
目录
为什么它很慢?
大家在面试的时候应该都会遇到这个问题:建太多索引有什么坏处?相信大家都能很快回答出来,会减慢数据的插入和更新速度。你有没有想过为什么呢?
我们都知道,在存储引擎中,主键是行的唯一标识,通常行记录是按照主键升序插入的,因此聚集索引的插入一般是顺序的,不需要随机读磁盘。
注意,并不是所有主键的插入都是顺序的,如果主键是类似UUID这样的规则,那么插入就是随机的,就像二级索引一样。
当我们建立二级索引(非聚集索引)时,叶子节点的插入不再是顺序的,需要随机访问非聚集索引页,随机IO的存在导致插入操作性能下降。
那么我们该如何解决这个问题呢?
存储引擎可以缓冲的DML操作——、、和,分别对应、、和Purge,所以它实际上是三者的总称。
它是一种特殊的数据结构,在更改数据时,如果该数据所在的数据页不在 Pool 中,那么引擎会将数据操作缓存在对象中,这样就无需从磁盘读取数据页了。将数据页从磁盘读入内存会涉及随机 IO 访问,这也是数据库中开销最大的操作之一。使用 write cache() 可以减少 IO 操作,从而提高数据库性能。技术架构图如下:
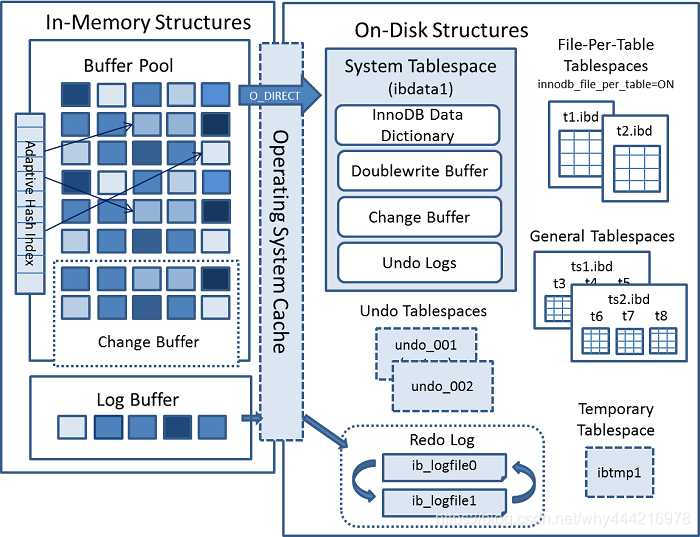
它是 Pool 的一部分,虽然叫 ,但是也可以被持久化,右边可以看到持久化空间。 中的数据最终会被刷新回数据所在的原始数据页。将数据应用到原始数据页,得到新的数据页的过程叫做 Merge,在 Merge 过程中,只有 中与原始数据页相关的数据才会被刷新到原始数据页中。
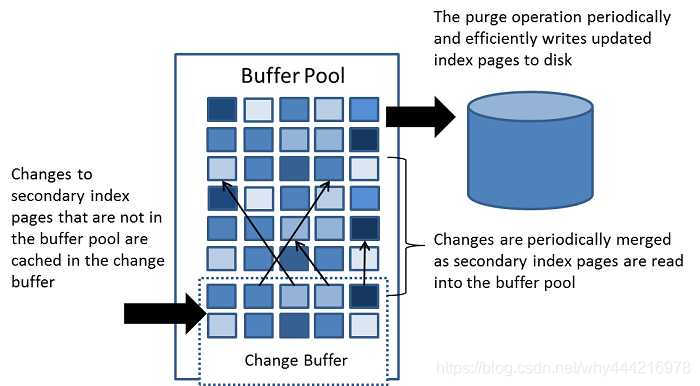
处理流程
下面分别介绍、、和。
判断是否是聚集索引,是的话直接写入索引页,不做后续操作。检查索引中是否存在该索引,是的话直接插入索引页,不是的话写入对象中。有些操作会触发Merge,将同一个索引页的多次插入合并到同一次操作中。将记录标记为已删除,放入Purge中。有些操作会触发Merge,执行Purge操作后删除。
本质上就是先做,然后做,所以是上面两个过程的结合,就不细说了。
内部实现
通过上面的过程我们发现,数据真正的写入只是发生在我们关注的索引的内部实现中。
B+ 树
它是一棵B+树,因此它也由叶子节点和非叶子节点组成。
非叶子节点存储查询键,共占用9个字节。空间占用4个字节存储每个表的唯一空间id,占用1个字节用于兼容老版本,占用4个字节表示对应页面的偏移量。结构如下图所示。
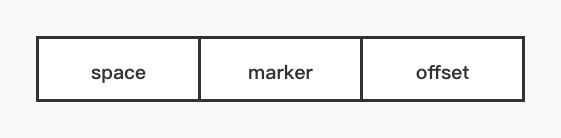
