
基本票据数据的输入输出
print("数据") # 这是数据的输出
name = input() # 这是数据的输入,并将输入的数据赋值给name。而且无论输入的何种类型的数据,最终的结果都是 字符串 类型的数据
pint 输出不带换行符:
# print 输出会自动换行
print('hello', end='')
print('hello', end='')
# 加上end='' 即可输出不换行
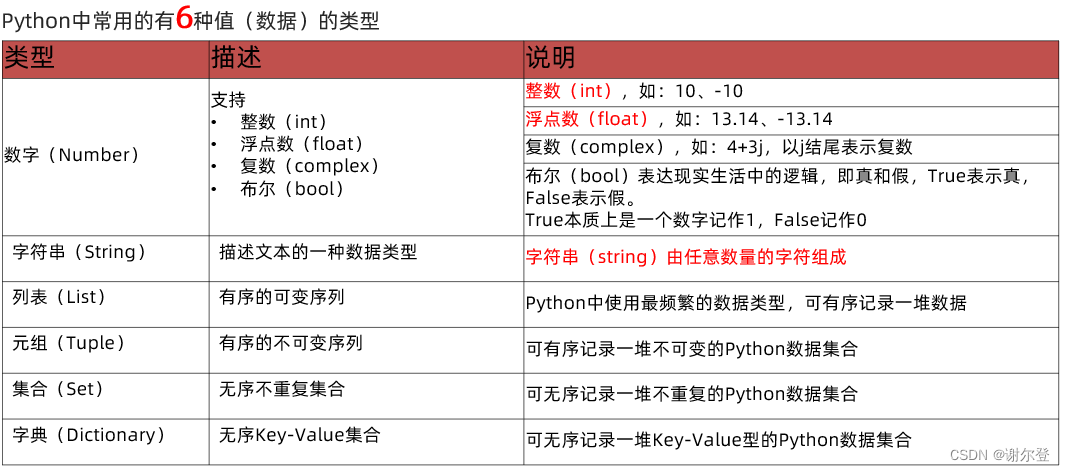
数据类型
类型(正在查看的数据类型)-> 验证数据类型
字符串字符串定义
text1 = '我是字符串'
test2 = "我也是字符串"
test3 = """我即是字符串,还能做注释"""
字符串中的嵌套引号
字符串本身包含引号、双引号:
字符串连接
字符串直接用+连接,字符串不能与非字符串连接。
字符串格式化
price = '9.15'
cloth = 'shirt'
message = 'the price of the %s is %f' % (cloth, price)
print(message)
%表示占位符,s表示将变量转换为字符串放入占位符中,d表示将内容转换为整数放入占位符中,f表示将内容转换为浮点数放入占位符中
price = '9.15'
cloth = 'shirt'
print(f'the price of the {cloth} is {price}')
注意:这种写法不控制精度,也不关心类型。
格式化表达式
print("1 + 1 的结果是:%d" % (1 + 1))
print(f"1 + 1 的结果是:{1 + 1}")
格式化精度控制数据类型转换 None 类型
应用:
笔记
# 我是单行注释
"""
我是多行注释
"""
运算符 算术运算符
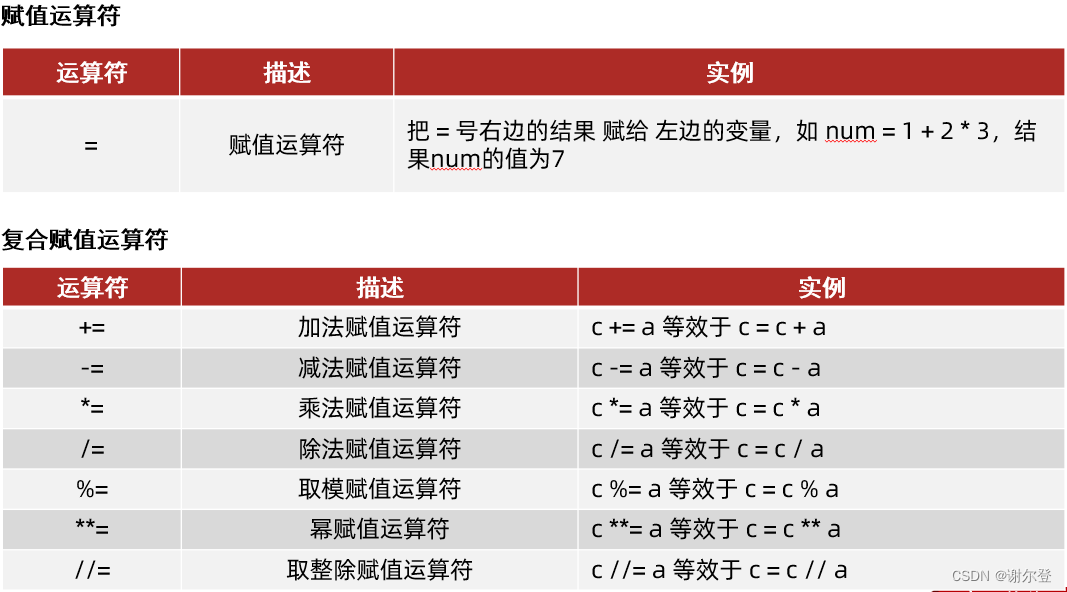
赋值运算符
法官判刑
age = 10
if age < 18:
print('我要学习')
elif age < 25:
print('我要谈恋爱')
else:
print('我要挣钱养家')
# 当需要判断多个条件
# if x > 0 and y > 0
# if x > 0 or y > 0
循环语句 while 循环
j = 0
while j < 5:
print('循环print')
j += 1
# 循环 n 次
for i in range(n):
# 遍历文件 f 的每一行
for line in f:
# 遍历字符串
for c in s:
# 遍历列表 ls
for item in ls
# 扩展模式(else语句只在循环正常执行并结束后才会执行,比如中间break就不会执行else),while 同理
for s in "BIT":
print("循环进行中: "+s);
else:
s = "循环正常结束"
print(s)
for 循环
name = "kun"
for x in name
print(x) # 会遍历输出字符串的每个字符
for i in range(5)
print(i) # 循环遍历range序列
range 语句
range(num) # 获取一个从 0 开始,到 num (不含num)结束的数字序列
range(num1, num2) # 获取一个从 num1 开始,到 num2 (不含num2)结束的数字序列
