
点击上方“爬虫与数据挖掘”关注
回复“书籍”即可获得从初级到高级的 10 本电子书
现在
天
鸡
汤
清晨五点钟雨即将停,树绿无情。
大家好,我是先进。
1. 简介
前几天【明】在白银交流群里问了一个关于处理HTML的问题,如下图所示。
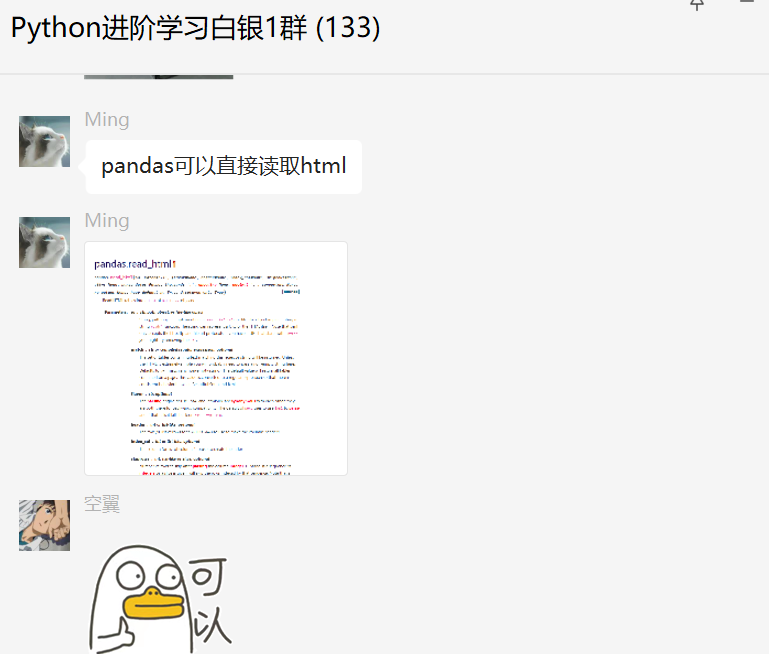
其实,这并不是一个问题,而是一种交流。

确实,HTML是可以直接读取的,在阅读网页的时候比较方便。
2.实施过程
这里我们一起讨论,学习了如何直接读取HTML。
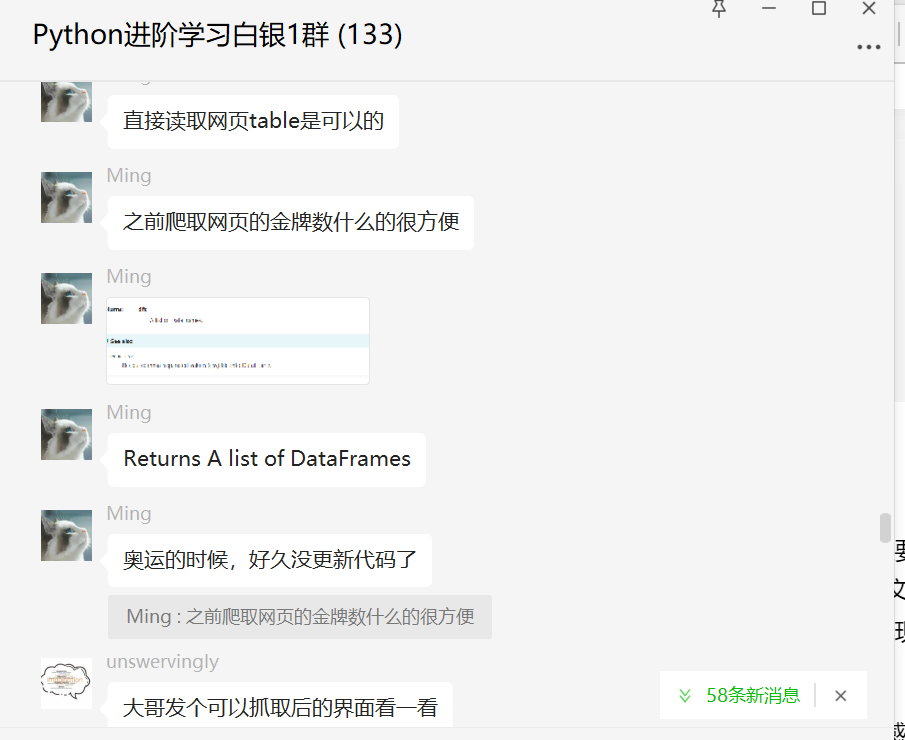
后来[null]给出了示例代码,真是雪中送炭。
只需三行简单的代码即可抓取网页数据并将其保存在表格中。对于表格格式的网页,您不再需要逐个检索 tr 和 td 标签,您可以全部获取。

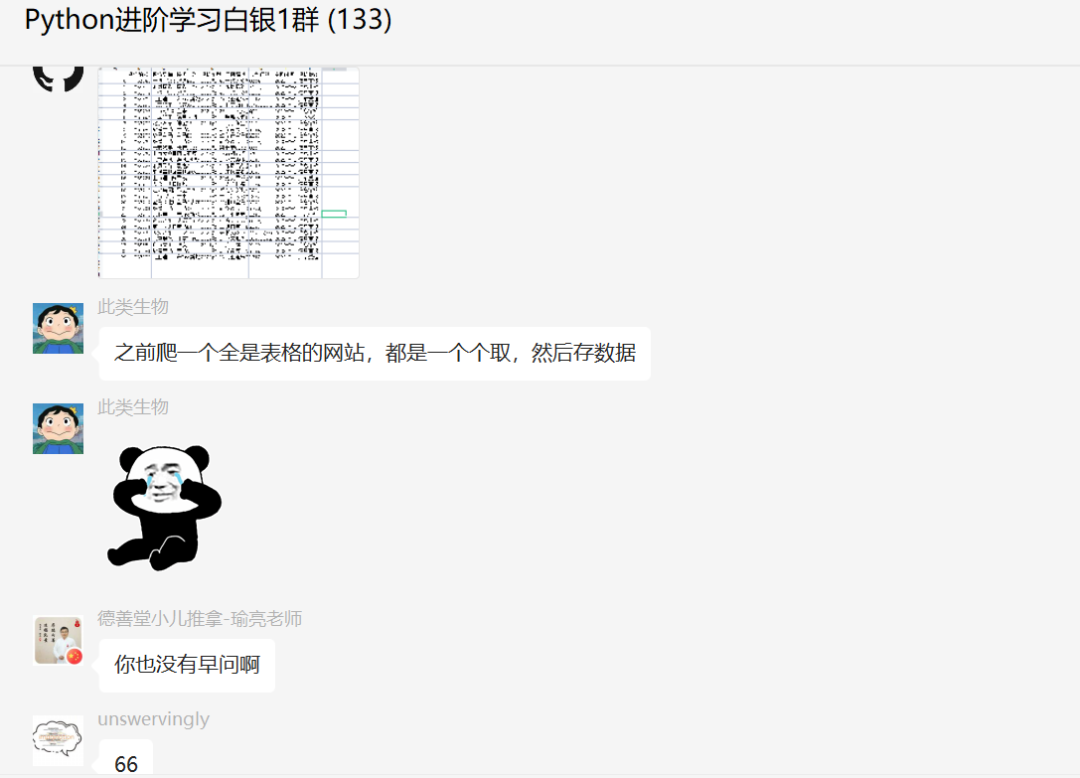
后来发现我们都是湖北警察同乡,互相聊了起来,一起学习更有意思!后来[null]又做了更多的扩展,爬取ajax加载的json格式也可以用来实现,这里也给出了一个例子。
