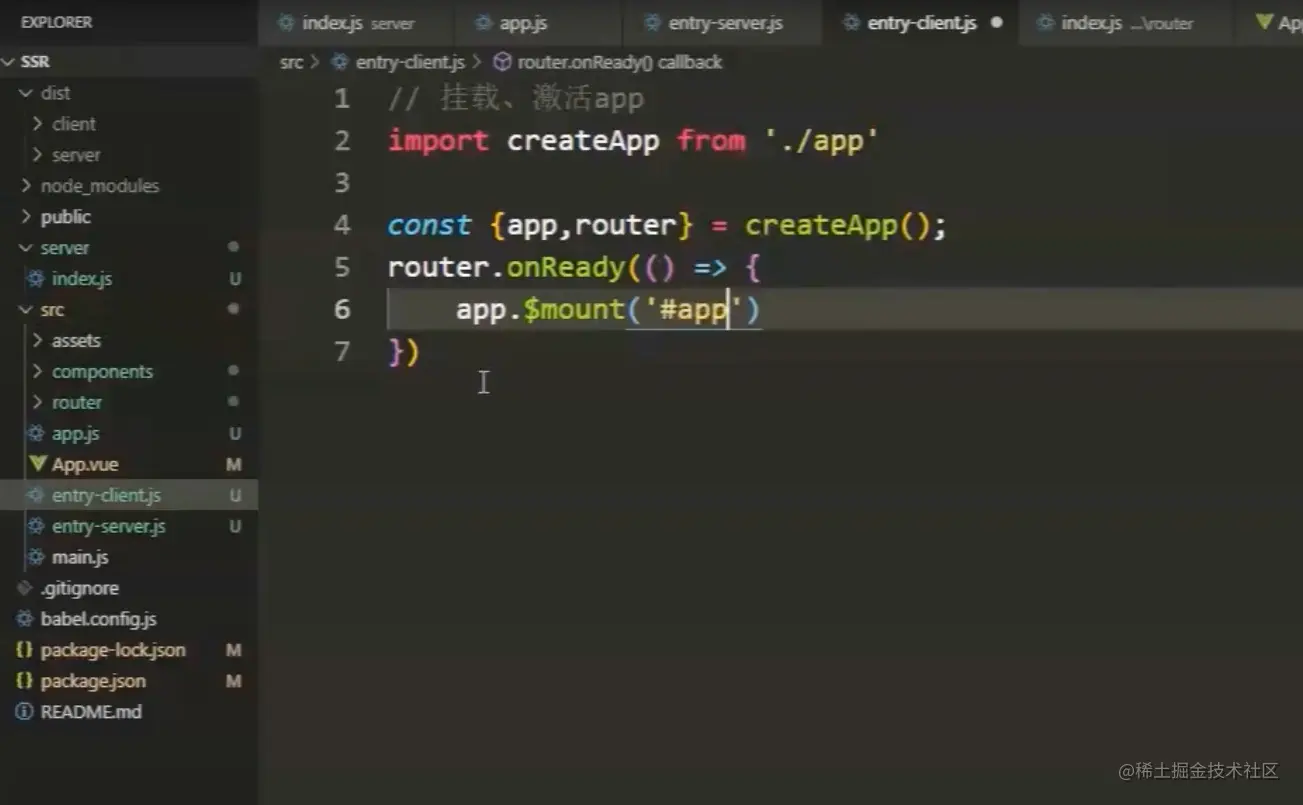
入口-.js
客户端入口,只需要将成功的实例挂载到#app即可
配置vue..js需要安装一些依赖项
vue--/-服务端渲染插件生成服务端包
vue--/-客户端渲染插件生成客户端包
用于跨平台设置和使用环境变量的 脚本
const VueSSRServerPlugin = require("vue-server-renderer/server-plugin");
const VueSSRClientPlugin = require("vue-server-renderer/client-plugin");
const TARGET_NODE = process.env.WEBPACK_TAGET === 'node';
const target = TARGET_NODE ? 'server' :'client';
module.exports = {
outputDir: './dist/' + target,
configureWebpack: ()=>({
entry: `./src/entry-${target}.js`,
devtool: 'source-map',
target: TARGET_NODE ?'node' :'web',
node: TARGET_NODE ?undefined : false,
output: {
libraryTarget: TARGET_NODE ? 'commonjs2' :undefined
},
plugins: [TARGET_NODE ?new VueSSRServerPlugin() : new VueSSRClientPlugin()]
})
}
配置打包命令.json
"scripts":{
"build:client":"vue-cli-service build",
"build:server":"cross-env WEBPACH_TARGET=node vue-cli-service build --mode server",
"build":"npm run build:client && npm run build:server"
}
改造前文件夹中的Index.js
const fs = require('fs')
//创建渲染器
const {createBundleRenderer} = require('vue-server-renderer');
const serverBundle = require('../dist/server/vue-ssr-server-bundle.json');
const clientManifest = require('../dist/client/vue-ssr-client-manifest.json');
const renderer = createBundleRenderer(serverBundle,{
runInNewContext:false,
template:fs.readFileSync('../public/index.temp.html','utf-8'),
clientManifest,
})
// 中间件处理静态文件请求
app.use(express,static('../dist/client'),index:false))
app.get('*',async (req,res)=>{
try {
const context = {
url:req.url,
title:'技术直男星辰'
}
const html = await renderer.renderToString(context)
res.send(html)
} catch(err){
res.status(500).send('服务器内部错误');
}
});
app.linsten(port,()=>{
console.log(`渲染服务器在${port}端口成功运行`)
})
刚刚在文件中引入了..//index.temp.html 需要创建一个主机模板文件,在文件夹中创建index.temp.html
html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width,initial-scale=1.0">
