
2.从服务器()获取一些客户端无法获取的信息,比如访问者IP等。
3.按照格式将信息写入日志中。
4、生成一张1×1的空gif图片作为响应内容,并设置响应头的-type为image/gif。
5.通过Set-在响应头中设置一些必需的信息。
这样设置的原因是如果要跟踪唯一访客,通常的做法是如果发现客户端请求时没有指定跟踪,就根据规则生成一个全局唯一的,并植入给用户,否则将获取到的跟踪放在Set-中,保持同一个用户不变(见图4)。

虽然这个方法并不完美(比如某个用户清空或者换了浏览器,都会被算成两个用户),但目前是比较常用的方法。注意,如果不需要跨站追踪同一个用户,可以用js种到被统计站点的域名下(GA就是这么做的)。如果想全网统一定位,可以用后端脚本种到服务器域名下(后面实现的时候会这么做)。
系统设计与实现
基于以上原则,我构建了一个访问日志收集系统。总体来说,构建这个系统需要做以下几件事:
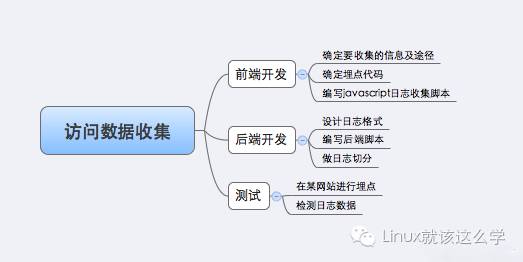
下面详细描述了每个步骤的实现。我把这个称为系统。
确定收集哪些信息
为了简单起见,我不会实现 GA 的完整数据收集模型,而是收集以下信息。
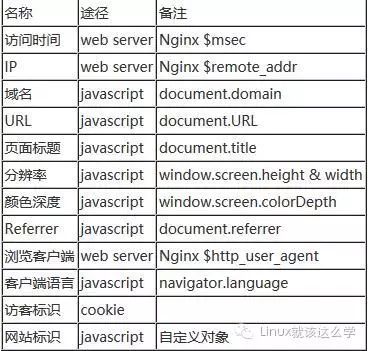
隐藏的代码
我将使用 GA 模型进行跟踪代码,但不会将配置对象用作 FIFO 队列。跟踪代码模板如下:
//
这里我已经开启了二级域名,统计脚本的名字是ma.js。当然这里有个小问题,因为我没有https的服务器,所以如果https的站点部署代码的话就会有问题,不过这里先不管了。
前端统计脚本
我写了一个统计脚本ma.js,虽然不是很完善,但是可以完成基本的工作:
((){
var = {};
//对象数据
如果() {
. = . || '';
.url = .URL ||'';
.标题 = .标题 ||'';
. = . || '';
//对象数据
如果( && 。) {
.sh = .. || 0;
.sw = ..宽度 || 0;
.cd = .. || 0;
//对象数据
如果() {
.lang = . || '';
//配置
如果(_maq){
对于(var i 在 _maq 中){
(_maq[i][0]){
案件 '':
.= _maq[i][1];
休息;
:
休息;
//连接参数字符串
var args = '';
对于(var i in ){
如果(参数!=''){
参数 += '&';
参数 += i + '=' + ([i]);
//通过Image对象请求后端脚本
var img = 新图像(1,1);
img.src = '#39; + 参数;
})();
整个脚本放在一个匿名函数中,保证不污染全局环境,该函数在原理部分已经讲解,这里不再赘述。1.gif为后端脚本。
日志格式
日志采用每行一条记录的方式,使用不可见字符^A(ascii码0x01,在Linux下可以使用ctrl+v ctrl+a输入,下面使用“^A”来表示不可见字符0x01)。具体格式如下:
时间^AIP^A域名^AURL^A页面标题^^A高分辨率^A宽分辨率^A色彩深度^A语言^A客户信息^A用户ID^A网站ID
后端脚本
为了简单和高效,我打算直接使用nginx来收集日志,但是有个问题就是nginx配置本身的逻辑表达能力有限,所以选择了这么做。它是一个基于Nginx扩展的高性能应用开发平台,内部集成了很多好用的模块,它的核心是通过模块的方式集成Lua,这样就可以在nginx配置文件中使用Lua来表达业务了。这里就不详细介绍这个平台了,有兴趣的同学可以参考它的官网,或者这里是它的作者张亦春()做的一个很有爱的介绍幻灯片,大家可以参考一下:。
首先需要在nginx配置文件中定义日志格式:
勾选“$msec^A$^A$^A$u_url^A$^A$^A$u_sh^A$u_sw^A$u_cd^A$^A$^A$^A$”;
注意,以u_开头的变量是我们后面要定义的变量,其他的都是nginx内置变量。
接下来是两个核心的:
/1.gif {
#伪装成gif文件
图像/gif;
#关闭自身,通过记录日志
离开;
“
-- 用户跟踪名称
本地 uid = ngx.var.