range(num1, num2, step) # 获取一个从 num1 开始,到 num2 (不含num2)结束的数字序列,step为步长
# 如 range(5, 10, 2) -> [5, 7, 9]
并破坏函数定义
# 函数定义
def 函数名(传入参数):
函数体
return 返回值
# 函数调用
函数名(参数)
f = lambda x, y : x + y
print(f(1, 2)) # 3
def fn1(num, str2 = "str2"):
print(num*str2)
fn1(2) # str2str2
# 可选参数必须定义在非可选参数的后面
# 带 * 表示可变数量参数,只能出现在参数列表的最后
def fun(a, *b) :
print(type(b))
for n in b:
a += n
print(a)
fun(1,2,3,4,5) # 15
def fn(num, str2):
print(num*str2)
fn(str2 = 2, num = "str22")
def func1(a,b):
return a,b
result = func1(1,2)
print(result, type(result)) # (1, 2) 笔记:
# 找出以下代码中的问题:
x = 50
def func():
print(x)
x = 100
func()
# 在函数内部,当我们对变量进行赋值时,Python会将其视为一个局部变量,并覆盖同名的全局变量。因此,在函数func中,对x赋值后,会创建一个新的局部变量x,并将其值设置为100。然而,在print(x)这一行尝试访问x时,由于该局部变量尚未被赋值,Python将抛出一个UnboundLocalError异常。
# 为了解决这个问题,你可以在函数内部通过global关键字来声明对全局变量进行操作,即将x声明为全局变量。
# 在函数内部使用global关键字时,只能用于声明对全局变量进行操作,而不能用于直接定义全局变量。
关键词
num = 100
def testA():
print(num)
def testB():
# global 关键字在函数内部声明变量为全局变量
global num
num = 200
print(num)
testA() # 100
testB() # 200
print(f'num = {num}') # num = 200
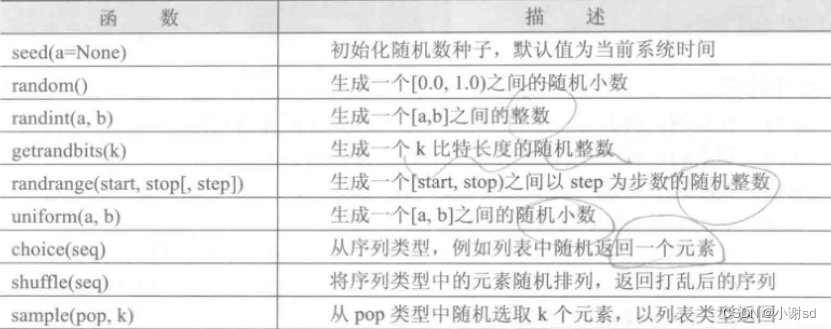
随机数
# 引用
from random import *
# 或者 import random
num = random.randint(1, 100) # 生成 1~100 之间的随机数,包括 1 和 100
# 随机数种子是一个整数,种子相同,每次生成的随机数也相同。
数据容器分类列表(list)
变量名 = [元素1,元素2,…]
这些元素数据可以是不同的数据类型
索引:1.从前到后0~n 2.从后到前-1~-n
列表的常见操作(方法) 遍历列表
# while 循环
index = 0
while index < len(列表):
print('列表[index]')
index += 1
# for 循环
for i in 列表:
print(i) # 每一个循环将列表中的元素取出,赋值给 i
元组
# 元组一旦定义完成,就不可修改内容
# 定义元组 当只有一个元素,要在后面加`,`
变量名称 = (元素, 元素, ...)
