
本文内容
前言
在爬取过程中我们大多会碰到验证码识别,这是一种常用的反爬取手段,包括:滑块验证码、图片验证码、算法验证码、点击验证码。这里提到的图片验证码比较简单,因为有大佬们已经给我们造好轮子了,我们直接套用就可以了!
测试对比
题外话,为什么要比较呢?只有比较了才知道优缺点。
pip install pytesseract
def get_captcha():
image = Image.open('VerifyCode.png')
image = image.convert('L') # 灰度处理
threshold = 220 # 阈值,二值化处理
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
image = image.point(table, '1')
image.show()
ans = pytesseract.image_to_string(image)
print(ans)
get_captcha()
介绍
硬性要求
>= 3.8
安装
pip install ddddocr
文档地址
测试,还是和之前一样的图片。
import ddddocr
def recognize():
ocr = ddddocr.DdddOcr()
with open('code_img/VerifyCode.png', 'rb') as f:
img_bytes = f.read()
res = ocr.classification(img_bytes)
print(res)
recognize()
效果一目了然,没有对比就没有伤害。
只需5行代码,就能绕过图片验证,是不是很棒?
实战
利用机器人验证帮助我们绕过反爬虫并获取我们想要的数据
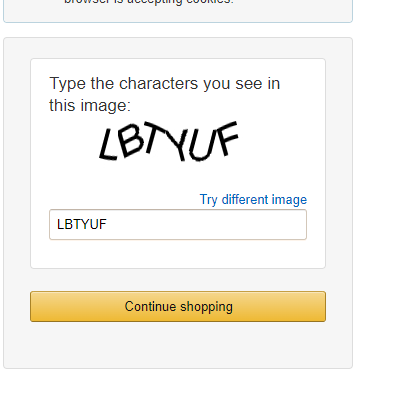
from selenium import webdriver
from selenium.webdriver import ChromeOptions
from io import BytesIO
import time
from ocr_code import recognize
from PIL import Image
options = ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-automation'])
options.add_argument("disable-blink-features=AutomationControlled")
options.add_argument(
'User-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36')
url = 'https://www.amazon.com/errors/validateCaptcha'
browser = webdriver.Chrome('chromedriver.exe', options=options)
def getCookie():
browser.set_window_size(1920, 1080)
browser.get(url)
time.sleep(1)
'''
/处理验证码
'''
# 要截图的元素
try:
element = browser.find_element_by_xpath('//div[@class="a-row a-text-center"]')
# 坐标
x, y = element.location.values()
# 宽高
h, w = element.size.values()
# 把截图以二进制形式的数据返回
image_data = browser.get_screenshot_as_png()
# 以新图片打开返回的数据
screenshot = Image.open(BytesIO(image_data))
# 对截图进行裁剪
result = screenshot.crop((x, y, x + w, y + h))
# 显示图片
# result.show()
# 保存验证码图片
result.save('VerifyCode.png')
# 调用recognize方法识别验证码
code = recognize('VerifyCode.png')
print(code)
# 输入验证码
browser.find_element_by_name('field-keywords').send_keys(code)
# 点击确认
browser.find_element_by_class_name('a-button-text').click()
time.sleep(1)
except:
break
if __name__ == '__main__':
getCookie()
.py
import ddddocr
def recognize(image):
ocr = ddddocr.DdddOcr()
with open(image, 'rb') as f:
img_bytes = f.read()
res = ocr.classification(img_bytes)
return res
结果
拦截验证码
打印
点击关注别迷路,如果这篇文章对你有帮助的话,麻烦点三个赞支持一下❤️❤️❤️
你们的支持与认可就是我最大的动力❤️❤️❤️

扫一扫在手机端查看
-
Tags : ddddocr
本文链接:https://by928.com/6642.html 转载请注明出处和本文链接!请遵守
《网站协议》
!
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 