
1.Name:请求的名称,一般使用URL的最后部分作为名称。
2、状态码:200为正常,状态码用于判断发送请求后,是否收到正常响应。
3. Type:请求的文档的类型。这意味着我们请求的是 HTML 文档,内容是一些 HTML 代码。
4.请求源:用来标记哪个对象或者进程发起了请求。
5. Size:从服务器下载的文件和请求的资源的大小。如果资源是从缓存中获取的,则此列将显示:来自缓存
6.时间:从发起请求到获得响应的时间。
7.网络请求的可视化瀑布流。
2.1.5 请求
请求:由客户端向服务器发送,分为四个部分:
1. 请求方式
2. 请求的 URL
3. 请求头
4. 请求正文
1.请求方法:GET和POST
GET:输入URL并按回车,即为GET请求。
POST:多在提交表单时发起,比如输入用户名和密码后,点击登录,就会发起一个POST请求。
GET与POST方法的区别:
GET请求中的参数会包含在URL中,在URL中可以看到数据。
POST 请求的 URL 不会包含该数据,数据以表单形式传输,并包含在请求体中。
GET请求提交的最大字节数为1024字节,而POST则没有限制。
2. 请求的 URL:URL
3.请求头:用于描述服务器要使用的附加信息。
以下是一些常用的头信息:
4.请求正文:
对于 POST 请求,请求体通常为表单数据。对于 GET 请求,请求体为空。
在爬虫中,如果要构造POST请求,那么需要使用正确的-Type,并且了解在设置各个请求库的各个参数时,使用的是哪种-Type,否则可能会导致POST提交后没有响应。

2.1.6 响应
(响应):由服务端返回给客户端,可以分为响应状态码、响应头、响应正文三个部分。
1.响应状态码:
表示服务器的响应状态,常见的响应状态码有:


2. 响应头
响应头中包含了服务器请求的响应信息。

3.响应体:响应的主体数据全部在响应体中。
在做爬虫的时候我们主要通过响应体来获取网页源代码,JSON数据等,然后从中提取内容。