# 定义空元祖
变量名称 = () # 方式一
变量名称 = tuple() # 方式二
# 但是可以修改里面的list的内容,不可以替换list为其他的list或其他类型
t1 = (1, 2, ['kun', 'c'])
t1[2][1] = 'cc' # 正确
t1[2] = [1, 2, 3] # 错误
元组相关操作

str (字符串)
每一个字符也可以通过下标来访问,字符串是不能被修改的,对它的操作只会生成一个新的字符串,原字符串保持不变。
字符串的常见操作 len():返回字符串的长度(字符数)。 lower() 和 upper():分别将字符串中的字符转换为小写或大写。 strip()、() 和 ():从字符串的两端或指定侧删除空格或其他指定字符。 split():使用指定的分隔符将字符串拆分为列表。 join():使用指定的连接运算符将列表的元素连接成字符串。 ():替换字符串中的指定字符或子字符串。 () 和 ():确定字符串是否以指定的前缀或后缀开头或结尾。 ()、()、()、() 等:检查字符串是否仅包含字母、数字、字母和数字的组合或空格。 find() 和 index():在字符串中查找指定的子字符串并返回其第一次出现的位置。 count():计算指定子字符串在字符串中出现的次数。 () 和 ():检查字符串是否仅由数字组成。 ():将字符串的首字母大写。 ():交换字符串中字母的大小写。
# 查 - 字符串.index(字符串1) 查找某段字符1的首字符索引
# 替换 - 字符串.replace(字符串1, 字符串2) 将字符串1的内容替换为字符串2,得到一个新的字符串
# 分割 - 字符串.split(分割字符串的符号) 得到一个新的列表对象
# 规整 - 字符串.strip() 去掉前后的空格
# - 字符串.strip(字符串1) 去掉前后指定字符(串1)
# 统计次数 - 字符串.count(字符串1)
数据容器的切片(序列)
序列:一种数据容器,其内容是连续且有序的,可以使用下标进行索引。例如:列表、元组、字符串……
# 切片:从一个序列中取出一个子序列,得到新的序列
# 序列[起始下标:结束下标:步长]
# 起始下标留空视为从头开始,结束下标留空视为截取到结尾,步长是负数为反向截取,截取元素不含结束下标
放
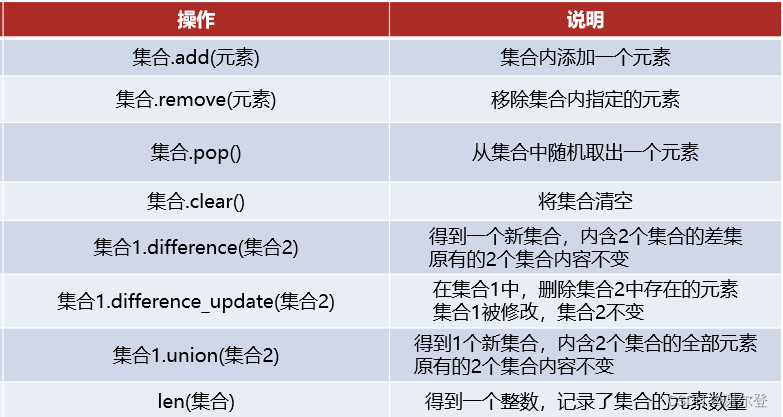
定义一个集合变量名 = {元素,元素,…} 空集合 -> 变量名 = set()
与列表和元组不同,集合是无序的,不允许重复元素。集合对象在遍历时不保证元素的顺序,这导致无法遍历集合。
常用函数合集
dict (字典,映射)
# 定义字典变量
my_dict = {key1: value1, key2: value2, ...}
# 定义空字典
my_dict1 = {}
my_dict2 = dict()
# 获取value
my_dict["key1"] # value1
常见字典操作
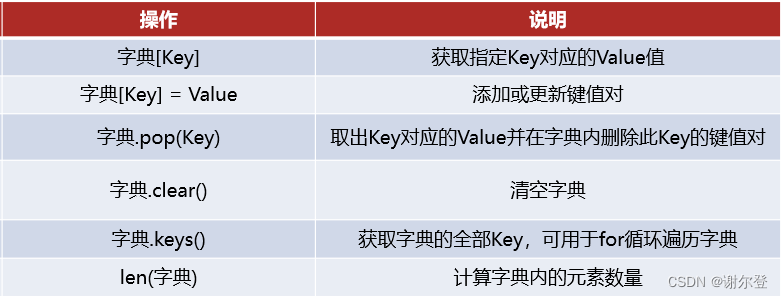
# 遍历字典
stu_score = {
'a': 23,
'b': 34
}
keys = stu_score.keys()
for key in keys:
print(f"学生:{key}, 分数:{stu_score[key]}")
数据容器的常用函数统计函数len():统计容器中元素的个数max():统计容器中最大的元素min():统计容器中最小的元素转换函数list() - 将给定的容器转换为列表str() - 将给定的容器转换为字符串tuple() - 将给定的容器转换为元组set() - 将给定的容器转换为集合排序函数
(, [=True]) - 排序后会得到一个列表对象 - =True 表示降序
函数高级函数多个返回值
def test_return():
return 1, 2
x, y = test_return()
print(x) # 1
print(y) # 2
函数多参数传递方法位置参数
传递的参数的顺序和位置个数必须与定义的参数一致
def user_info(name, age):
