
.0主从模式配置流程
1.MySQL 集群配置
这里以20.04.2 + MySQL 8.0.23 进行主从模式的配置演示,并开启半同步复制,通过apt进行基础安装,安装完成并完成所有配置后进行虚拟机克隆(这里通过克隆的方式,在后面配置MySQL主从模式的时候需要修改数据目录下f文件中的UUID值,否则会导致从机同步失败,UUID相当于MySQL节点的身份证,不能重复,所以在文章开头特别强调)
1.1. 主从模式配置
这里我们使用1主2从,共3台机器,具体信息如下:
【-23】
PS:为了安全起见,可以将同步的账号改为自定义账号及权限,缩小权限范围。为了减少演示步骤,我们就不做账号创建、授权这些无关的步骤了,直接用root账号进行同步。
1.1.1. 启用账户访问权限
如果使用自建账号及授权,可以忽略此步,这里是开启root账号的内网访问权限。
步骤1:首先开启root账号的内网访问权限。
首先通过MySQL CLI登录数据库,并切换到MySQL数据库。
然后更新root账户的访问权限范围,并刷新权限信息。
user set host='你的内网IP' where user = 'root';
冲洗;
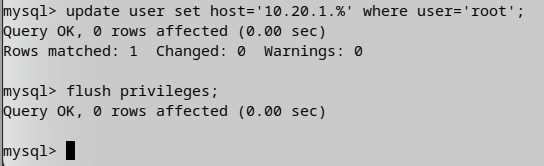
分别开启、slave三个MySQL账号的权限。
如果你是虚拟机镜像的从节点,请按照如下步骤在从库所在机器上修改f文件中的uuid,具体步骤如下:
vim /var/lib/mysql/f
(若当前账户不是root账户,无法访问该文件,请先su root,稍后再修改。)
然后或者百度生成一个uuid替换掉,然后保存就可以了。
然后重启mysql服务
mysql
1.1.2. 配置库
打开主库的f配置文件,写入如下配置;
打开配置文件:sudo vim /etc/mysql/f
写入配置:
[client]
# 配置远程端口(可选,不改就是3306)
port=15588
[mysqld]
# MySQL8.0的默认时区
default-time_zone='+8:00'
# 配置远程端口(可选,不改就是3306)
port=15588
# 默认binlog文件的名称(可自定义)
log_bin=mysql-bin
# 当前服务器的ID,不能重复,推荐用服务器IP D段
server-id=158
# 数据刷盘参数=1时,只要有1个事务提交就会触发写盘的操作,安全性最高,并发性最差
# 数据刷盘参数=0时,由文件系统控制写盘的频率,并发性能最好,但是意外丢失数据的风险最大,这里根据实际需求配置,不建议乱配。
sync_binlog=0
# 排除掉不需要同步的数据库列表
binlog-ignore-db=performance_schema
binlog-ignore-db=information_schema
binlog-ignore-db=sys
配置完成后,重启服务。
1.1.3. 配置从库
接下来开始配置从库数据,具体配置信息如下,不再赘述:
[client]
port=15588
[mysqld]
default-time_zone='+8:00'
port=15588
# 没台机器的ID都不同,根据自己实际情况修改
server-id=160
relay_log=mysql-relay-bin
read_only=1
至此,从库的基本配置已经准备好,现在我们要开始配置从节点信息。
1.1.4.启动主从库
首先进入库的cli控制台,输入以下信息:
展示 ;
请参阅以下信息:
记住前两栏的信息,下面配置从库时会用到它们。
然后进入Slave的cli控制台,输入以下信息:
mysql> 到 ='10.20.1.158',=15588,='root',='root',='mysql-bin.',=13404;
mysql>启动从属;
我们来检查一下从站的状态:
mysql>显示从属\G;
看到上面的信息就证明同步成功了,最重要的是看到and。其他节点配置成功之后也可以用同样的方法,如果此时主库的数据已经非常大,用POS来定位日志数据进行同步会非常慢。建议使用,直接把主库的数据sql脚本导出来,扔到从库里执行,速度会快很多。如果担心有数据的话,那么导出之前先检查一下当前的POS位置。等从库导入完主库的备份之后,再用上面的方法从最近的POS位置开始同步,防止你在同步的时候有新的数据产生,没有导入到从库。
1.2. 双活模式配置
什么是双主模式?简单来说就是有两台服务器,但是它们如何同步数据呢?那就是互相做从机。双主模式又分为多主多写模式、双主双写模式、双主单写模式。
1.2.1. 多主多写模式
意味着由两个以上的节点负责写入数据,这样可以大大提高数据库并发写入的性能。但是一旦数据库出现问题,处理问题数据就会很头疼。另外,多写数据库的ID值的起始位置和增量需要对多写主机总数取模得到增量间隔,否则它们之间生成的ID会发生冲突,所以一般不推荐使用这种方式。
1.2.2. 双主多写模式
它和多主多写类似,只是节点数限制为2个,并且互相之间的ID值起始位置为1和2,增量为2,这样两台机器生成的ID就是一个偶数,一个奇数。问题和多主多写一样,但是出现问题之后相对比多主多写更容易处理。在并发写入量要求不是那么极端的情况下使用,这里就不赘述了。
1.2.3. 双主机单写入器模式