结果如下图所示:
后来,[Luna]还提供了一个扩展,允许捕获csv格式。
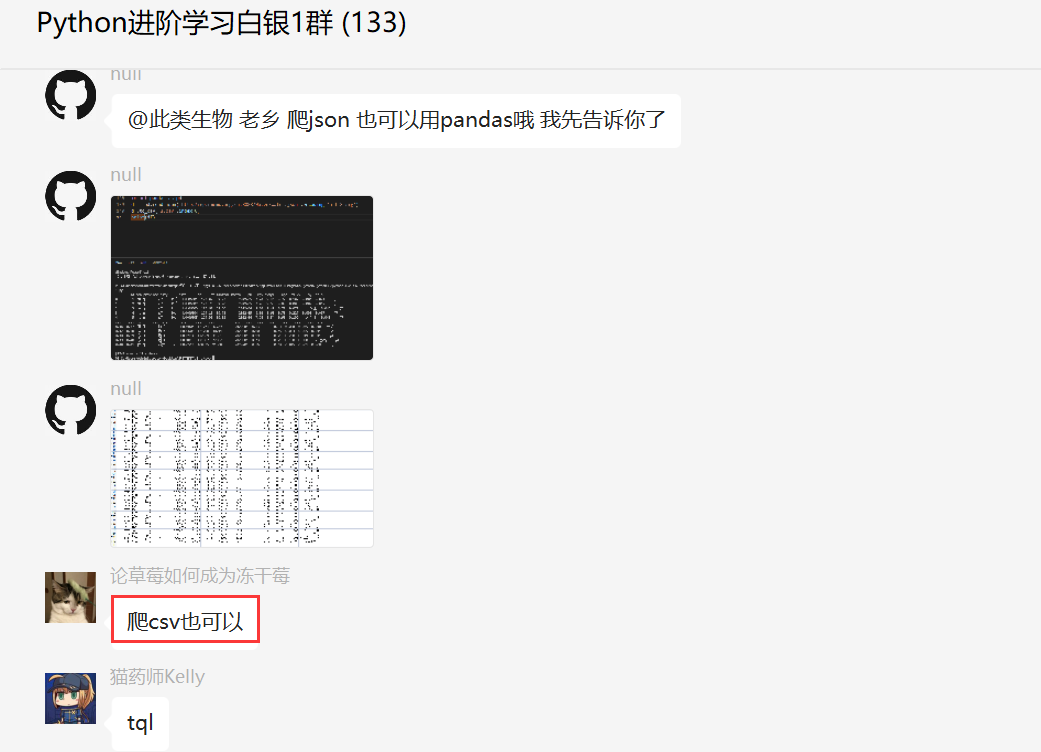
不得不承认,真的很厉害啊!
结论
大家好,我是皮皮,本文主要回顾一个处理网络爬虫的题目,文章针对该题目给出了具体的分析和代码实现,帮助粉丝们顺利解决问题。
最后感谢粉丝[Ming]的提问,[null]和[Yue Shen]的思路和代码分析,以及[孔毅]、[ ]、[这种生物]、[ ]、[俞良老师]、[××]、[猫药师Kelly]、[冫马讠成]等人的参与学习和交流。
小伙伴们赶紧实践起来吧!学习过程中遇到任何问题,欢迎加我为好友,我会邀请你们加入学习交流群,一起讨论学习。
扫一扫在手机端查看
本文链接:https://by928.com/5768.html 转载请注明出处和本文链接!请遵守
《网站协议》
!
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 