
1“排序依据”如何运作?
表 't' (
'id' int(11) NOT NULL,
'city' (16) 非 NULL,
'name' (16) 非 NULL,
'age' int(11) 非 NULL,
'addr' (128) 空,
KEY ('id')、
KEY '城市' ('城市')
) =;
#查询城市是 杭州市所有居民的姓名,并按字母顺序返回前 1000 名居民的姓名和年龄。
city,name,age from t where city='' 按名称排序 limit 1000 ;
1.1 全字段排序
为避免全表扫描,我们需要向 city 字段添加索引。
在 city 字段上创建索引后,让我们使用命令来查看语句的执行方式

Extra 字段中的 “Using” 表示需要排序,不使用文件排序,MySQL 会给每个线程分配一段内存进行排序,称为 ,如果大于排序后的数据大小,则使用快速排序在内存中完成排序。如果排序的数据量较小,您还需要使用临时磁盘文件来辅助排序。将排序后的数据按照大小划分为 n 个文件,按顺序对 n 个文件进行排序,然后使用 merge 和 sort 将 n 个有序文件合并成一个大的有序文件。
为了说明这个 SQL 查询的执行,我们来看一下 city 索引的图表。
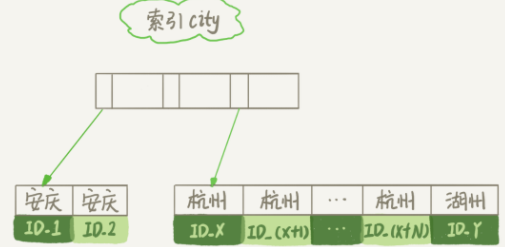
图 2 city 字段的索引示意图
从图中可以看出,满足 city='' 条件的行是从 ID_X 到 ID_ (X+N) 的记录。
通常,此语句将按如下方式执行:
1. 初始化并确保放置 name、city 和 age 字段;
2. 从索引 city 中找到第一个满足 city='' 条件的主键 ID,即图中的 ID_X;
3. 转到主键 id 索引并取出整行,取 name、city、age 字段的值,并存储在 中。
4. 从索引城市中删除记录的主键 ID;
5. 重复步骤 3 和 4,直到 city 的值不满足查询条件,对应的主键 ID 就是图中的ID_Y。
6. 按字段名称对数据进行排序;
7. 根据排序结果获取前 1000 行,并返回给客户端。
我们暂时把这个排序过程称为全域排序,执行过程的示意图如下
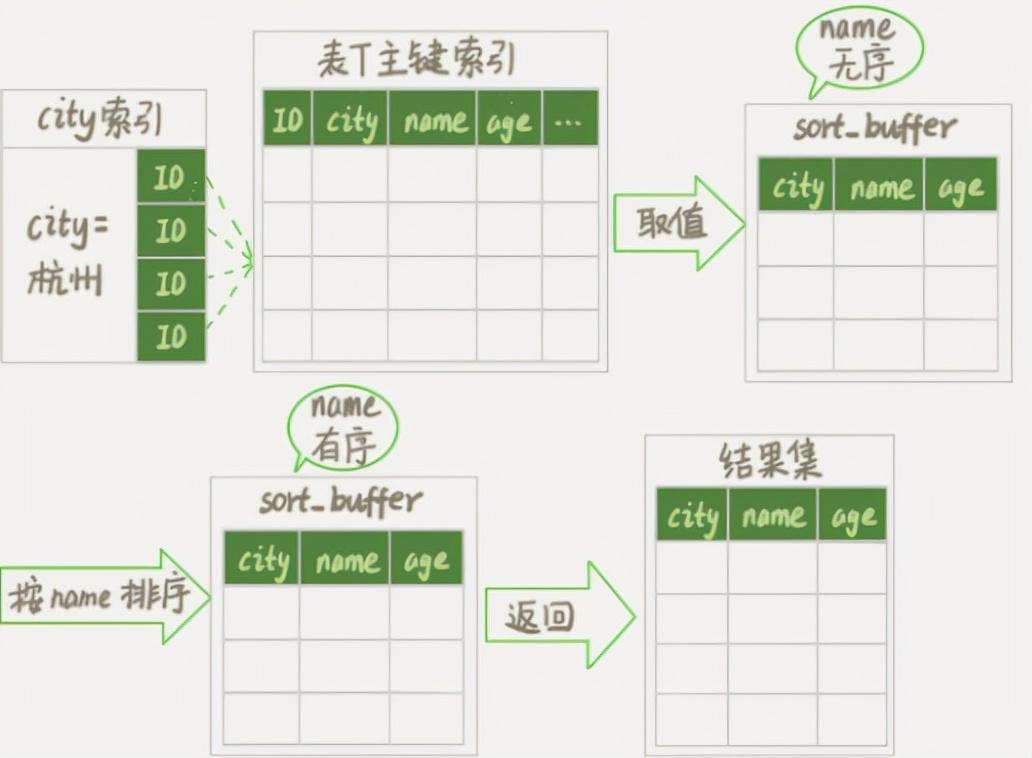
图 3 全域排序
图中的“sort by name”操作可以在内存中完成,或者您可能需要使用外部排序,具体取决于排序所需的内存和参数。,这是 MySQL 分配给排序的内存量 ()。如果要排序的数据量小于 ,则在内存中进行排序。但是,如果排序的数据量太大而无法存储在其中,则必须使用临时磁盘文件来辅助排序。