print(f'your name is {name}, age id {age}')
user_info('kun', 20)
关键字参数
调用函数时,如果有位置参数,则位置参数必须位于关键字参数之前,并且按照一定的顺序排列;关键字参数之间没有顺序要求。
def user_info(name, nickname, age, gender):
print(f"your name is {name}, nickname is {nickname}, age is {age}, gender is {gender}")
user_info("kun", "kunkun", gender="male", age=20)
默认参数
为参数提供默认值,调用函数时不需要传递默认参数的值(所有位置参数都必须出现在默认参数之前,包括函数定义和调用)
变长参数(可变参数)
仓位转移
def user_info(*args):
print(args)
user_info('kun', 20)
# 传递的所有参数都会被args变量收集,然后合并成一个元组
关键字传递
def user_info(**kwargs):
print(kwargs)
user_info(name="kun", age=18, id=100)
# 参数是键值对的形式下,kwargs会根据键值对组成字典
匿名函数作为参数传递
def test_func(compute):
result = compute(1, 2)
print(result)
def compute(x, y):
return x + y
匿名函数
关键字定义匿名函数,暂时只能使用一次
def test_func(compute):
result = compute(1, 2)
print(result)
test_func(lambda x, y: x + y) # result = 3
文件操作 文件读取 open() open函数
# open(name, mode, encoding)
# name:要打开的目标文件名的字符串(可以包含文件所在的具体路径)
# mode:设置打开文件的模式(访问模式):只读,写入,追加等
# encoding:编码格式(推荐使用UTF-8)
f = open("C:/python.txt", 'r', encoding="UTF-8")
# 这个函数实际上有很多参数,encoding并不在第三位,所以不能用位置参数,要用关键字参数直接指定
# f 这里是文件对象,拥有属性和方法
模式 三种常见的基本访问模式

操作摘要
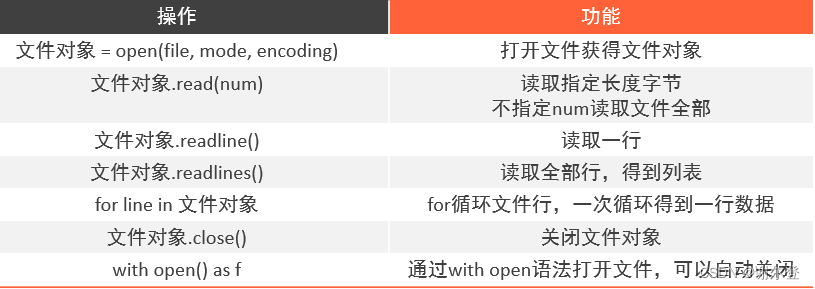
写入文件
f = open('python.txt', 'w')
# 文件如果存在,'w'模式将原有内容清空;如果不存在,创建新文件
f.write("hello world")
# 内容刷新
f.flush()
# 直接调用write,内容写到内存(缓冲区),未写入文件;flush调用时,写入文件
追加文件
f = open('python.txt', 'a')
# 文件如果存在,'a'模式将追加写入;如果不存在,创建新文件
f.write("hello world")
f.flush()
异常、模块和包异常
# 捕获常规异常
try:
可能发生错误的代码
except:
如果出现异常,则改为该代码执行
# 捕获指定异常
try:
print(name)
# NameError 捕获到输入类型错误 或者 写成:except NameError:
except NameError as e:
print("name 变量名称为定义错误") # 直接print(e) 则会输出描述信息
# 如果尝试执行的代码(print(name))的异常类型和要捕获的异常类型(NameError)不一致,则无法捕获异常,其中 e 可以是任意别名
# 一般try下方只放一行尝试执行的代码
# 捕获多个异常
try:
print(1/0)
except(NameError, ZeroDivisionError): # 要捕获异常类型的名字,用元组的方式书写
print("ZeroDivision错误...")