对于插入到B+树叶子的记录,需要按照如下规则构造:空间、字段和非叶子节点含义相同、第四个字占用4个字节、存储记录在存储中的插入顺序。

为了保证每次merge都成功,需要一个专门的page来标记每个辅助索引的可用空间,这个page的类型为,每个page用于跟踪16384个辅助索引页,每个索引占用4个bit,结构如下:
姓名
大小(位)
阐明
指示此服务器的辅助索引页中的可用空间量:
0 – 没有剩余空间
1-剩余空间大于1/32页
2- 剩余空间大于1/16页
3- 剩余空间大于1/8页
1表示辅助索引页有记录缓存在B+树中。
1 表示该页面是 B+ 树的非叶节点
合并处理
Merge操作可能在以下情况下发生:
读取辅助索引
当辅助索引页被读入缓冲池()时,需要检查该页确认B+树中是否有服务索引页的记录,如果有,则将该页在B+树中的记录批量插入到辅助索引页中。
辅助索引页上没有更多可用空间
如果检测到插入辅助索引记录后,可用空间将小于1/32页面,则强制进行Merge操作,将B+树中该页面的记录插入到辅助索引页中。
预定合并
该线程会根据iy的百分比,每隔一段时间进行一次Merge操作。
相关配置
以上就是关于write cache()的相关知识,我们还可以使用命令参数来控制write cache(),MySQL数据库为write cache()提供了两个参数。
show variables like '%change_buffer%';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| innodb_change_buffer_max_size | 25 |
| innodb_change_buffering | all |
| innodb_change_buffering_debug | 0 |
+-------------------------------+-------+
3 rows in set (0.01 sec)表示池中最大大小的百分比,默认为25%,最大值可设置为50%。
英
ing 参数用于控制该功能对哪些操作启用。默认值为:all。ing 参数有以下选项:
设置调试标志,1 表示记录所有内容,2 表示合并意外退出时记录,默认值 0 表示不记录。此选项仅在编译时指定 = true 时有效。
您可以使用以下命令查看当前状态:
show engine innodb status\G;
......