该模式可以理解为对主库进行冗余备份,避免主库崩溃后服务直接不可用,这种方式可以提高MySQL集群的高可用性。而对于另外两种方式提供的并发写性能提升,可以利用Reids等技术手段变相提高写性能,达到类似的效果。这种方式在出现问题时数据处理相对简单,工作量相比另外两种方式要小很多,所以如果企业环境到了主从模式都不能满足需求的地步,可以优先考虑这种方式。
1.2.4. 推荐的使用模式
本文介绍的方法主要是双主单写模式,其他方法都是在此模式的基础上增加一个ID自增区间和ID起始位置的配置,然后加入到后面会提到的MySQL中的路由列表中即可实现。
1.2.5. 配置示例
接下来我们在主从模式的基础上增加双主单写模式的配置,与主从模式完全不冲突。
这里添加一个新的服务器节点为-2,将之前的(10.20.1.158)作为-1(以下简称-1),下面会通过-4和-1进行互相同步。
【-4】
IP:10.20.1.157(以下简称-2)
MySQL -2
使用同步的账号root
首先我们打开-1和-2的f配置文件,添加如下配置,两个节点的内容完全一样:
之后在两台机器上重启MySQL,登录MySQL控制台,先查看-1的状态。
-1 的状态:
-2 的状态:
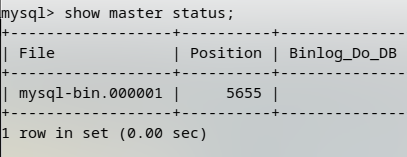
记录一下以上信息,后面会用到。然后把-1的数据库完整导出,在新建立的-2上恢复数据,保证要同步的数据库数据完全一致。(这个步骤前面已经提到过)这里就不截图了,到此为止,我假设你已经把-2上的数据同步到-1上了。
接下来,我们开始将 -1 和 -2 互相设置为节点。
在-1上执行以下语句:
mysql> 到 ='10.20.1.157',=15588,='root',='root',='mysql-bin.',=5655;
mysql>启动从属;
在-2上执行以下语句:
mysql> 到 ='10.20.1.158',=15588,='root',='root',='mysql-bin.',=4475;
mysql>启动从属;
至此配置完成,接下来检查两台设备的从机状态。
-1 从属状态:
-2 从属状态:
看到两个Yess就证明已经成功了。然后通过MMM架构方案,就可以实现自动切换,自动将从节点更换为新的。这一点内容太多,这里就不细说了,后面会单独开一篇文章详细讲解。
2. 启用半同步复制
半同步复制需要配置两个地方,分别是主库和从库,现在我们开始配置主库。
2.1. 配置主数据库
首先,我们需要为 MySQL 数据库安装 semi 插件。
mysql>'.so';
mysql> 显示类似'%semi%';
mysql> 设置 = 1;
mysql> 设置 = 1000;
检查安装结果,上面第三步是启用半插件,第四步是设置同步超时时间为1秒。
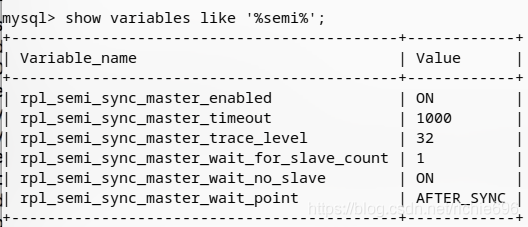
到此,主数据库的配置基本完成,下面我们开始配置从数据库。
2.2.配置从库
同样,安装从库的semi插件并启用,注意主库和从库的插件不一样,请仔细阅读。
mysql>'.so';
mysql> 设置 = 1;
查看安装结果。
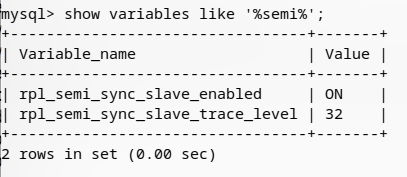
同理,按照同样的方式配置其他Slave节点。
配置完成后,重启从节点。
mysql>停止从属;
mysql>启动从属;
至此配置过程结束,现在可以测试同步效果了。
2.3. 如何处理主从不同步
当 MySQL 集群数据不同步时,MySQL 将停止同步。检查 Slave 状态将显示以下内容:
这种情况一般意味着从库发生了事务回滚,比如从库宕机或者在从节点上进行了写操作,导致主从不一致,对应节点会终止同步。这种情况下我们需要重新配置并同步节点,方法有很多,根据不同的情况使用不同的方法,具体如下:
2.3.1. 数据量小
记录主库最新的POS位置,然后从主库导出需要同步的数据库备份,并通过各种手段将备份从服务器A转移到服务器B,然后重新导入到Slave节点数据库中,重新指定新的位置,并从这个位置开始同步。
接下来我们来演示一下数据量较小的方案的运行流程。
首先检查状态
mysql>显示;
记录File的值然后:
这是一个shell命令,而不是mysql命令。
--all- > ~/.sql -uroot -p
这里导出的是所有的库,如果想指定某个库,可以通过–help查看帮助命令。
将导出的备份通过SFTP或者其他方式传输到有问题的节点,然后执行以下命令导入。
mysql> /home//.sql;
等待导入完成后,使用上面记录的文件重新指定同步信息,首先进入mysql cli,执行以下命令:
mysql>停止从属;
mysql>重置从属;
mysql> 到 ='10.20.1.158',=15588,='root',='root',='mysql-bin.',=16856;
mysql>启动从属;
执行完之后我们可以检查同步状态。
现在你可以看到这是OK的。
2.3.2. 大量数据
如果数据量很大,导入数据库的方法耗时太长,我们可以在导出的时候使用从出现问题到最新时间的SQL语句,然后将导出的SQL信息传输到从节点执行,同步到当前时间节点,恢复未同步的数据,然后重新指定新的位置,从这个位置开始同步。
所有步骤和数据量小的方案类似,唯一不同的是导出数据库的时候不是导出整个数据库,而是导出指定时间段的SQL语句,然后扔到有问题的slave上去恢复,导出命令如下:
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 