# 捕获所有异常
try:
print(name)
except Exception as e:
print(e)
# 没有异常时, 还会执行的代码
try:
print(1)
except Exception as e:
print(e)
# else 当 try 中语句块正常执行且没有发生异常时会执行
else:
print("我是else,是没有异常时还会执行的代码")
# 无论是否有异常时都会执行的代码
try:
f = open("test.txt", 'r')
except Exception as e:
f = open("test.txt", 'w')
else:
print("没有异常")
finally:
f.close() # 无论是否有异常时都会执行的代码
# 异常具有传递性,故可以在main()函数中设置捕获异常,确保所有异常都会被捕获
模块模块导入
# [from 模块名] import [模块 | 类 | 变量 | 函数 | *] [as 别名]
# 导入模块
# import 模块名1,模块名2...
import time
print("start")
time.sleep(1) # 让程序睡眠1s(阻塞)
print("end")
# from time import sleep 导入时间模块中的sleep方法
# 直接 sleep(1) 即可
# from time import * 导入时间模块中的所有方法
自定义模块

测试模块:
# my_module1.py
def test(a, b):
print(a + b)
test(1, 1) # 测试代码
# 为解决 不论是当前文件还是其他已经导入该模块的文件,运行时都会自动执行`test`函数的调用 的问题
# my_module1.py
def test(a, b):
print(a + b)
# 只有在当前文件中调用该函数,其他导入的文件内不符合该条件,则不执行test函数调用
if__name__ == '__main__':
test(1, 1) # 测试代码
# 当导入多个模块时,且模块内有同名功能,调用到的是最后导入的模块的功能
# 如果一个模块文件中有`__all__`变量,当使用`from xx import *`导入时,只能导入这个列表中的元素 例:`__all__ = {'test_A'}` -> 只能导入`test_A`函数
套餐定制套餐
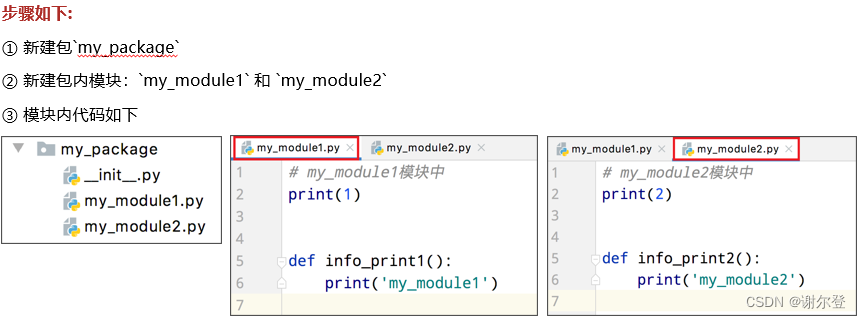
导入方法:
包名.模块名.方法名 在.py文件中添加 = [] 来控制允许导入的模块列表。 安装第三方包。 打开命令提示符输入pip 包名,或者通过国内清华镜像网站安装,输入pip -i 包名。 通过面向对象的类和对象安装第三方包。
# 设计类
class Student:
name = None # 类的属性,成员变量
def say_hi(self, msg): # 类的行为,成员方法,self必须填写
print(f"hi~,我是{self.name},{msg}")
# 创建类对象
stu = Student()
# 对象属性赋值,调用成员方法
stu.name = "kun"
stu.say_hi("很高兴认识大家") # seld代表类自身,传参时只看后面的参数
施工方法
使用类中的方法将成为构造函数
class Student:
name = None
age = None
def __init__(self, name, age):
self.name = name
self.age = age
stu = Student("kun", 28)
其他内置方法
在 中,所有被双下划线 __ 包裹的方法统称为 Magic 方法。它是一种特殊的方法,普通方法需要调用,而魔法方法不需要调用就能自动执行。
字符串方法
当需要将类对象转换为字符串时,会输出内存地址(print())。此方法可用于控制类转换为字符串的行为。
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return f"Student类对象,name={self.name},age={self.age}"
student = Student("kun", 29)
print(student) # Student类对象,name=kun,age=29
小于号比较法
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __lt__(self, other):
return self.age < other.age
stu1 = Student("kun", 11)
stu2 = Student("kunkun", 13)
print(stu1 < stu2) # True
# 大于比较符号是`__gt__`
小于或等于比较符号
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __le__(self, other):
return self.age <= other.age