<title>Vue ssrtitle>
head>
<body>
<--vue-ssr-outlet--> 服务端渲染的口
body>
html>
至此所有项目都构建成功。
综上所述:
SSR 需要 node 服务中间层进行数据请求,然后编译模板输出 HTML 文件。需要两个入口文件 entry-entry-,针对不同的环境做不同的操作。当用户请求 node 服务时,返回的是刚刚实例化的 Vue,而不是普通的 SPA 只实例化一次。一些配置和宿主模板有约定好的写法规则,需要像 for if map 一样牢记。
让我们讨论下一个话题
SEO优化处理
由于我并不是专业的SEO优化人员,所以只能简单分享一些我在项目中遇到的经验:
在服务器根目录下创建txt文件,所有界面数据必须在源码中首次渲染时显示出来。优化路径问题,所有跳转路径使用标签跳转,不要使用事件跳转(如.push)。在TDK中添加更多页面描述,使用301重定向txt文件
百度百科上有很详细的介绍,这里就简单介绍一下,当爬虫要爬取一个网站的时候,会先在服务器根目录下寻找.txt文件,该文件规定了哪些爬虫可以访问这个网站,哪些域名允许爬虫访问进行数据采集,当然也规定了哪些爬虫不能访问,哪些网站不允许爬虫访问。它可以屏蔽掉一些网站上的一些比较大的的文件,比如图片,音乐,视频等,节省服务器带宽;它可以屏蔽掉网站上的一些死链接,方便搜索引擎抓取网站内容;设置网站地图连接,方便蜘蛛抓取页面。
写作字段含义:
User-agent:代表搜索引擎的类型,全选的时候就用*就可以了,比如搜狗网页版。
:禁止爬虫爬取的地址:/禁止爬取所有地址;:/admin/禁止爬取admin目录下的目录;:/?/禁止访问网站上所有含有问号(?)的URL;:/live/*.html禁止访问/cgi-bin/目录下所有以“.htm”为后缀的URL;:/.jpg$禁止爬取网页上所有.jpg格式的图片。
Allow:允许爬取资源 Allow:.htm$ 只允许访问以“.htm”为后缀的URL; :/cgi-bin/ 这里定义允许爬取cgi-bin目录下的目录; Allow:/tmp 这里定义允许爬取整个tmp目录
: 告诉爬虫程序该页面是站点地图
好奇的话可以百度一下,说一下一些使用误区:
1:如果网站上所有内容都需要被爬虫抓取,就没必要添加文件了,反正这个文件也不存在,爬虫默认就可以爬取所有页面。
当爬虫爬取到不存在的URL时,服务器会记录404,这与用户正常访问是一致的,所以为了避免记录大量的日志,需要添加爬虫规则。
第二:设置.txt文件里的所有文件都被搜索蜘蛛抓取,这样可以增加网站的收录率,即使网站里的js、css被爬虫收录了,也不会增加网站的收录率,还会浪费服务器性能。
所有界面数据必须在第一次渲染时在源代码中显示出来。
上面提到了,由于spa返回的页面是网页结构,需要等到框架脚本执行完才会出现内容。SSR技术其实就是为了解决内容输出的问题,通过SSR,接口返回的内容会在源码中体现出来,这样爬虫就可以直接爬取网页内容,收集到更多的关键词,从而提高网站排名。
优化路径问题
1.路径中不要带参数,比如查询参数。路径问题对SEO的影响也很大。路径一般分为三种:
1).动态路径:我们经常会用到查询参数,以?开头,用&=分隔传递不用的参数。爬虫遇到这种情况会递归往下读,当超过三个时,爬取会造成数据丢失。而且参数不宜过长。
2).静态路径:一般是指层次比较清晰,目录结构明确,不包含参数。这是爬虫最节省资源的方式。当然动态路径和静态路径爬取是一样的,但是既然是做SEO,就要遵守SEO规则。
3).伪静态路径:和路由的参数传递类似,是利用技术把动态路径转化为静态路径的一种形式,但本质上还是静态路径,比如/index/112.html
另外网站只允许设置一种路径,即全部动态路径或者静态路径,不允许同时使用两种路径,如果有第二个连接,必须屏蔽,也可以用.txt屏蔽。2.将路径名改为小写
3. 不能使用中文作为域名
爬虫根本无法识别这种路径格式,基本不会被抓取到,你可以用拼音或者英文。
4. 路径名和层级尽量短,如果之前包含的链接不再使用,可以用301重定向到新域名,这样会把这个网站的权重转移到另一个网站上。
所有跳转路径使用标签跳转,不使用事件跳转(如.push)
当爬虫爬取到一个网站后,会沿着a标签继续向下访问,如果写点击事件,使用路由跳转,爬虫就没法读取脚本,采集更多相关网站了。