您可以使用下面描述的方法来确定 sort 语句是否使用临时文件。
/* 处于打开状态,仅对此线程有效 */
设置 ='=on';
/* @a 保存的初始值 */
从 @a 中 。其中 = '';
/* 执行语句 */
city, name,age from t where city='' 按名称排序 limit 1000;
/* 查看输出 */
* 来自 ''.''\G
/* @b已保存的 */
从 @b 中 . 其中 = '';
/* 计算差值 */
@b-@a;
通过查看 的结果可以确认此方法,并且您可以查看是否正在使用 中的临时文件。
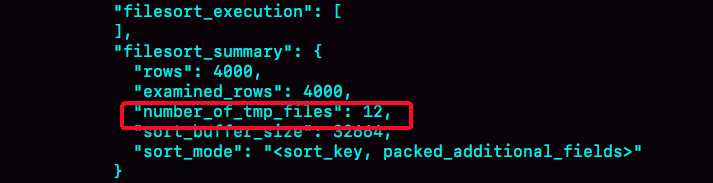
图 4 全量排序的部分结果
描述:
(1) 表示排序过程中使用的临时文件数量。您一定想知道,为什么需要 12 个文件?当内部排序不可用时,需要使用外部排序,一般使用归并排序算法。MySQL 将需要排序的数据分为 12 个部分,每个部分都单独排序并存储在这些临时文件中。然后将 12 个有序文件合并为一个大型有序文件。
如果超过了需要排序的数据量,则为 0,这意味着可以直接在内存中进行排序。否则,需要将其排序到临时文件中。它越小,您需要分成的部分就越多,价值就越大。
(2):在我们的示例表中,有 4000 条记录满足 city='',因此您可以看到 =4000,这意味着参与排序的行数为 4000。
(3) 其中 elds 的含义是字符串的排序过程是“紧凑”的。即使 name 字段定义为 (16),也会在排序过程中根据实际长度分配空间。
(4)最后一个查询语句 @b-@a 的返回结果为 4000,即整个执行过程只扫描了 4000 行。
请注意,为了不干扰结论,我将 .否则,@b-@a 的结果将显示为 4001。这是因为在查询此表时,您需要使用临时表,而 的默认值为 。如果您使用的是引擎,则当您从临时表中提取数据时,会将 1 添加到 的值中。
1.2 rowid 排序
在上述算法过程中,只读取一次原表的数据,其余操作都在 和 临时文件中进行。但是这个算法有一个问题,那就是如果查询返回的字段很多,那么需要放进去的字段就太多了,以至于可以同时放入内存中的行数就非常少了,需要分成很多临时文件, 并且排序性能会很差。因此,如果单行较大,则此方法的效率不够。
查询的字段很多,单行数据很大,所有字段都用来排序,导致大量临时文件被分割成盘,性能不佳。
1.2.1 如果 MySQL 认为单行长度太大怎么办?