2.2 网页基础 2.2.1 网页组件
一个网页可以分为三个部分:HTML,CSS。
1. HTML:
网页包含文本、按钮、图片、视频等各种复杂元素,其基本架构为HTML,不同类型的元素由不同类型的标签表示。
2.CSS:(层叠样式表)
级联:当HTML中引用多个样式文件,样式发生冲突时,浏览器可以按照级联顺序进行处理。
样式:文字大小、颜色、元素间距以及其他格式。
通过引入CSS,页面会更加美观。
3.
HTML与CSS配合使用,只能给用户提供静态的信息,缺乏交互性。比如下载进度条,提示框,轮播图片等等,都是功能,实现了页面与用户之间的实时、动态、交互。页面功能。
2.2.2 网页的结构
网页的标准形式:head和body标签嵌套在html标签中,head定义了网页的配置和引用,body定义了网页的主体内容。
2.2.3 节点树及节点间关系
在HTML中,所有标签定义的内容都是节点,这些节点构成了HTML DOM树。
DOM:文档对象模型。它定义了 HTML 和 XML 文档的标准:DOM 是一个与平台和语言无关的接口,允许程序和脚本动态访问和更新文档的内容、结构和格式。
W3C DOM 标准分为三个不同的部分:
核心 DOM:任何结构化文档的标准模型。
XML DOM:XML 文档的标准模型。
HTML DOM:HTML 文档的标准模型。
HTML DOM 将 HTML 文档视为树结构,称为节点树。
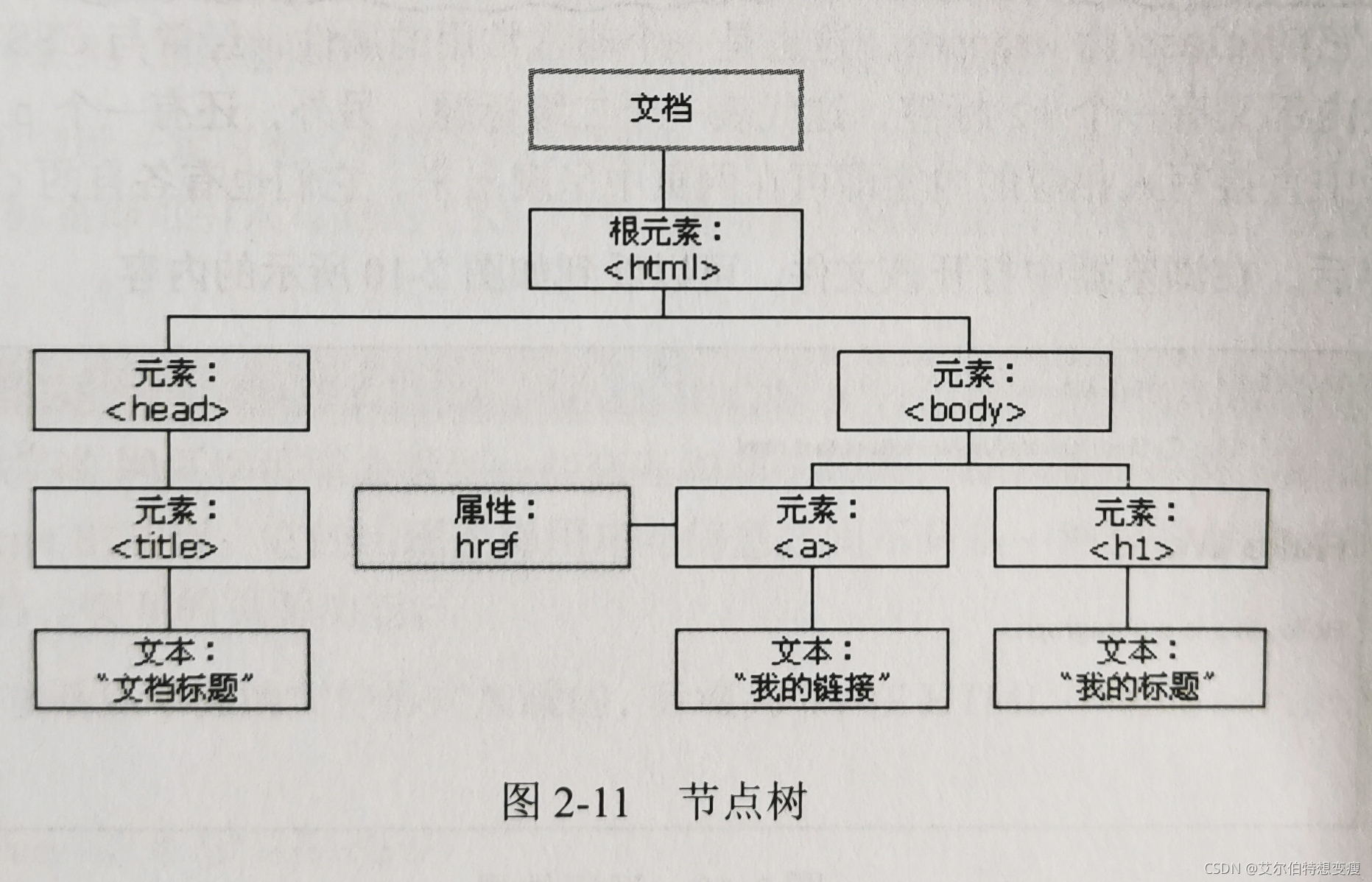
通过HTML DOM,可以通过JS访问树中的所有节点,并可以修改,创建和删除所有HTML节点元素。
节点之间的关系可以用树形数据结构来描述:
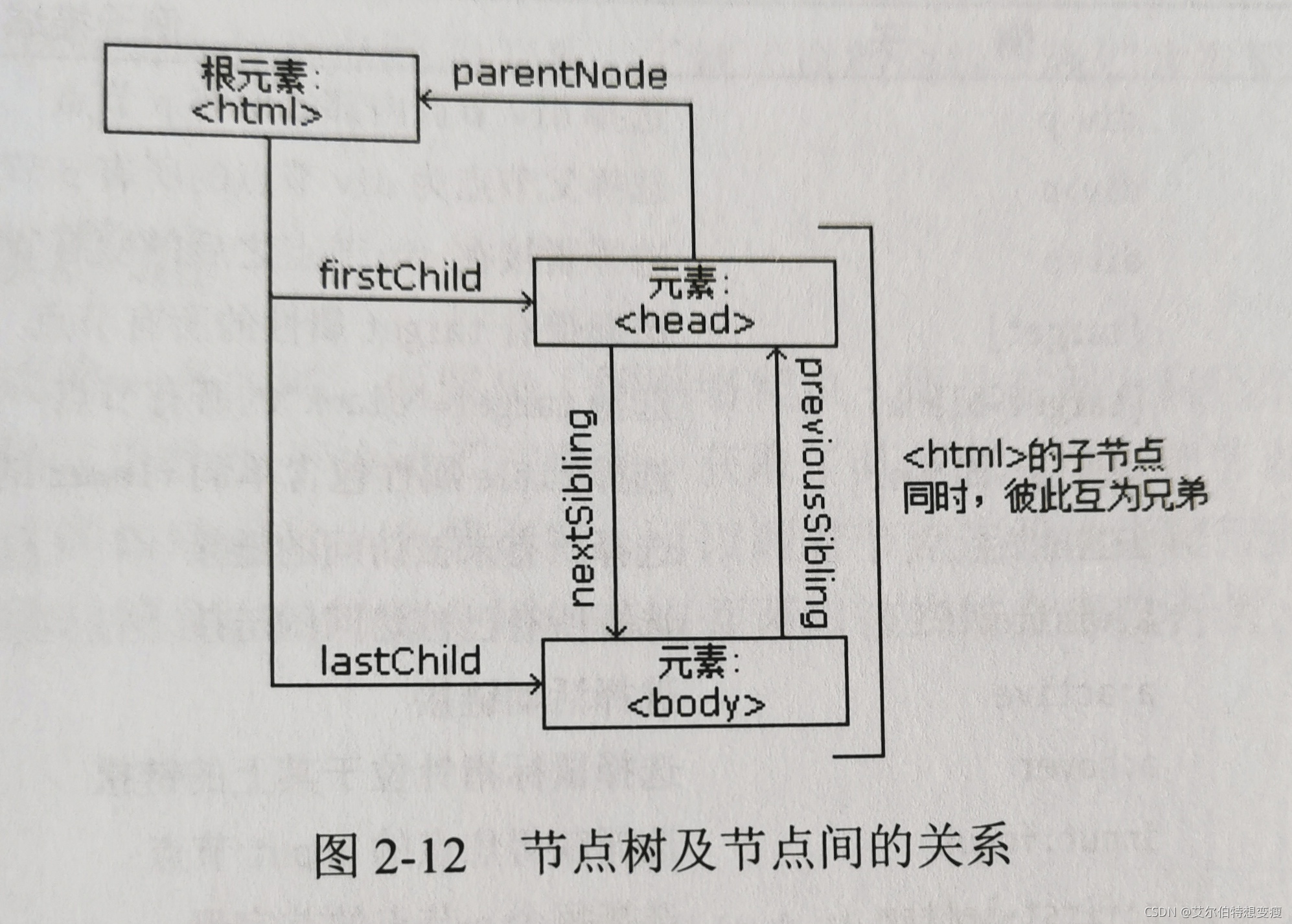
2.2.4 选择器
一个网页是由节点组成的,CSS选择器会根据不同的节点设置不同的样式规则,下面列出了CSS选择器定位节点的语法规则。
CSS 选择器还支持嵌套选择,例如:
# . p
首先选择 id 为 的节点,然后选择 class 为 的节点,然后进一步选择其中的 p 节点。
如果中间没有空格的话,就表示是AND关系。

2.3 爬虫的基本原理 2.3.1 爬虫概述:
爬虫是一种获取、提取和存储信息的自动化程序。
1.获取网页(获取网页源代码)
流程:向网站的服务器发送请求,返回的响应体就是网页的源代码。
关键部分是构造一个请求发送到服务器,然后接收响应并解析它。
方法:有很多库可以帮助完成这个过程。例如:,等等。这些库可以帮助我们完成HTTP请求操作。请求和响应都可以用类库提供的数据结构来表示。拿到响应之后,我们只需要解析数据结构的Body部分就可以了。
2.提取信息(分析网页源代码,提取数据)
方法:
1.最常见的是正则表达式(通用),但是复杂,容易出错。
2.使用一些库根据网页节点属性、CSS选择器或者XPath提取网页信息:Soup、、lxml
3.保存数据:
可以简单保存为TXT文本或者JSON文本
也可以保存在数据库、MySQL 和
它也可以存储在远程服务器上,例如使用 SETP。
2.3.2 可以捕获哪些类型的数据
HTML代码、JSON字符串(大部分API接口采用此形式)、各种二进制数据(图片、视频、音频)、各种扩展文件(CSS、JS、配置文件)。
上述内容都对应着各自的URL,这些URL都是基于HTTP或者HTTPS协议的,只要是这种数据,爬虫都可以爬取到。
2.4 () 和 2.4.1 静态和动态网页
静态网页:文本、图片等内容通过HTML代码指定,加载速度快,编写简单,但无法根据URL动态显示内容。
动态网页:可以动态解析URL参数的变化,并与数据库关联并显示不同的页面内容。
动态网页还可以实现用户登录、注册的功能,输入用户名和密码之后,就好比获得了一个凭证,可以让你一直保持登录状态,并且可以访问登录后才能看到的页面,这个凭证就是and的结果。
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 