TDK 中页面的更多描述
网站首页的标题是最重要的,直接影响整个网站的排名
技术型直男明星
就是对我们整个网站的核心关键词或者服务领域的浓缩和提炼,在设置首页标题T的时候尽量使用分词技术,百度会对标题进行合并分解,使用英文-_进行拆分,首页标题总字数不要超过30个汉字,否则可能会出现标题显示不全的情况。
首页标题怎么写:一般为‘网站名称-主要关键词或者包含关键词的描述’,一般将主要关键词放在最前面,因为搜索引擎给予标题中第一个字的排名高于后面的字。 专栏页标题怎么写:一般有‘专栏名称-网站名称’和‘专栏名称专栏关键词-网站名称’两种。比如企业招聘专栏,最好使用企业招聘,不要使用生僻的或者没有辨识度的名字,比如企业招聘、企业参观等,虽然个性化,但是对优化并不友好。 列表页标题怎么写:‘列表页名称-专栏名称-网站名称’。 文章详情页标题怎么写:标题有‘文章标题-网站名称’、‘内容标题-专栏名称’、‘内容标题-专栏名称-网站名称’三种,最后一种是最规范的,可以给用户很好的提示。
D 描述是网站关键词的集合
字数一般控制在150字以内,如果太长,则无法正常显示。百度移动搜索网站优化白皮书中关于网站优化的内容提到:百度并未承诺严格按照标题和摘要的内容展示标题和摘要,尤其是摘要。它会根据用户搜索的关键词,自动匹配并展示合适的摘要内容,让用户了解网页主要内容,影响用户的行为决策。(本段来自百度搜索资源平台)
K关键字设置\
首页怎么写:一般将首页的标题、关键词、一些特殊栏目内容整合到其中,写一个简单的介绍。 专栏页怎么写:一般将栏目标题、关键词、分类列表名整合到介绍中。 列表页怎么写:一般将列表标题和关键词整合到介绍中。 文章详情页怎么写:一般将文章标题和文章内容整合到介绍中。
主要作用是告诉搜索引擎这个页面的内容是围绕哪些词展开的。所以每个词在内容中都要能找到对应的匹配,方便排名。一般关键词不超过3个,每个关键词不宜过长,单词之间用英文“,”隔开。但各大搜索引擎对关键词堆砌已经打击很大,目前百度等搜索引擎已经不再查收录关键词,而主要是为了利用第三方工具查收录关键词的排名情况。比如我们用站长工具查询的时候,就需要加上。首页写法:一般为‘网站名称,主要栏目名称,主要关键词’。栏目页写法:一般为‘栏目名称,栏目关键词,栏目分类列表’。列表页写法:‘栏目主要关键词’。文章详情页写法:抽取一些文章关键词或者重复次数比较多的词,使用
:是HTML的属性值,它会存在于a标签和meta标签中,告诉爬虫不要跟踪这个页面上的链接或者不要跟踪这个链接,比如一些重要性不高或者一些不需要排名的链接。利用它可以使得爬虫增加重要链接的权重,便于集中网站权重,减少权重分散。
<meta name="robots" content="nofollow" />
<a href="www.XXX.com" rel="nofollow">a>
:是HTML中规范URL的属性值,比如有多个URL可以同时访问一个网页,那么我们用它来告诉爬虫这个网页的首选URL是哪个,这个指定的URL就是最有价值、最规范的网页。
<link href="canonical" href="http://www.XXX.com/newWebsite">
301 重定向
301是浏览器发送http请求时,服务器响应的一个状态码,代表页面已经永久移动了,又叫重定向,一般需要进行新旧网站的替换,比如将.php改成.html。这种情况下如果不做重定向,用户收藏夹或者搜索引擎数据库中的旧地址只会让来访的客户得到404页面错误信息,访问流量就白白流失了。使用301重定向,不仅可以让页面自动跳转,还可以告诉用户你换了新的网址,同时也告诉搜索引擎这是真实的网址,搜索引擎在重定向之后只会收录新的网址,同时会把旧地址的权重转移到新地址,这样网站的排名就不会因为网址变动而受到影响。
同时,当网站注册了多个域名,且内容重复时,就需要使用 301 让用户跳转到其中一个主域名,避免搜索引擎惩罚。当然 301 是服务端语言 IIS 实现的,纯前端技术无法实现,但是 Nuxt 将其作为中间层,在 Nuxt 执行环节的开始,也就是服务端,同样可以实现 301 跳转。
如果本文对您有帮助或启发,我将非常高兴。
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 