如果不是 uid 那么
-- 若不存在,则生成trace,算法为md5(时间戳+IP+客户端信息)
uid = ngx.md5(ngx.now() .. ngx.var. .. ngx.var.)
结尾
ngx.['Set-'] = {'='..uid..';path=/'}
如果 ngx.var.then
-- 通过登录 /i-log,带来参数和用户跟踪
ngx..('/i-log?'.. ngx.var.args..'&='.. uid)
结尾
“;
#此请求未缓存
“1980 年 1 月 1 日星期五 00:00:00 GMT”;
“无缓存”;
缓存-“no-cache,max-age=0,must-”;
#返回一个 1×1 的空 gif 图像
;
/i-日志 {
#,不允许外部直接访问
;
#设置变量,注意需要
$ $;
$u_url$;
$ $;
$ $;
$u_sh$;
$u_sw$;
$u_cd$;
$ $;
$ $;
$ $;
#打开日志
在;
#记录日志到ma.log中,实际应用中最好加上tick的格式
/路径/到/日志//ma.log勾选;
# 输出一个空字符串
回声'';
完整解释这个脚本的每一个细节有点超出本文的范畴,而且用到了很多第三方的 ngxin 模块(代码里都包含了),所以我把重点都用注释标注出来了。你不需要完全理解每一行的含义,只要知道这个配置完成了我们在原理部分提到的后端逻辑就行了。
日志轮换
实际的日志收集系统中会存在大量的访问日志,时间长了文件会变得非常大,放在一个文件中管理起来很不方便。所以日志一般会按照时间段划分,比如每天一条或者每小时一条。为了效果比较明显,我这里是每小时划分一条。我通过在固定时间调用shell脚本来实现的,shell脚本如下:
=“/路径/到/nginx”
时间=`日期+%Y%m%d%H`
mv ${}/logs/ma.log ${}/logs/ma/ma-${time}.log
kill -USR1 `cat ${}/logs/nginx.pid`
该脚本将ma.log移动到指定文件夹,并将其重命名为ma-{}.log,然后向nginx发送USR1信号以重新打开日志文件。
然后在/etc/中添加一行:
59 * * * * 根 /路径/到//.sh
每小时59分启动此脚本,执行日志轮换。
测试
现在我们可以测试一下系统是否可以正常运行了,相关点我昨天埋在了我的博客里,通过抓取http包可以看到ma.js和1.gif已经被正确请求了:
同时可以看一下1.gif的请求参数:
相关信息确实也放在了请求参数中。
然后我tail了日志文件,刷新了页面,由于我没有设置日志,所以立刻就得到了新的日志:
.360^A0.0.0.0^A^A^^A^A1024^A1280^A24^Azh-CN^/5.0(;Intel Mac OS X)/537.4(KHTML,如 Gecko)/22.0.1229.94 /537.4^^AU-1-1
注意,原日志中的^A其实是不可见的,这里我将其替换为可见的^A,方便阅读。另外,出于隐私问题,我将IP替换为0.0.0.0。
看一下日志轮转目录,由于之前已经埋了一些点,所以生成了很多轮转文件:
关于分析
通过上面的分析和开发,我们大概明白了一个网站统计的日志收集系统是怎么工作的了,有了这些日志,我们就可以进行后续的分析了,本文只关注日志收集,就不写太多分析了。
注意最好是尽可能的保留原始日志中的信息,而不要进行过多的过滤和处理。比如上面保留的是毫秒时间戳,而不是格式化的时间。时间格式化是后续系统做的,而不是日志采集系统的责任。后续系统可以根据原始日志分析出很多东西,比如可以通过IP库定位到访客所在地区,从user agent中获取访客的操作系统、浏览器等信息。结合复杂的分析模型,可以进行流量、来源、访客、地区、路径等分析。当然原始日志一般不会直接分析,而是会进行清洗格式化后传输到其他地方,比如MySQL或者HBase等进行进一步分析。
有很多开源的基础架构可以用来做分析,比如 Storm 可以做实时分析, 可以做离线分析。当然如果日志比较少,也可以通过 shell 命令做一些简单的分析。比如下面三个命令分别可以获取我博客今天早上 8 点到 9 点的访问量(PV)、访客数量(UV)、唯一 IP 地址数量(IP):
awk -F^A'{打印$1}'ma-.log|wc -l
awk -F^A'{打印$12}'ma-.log|uniq|wc-l
awk -F^A'{打印$2}'ma-.log|uniq|wc-l
朋友们可以慢慢探索其他有趣的事情。
非常感谢大家对社区的持续关注,相信我们会持续为大家提供更多有价值的开源资讯,让您快速掌握最新的行业动态。
如果你在学习本书的过程中,遇到什么问题,都可以扫描二维码添加刘老师为好友,向刘老师提问,与刘老师互动,快速解决你的疑惑!
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 