
1. 简单地抓取网页
这里以爬取易文妍的《二十五史》为例,一共 176 篇。
代码如下:
import requests #导入我们需要的库
def GetName(url): #定义一个函数并且传入参数Url
resp=requests.get(url);#//获取网页上的所有信息,以文本的模型返回
resp.encoding = 'GBK'
return resp.text;#//定义一个字符串也就是我们要爬取的地址
def xieru():
fi=open('E:/transformer/wenyanwen/25shi/'+str(a)+'.txt',"wb+");#打开一个文本,以写入的方式写入二级制文本
con = GetName(url);
ss=con.encode('utf-8')#返还的文本转换编码格式
fi.write(ss);#写入打开的文本中
return 0;
for a in range(1,177):
url="http://www.ewenyan.com/articles/esws/"+str(a)+".html";
xieru();
注意:
如果爬取过程中出现编码错误,可以先检查网页的编码方式(鼠标右键 – 查看源文件),如下图所示。
这里的编码是代码改为 GBK。
结果如下:
2. 字符替换
由于 1 中的结果包含有关网页的所有信息,而我只需要它的文本部分,因此我需要删除代码部分和额外信息。
这里用 () 、 () 和 sub() 函数
(1) () 函数
() 函数可以使用正则表达式来查找您需要的文本信息并直接提取。如图 1 所示。
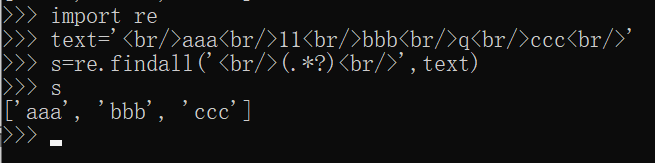
(2) () 函数
() 函数可以同时替换不同的字符。如图所示,将空格替换为 none,“!替换为“?将 “111” 替换为 “0”。

(3) sub() 函数
如果我们想用相同的字符替换许多不同的字符,我们可以使用 sub() 函数。
例如,文本中可能有很多标签 (1)、(2)、(3)......我们需要删除它们,所以我用空白的 替换它们,如下图所示。
3. 文本子句
去掉 2 中的多余信息后,文本需要被判刑。这里 (!”|?”|。“|。|?|!) 来断句。如下图所示。
方框 (1) 划分文本句子,方框 (2) 划分分割的内容组合(句子 + 标点符号)。
最终文本如下所示。

扫一扫在手机端查看
-
Tags : findall和replace函数
本文链接:https://by928.com/5815.html 转载请注明出处和本文链接!请遵守
《网站协议》
!
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 