接下来,修改参数以使 MySQL 使用不同的算法。
SET 数据 = 16;
data 是 MySQL 中的一个参数,专门用于控制用于排序的行数据的长度。这意味着,如果单行的长度超过这个值,MySQL 会认为单行太大,不得不改变算法。
city、name 和 age 字段的总长度为 36,我将数据设置为 16(字节),让我们看看计算过程如何变化。
这
新算法只放置要排序的列(即 name 字段)和主键 ID。
但是,此时由于缺少 city 和 age 字段的值,无法直接返回排序结果,整个执行过程会是这样的:
1. 初始化并确保放置两个字段,name 和 id;
2. 从索引 city 中找到第一个满足 city='' 条件的主键 ID,即图中的 ID_X;
3. 转到主键 id 索引,取出整行,取 name 和 id 字段,并存储在 中。
4. 从索引城市中删除记录的主键 ID;
5. 重复步骤 3 和 4,直到不满足 city='' 的条件,即图中ID_Y;
6. 按字段名称对数据进行排序;
7. 遍历排序结果,取前 1000 行,将 city、name、age 字段按照 id 的值返回给客户端。
这是这个执行过程的图表,我称之为 rowid 排序。
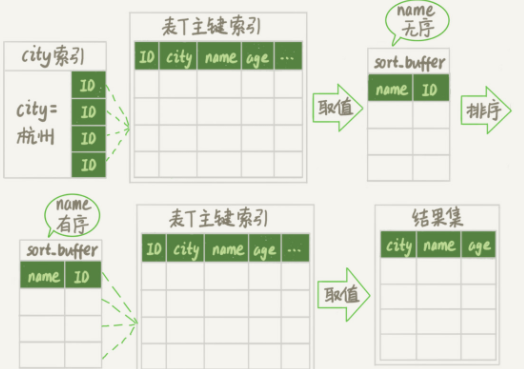
图5 rowid排序
对比图 3 中的全字段排序流程图,你会发现 rowid 排序又访问了一次表 t 的主键索引,即第 7 步。
其实 MySQL 服务器依次从 中取出 id,然后去原表查找 city、name、age 字段的结果,不需要在服务器上花费内存来存储结果,直接返回给客户端。
根据这个图解过程和图表,可以想象此时执行 @b-@a 会有什么结果。
现在,让我们看看结果有何不同。
首先,图中的 of 值仍然是 4000,这意味着用于排序的数据是 4000 行。但是 @b-@a 语句的值已经变成了 5000。
因为此时,除了排序过程之外,排序完成后,必须根据 id 删除原表的值。由于该语句限制为 1000 行,因此它会多读取 1000 行。
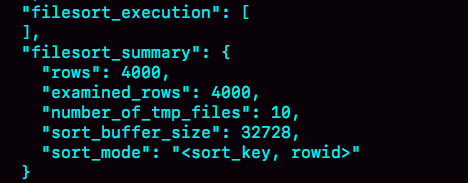
从 的结果中,您还可以看到另外两条信息也发生了变化。
它变为 ,这意味着只有 name 和 id 字段参与排序。
它
变为 10 是因为排序涉及的行数仍然是 4000 行,但每行变小,因此需要排序的数据总量变小,所需的临时文件数量也相应变小。
1.3 全字段排序 VS rowid 排序
如果您有足够的内存,请更多地使用它以最大程度地减少磁盘访问。足够的内存,快速排序。未充分利用临时文件进行合并和排序;
对于表,rowid 排序将需要将多个磁盘读取返回到表中,因此它不是首选。
1.4 利用索引的有序性来规避 Using
如果您可以确保从 city 索引中获取的行根据 name 自然地以增量方式排序,那么是否可以不再对它们进行排序?