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
......如果你对上面的写缓存()还有些疑惑,我们用一个例子来说明一下。首先我们往数据库中插入两条数据:
mysql> insert into t(id,k) values(id1,k1),(id2,k2);
我们来结合下图来分析一下这两条插入语句。
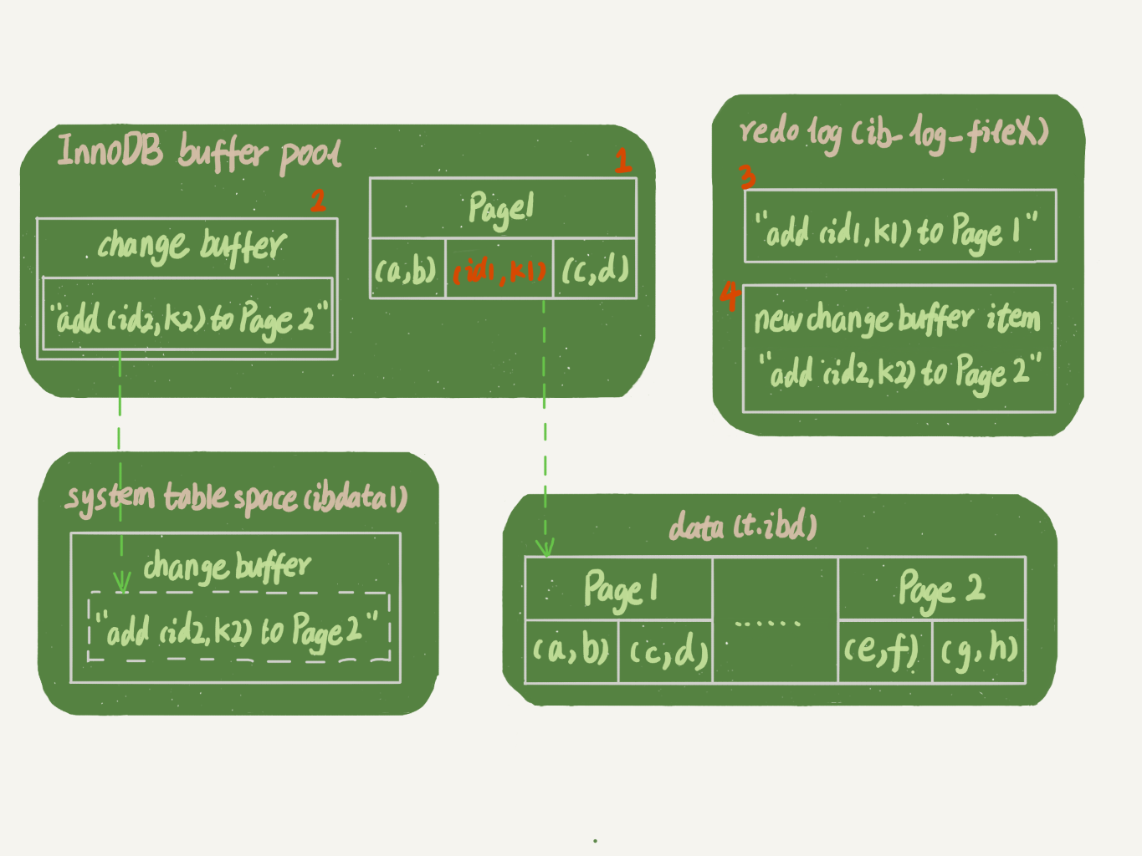
假设当前状态为K索引树,K1所在的数据页page1在Pool中,k2所在的数据页不在Pool中,我们来看看这两条语句的执行流程:
1、对于数据k1来说,Page 1是在内存中,所以直接更新内存,不会使用;
2.k2对应的数据页Page 2并不在内存中,在内存区域记录了“我要在Page 2中插入一行”的信息,这个地方很关键,并且Page 2并没有从磁盘加载到内存中。
3.以上两个动作都记录在redo log中(图中3、4)。
4. 后台线程会定期将page1中的数据持久化,
重点是第2步,也就是 write cache() 提升性能的地方,虽然page2不在内存中,但是并不妨碍我们往数据库page2中插入数据,这就是 write cache() 的巧妙之处,也是 write cache() 提升MySQL性能的原因。
地方。
适用场景
它不适用于所有场景,如果你的应用属于以下场景之一,则不适合启用它。
所有数据库都有唯一索引:如果所有数据库都有唯一索引,那么每次操作的时候都要判断是否有索引冲突,都要将数据加载到缓存中进行比较,所以是不需要的。
写入一条数据后会立即读取:写入一条数据后会立即读取,即使满足条件,先记录更新,也会因为立即访问数据页而立即触发merge过程。这样一来,随机访问IO次数并不会减少,反而会增加维护成本。因此,对于这种业务模型来说,是有副作用的。
以下情况可以显著改善MySQL数据库:
扫一扫在手机端查看
-
Tags : mysql change buffer合并时间长
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 