stu1 = Student("kun", 11)
stu2 = Student("kunkun", 13)
print(stu1 <= stu2) # True
# 大于比较符号是`__ge__`
比较运算符的实现方法
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __eq__(self, other):
return self.age == other.age
stu1 = Student("kun", 11)
stu2 = Student("kunkun", 11)
print(stu1 == stu2) # True
# 不使用`__eq__`比较的是内存地址
封装
封装:定义类,描述属性和方法。
私有成员
如果变量或方法名以__开头,则为私有成员变量或私有成员方法。私有方法不能被类对象直接使用,私有变量也不能被类对象赋值或获取值。但是类中的其他成员可以访问私有成员。
继承 单继承和多继承
# 单继承
class Phone:
producer = None
def call_by_4g(self):
print('4g通话')
class Phone2023(Phone):
face_id = True
def call_by_5g(self):
print('5g通话')
# 多继承
# class 类名(父类1,父类2,...): # 同名继承,左边的父类优先级更高
# 类内容体 # pass关键字是占位语句,表示类定义完整,但无内容
复制
class Phone:
producer = "MI"
def call_by_5g(self):
print('父类5g通话')
class Phone2023(Phone):
producer = "GUO" # 复写父类属性
def call_by_5g(self):
print('子类5g通话') # 复写父类方法
#方式1调用父类成员
print(f"父类的producer是:{Pyone.producer}")
Phone.call_by_5g(self)
#方式2调用父类成员
print(f"父类的producer是:{super().producer}")
super().call_by_5g()
phone = Phone2023()
phone.call_by_5g() # 通过子类调用复写后的方法 和 调用父类原成员
# 一旦复写父类成员,那么类对象调用成员时,就会调用复写后的新成员。如需使用被复写的父类的成员,只能在子类内调用父类原有的的同名成员,子类的类对象直接调用会调用子类复写的成员
类型注解
类型注解只是给开发者的一个提示,并不具有决定性。
# 变量的类型注解
var_1: int = 10
class Student:
pass
stu: Student = Student()
my_list: list = [1, 2, 3]
my_tuple: tuple[str, int bool] = ("kun", 23, True)
# 如果将元组设置类型详细注解,需要将每一个元素标记出来
# 字典设置类型详细注解,需要2个类型,key和value
# 除了 变量: 这种方式,还可以在注释中进行类型注解
class Student:
pass
var_1 = random.randint(1, 20) # type: int
var_2 = json.loads(data) # type: dict[str, int]
var_3 = func() # type: Student
def add(x: int, y: int) -> int:
return x + y
# Union类型
from typing import Union
my_list: list[Union(int, str)] = [1, 2, 'kun']
my_dict: dict[str, Union[str, int]] = {"name": "kun", "age": 32}
def func(data: Union[int, str]) -> Union[int, str]:
pass
多态性
当完成某种行为时,不同的对象会获得不同的状态
class Animal:
def speak(self): # 抽象类(接口):含有抽象方法
pass # 抽象方法:方法体是空实现
class Dog(Animal):
def speak(self):
print("wang")
class Cat(Animal):
def speak(self):
print("miao")
def make_noise(animal: Animal):
animal.speak()
dog = Dog()
cat = Cat()
make_noise(dog) # wang
make_noise(cat) # miao
扫一扫在手机端查看
-
Tags : python代表输出数据的字符串
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 