这是真的。
所以,我们可以在这个 表上创建一个 city 和 name 的联合索引,对应的 SQL 语句为:alter table t add index (city, name);
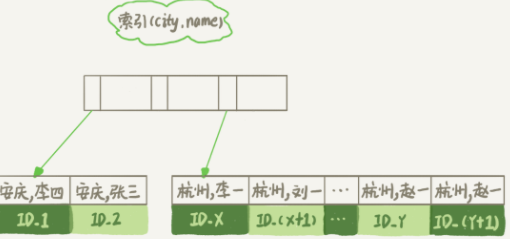
图 7 城市和名称联合索引示意图
在这个索引中,我们仍然可以使用 tree 来定位第一个满足 city='' 的记录,另外保证在按顺序取 “next ” 的遍历过程中,只要 city 的值是 ,就必须对 name 的值进行排序
这样,整个查询过程的流程就变成了:
1. 从索引 (city, name) 中找到满足 city='' 条件的第一个主键 ID;
2. 转到主键 id 索引并取出整行,获取 name、city 和 age 字段的值,并将它们作为结果集的一部分直接返回。
3. 从索引中删除记录主键 ID(city、name);
4. 重复步骤 2 和 3,直到找到第 1000 条记录,或者在不满足 city='' 条件时循环结束。
如您所见,此查询过程不需要临时表或排序。接下来,让我们使用结果来确认这一点。

从图表中可以看出,Extra 字段中没有 Using,这意味着不需要排序。而且因为联合索引 (city,name) 是自己排序的,所以查询不需要读取所有 4000 行,只要找到满足条件的前 1000 条记录即可。换句话说,在我们的例子中,只需要 1000 次扫描。
1.5 引人深思的食物
1. MySQL 在与数据进行比较时,如何判断一行数据的大小?是否可以直接从表中定义字段的大小?
必填字段的已定义大小之和
2. 与数据大小相比,哪些字段?
a) 如果是全字段排序,则为字段 + 其中字段 + order by 字段
b) 如果是排序,则是按字段排序+
3、(N),内存空间是根据实际大小分配的,N 的设置可以大吗?
需要注意的是,255.小于 255 的任何内容都需要 1 个字节的记录长度,超过 255 的任何内容都需要 2 个字节的记录长度
4 假设您的表中已经有联合索引 (city, name),然后您想要查找杭州和苏州的所有公民的姓名,并按姓名对它们进行排序,显示前 100 条记录。如果 SQL 查询语句的编写方式如下:
* 从 t where city in ('杭州',苏州 “) 按名称排序 限 100;
(1) 那么,执行此语句时是否有排序过程,为什么?
当存在 (city,name) 联合索引时,该名称在单个城市中递增。但是,由于该 SQL 语句不是单独查找城市的值,而是同时查找 “” 和 “”,因此所有满足条件的名称都不会递增。也就是说,这个 SQL 语句需要排序。
(2) 如果你在业务侧开发代码,需要实现一个不需要在数据库侧排序的解决方案,你将如何实现呢?此外,如果要分页,则需要显示第 101 页,这意味着语句末尾应更改为“limit 10000,100”,您的实现会是什么?
那么如何避免排序呢?
这里,我们需要使用 (city,name) 联合索引功能,将这条语句拆分成两条语句,执行过程如下:
1. 执行 * from t where city=“” order by name limit 100;此语句不需要排序,客户端使用长度为 100 的内存数组 A 存储结果。
2. 执行 * from t where city=“” 订单,按名称限制 100;以同样的方式,假设结果存储在内存数组 B 中。
3. 现在 A 和 B 是两个有序数组,然后你可以用 merge 和 sort 的思路来获取最小名称的前 100 个值,这就是我们需要的结果。
如果你把这个 SQL 语句中的 “limit 100” 改成 “limit 10000, 100”,处理方法其实是差不多的,就是把上面两条语句改成这样写的:
* from t where city=“ ” 按名称排序 limit 10100;
* from t where city=“ 苏州 ” 按名称排序 限 10100.
此时数据量较大,可以同时连接两行读取结果,使用归并排序算法得到这两个结果集,按顺序取 name 值 10001~10100,就是需要的结果。
当然,这种方案有一个重大的损失,就是从数据库返回给客户端的数据量变大了。
因此,如果单行数据比较大,可以考虑将这两条 SQL 语句改为如下表述:
id,name from t where city=“ 杭州 ” 按名称排序 limit 10100;
id,name from t where city=“ 苏州 ” 按名称排序限制 10100。
然后,使用合并排序的方法,按照 10001~10100 的顺序获取 name 和 id 的值,然后将这 100 个 ID 带到数据库中,找出所有记录。这些方法要求您在性能要求和开发复杂性之间进行权衡。
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 