

DOM 是所有前端开发者每天都要打交道的东西。然而随着 DOM 等库的出现,DOM 操作被大大简化,导致大家慢慢“忘记”了它原来的样子。不过想要深入学习前端知识,对 DOM 的理解必不可少,所以本文力求系统讲解 DOM 的相关知识。如有疏漏或错误,还请指出,共同探讨^^。
1.什么是 DOM?
DOM(文档对象模型)是 HTML 和 XML 文档的 API,通过它可以更改文档。
这个说法非常官方,相信大家还是不太明白。
比如:我们有一段HTML,我们如何访问第二层的第一个节点,如何将最后一个节点移动到第一个节点?
DOM 是一个标准,它定义了如何执行类似的操作,例如访问节点和插入节点。
当浏览器加载HTML时,会生成相应的DOM树。
简单来说,DOM可以理解为访问或者操作各种HTML标签的实现标准。
对于一个HTML来说,文档节点(不可见)是它的根节点,对应的对象就是 对象(严格来说是一个子类对象,下面单独介绍类型时会指出)。
也就是说,有一个文档节点,然后它有子节点,比如通过.(“html”),我们得到了html类型的元素节点。
每个 HTML 标签都可以用一个对应的节点来表示,例如:
HTML 元素用元素节点表示,注释用注释节点表示,文档类型用 节点表示,等等。
总共定义了12种节点类型,这些类型都继承自Node类型。
因此我们首先讨论Node类型,因为该类型的方法被所有节点继承。
2.节点类型(基类,所有节点都继承其方法)
Node是所有节点的基类型,所有节点都从它继承,因此所有节点都有一些共同的方法和属性。
我们先来了解一下Node类型的属性
第一个是属性,用于指示节点类型,例如:
document.nodeType; // 返回 9 ,其中document对象为文档节点Document的实例
这里的9代表的是节点,可以通过Node查看节点对应的数字。
document.nodeType === Node.DOCUMENT_NODE; // true
至于有多少个节点,每个节点对应什么数字,你可以去一下,反正最常用的就是元素节点(对应数字1)和文本节点Text(对应数字3)
然后还有常用的
对于元素节点,为标签名称,为null
对于文本节点,它是“#text”(内部测试),这是实际值
每个节点还有属性,属性是一个非常重要的属性,它保存了这个节点的所有直接子元素。
该调用返回的是一个对象,和数组很相似,但是有一个关键点,它是动态查询的,也就是每次调用都会查询DOM结构,所以需要谨慎使用,注意性能。
可以使用数组表或项目方法进行访问
然后每个节点都有各种属性允许它们相互访问,下图很好地总结了这一点。
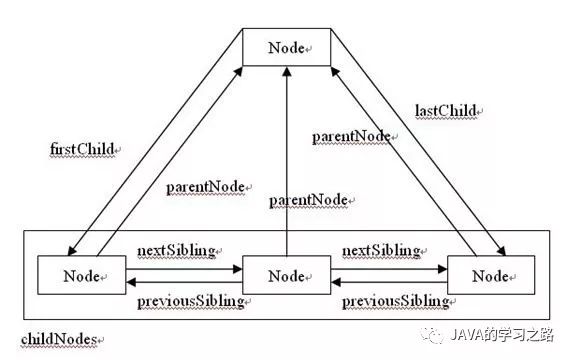
一些有用的方法和属性:
1. ()
如果包含子节点,则返回true,比查询简单。
2.
返回对文档节点的引用(即 HTML 中的对象)
下面介绍一下Node类型常用的方法
() 方法可以在节点末尾添加一个节点,值得注意的是,如果这个节点在文档中已经存在,那么原来的节点会被删除,感觉就像是移动了节点。
() 方法接受两个参数,一个是要插入的节点,一个是引用节点。如果第二个参数为 null,则效果相同。否则,节点将插入到引用节点之前。如果第二个参数不为 null,则插入的节点不能是现有节点。
() 方法可以替换一个节点。它接受两个参数:要插入的节点和要替换的节点。它返回被替换的节点。
()移除节点。这里有一个常见的需求,比如我有一个节点#waste-node,如何移除它?
var wasteNode = document.getElementById("waste-node");
wasteNode.parentNode.removeClhid(wasteNode); // 先拿到父节点,再调用removeClild删除自己
这里先暂停一下,不知道大家有没有注意到,上面的这些方法都是对一个节点的子节点进行操作的,也就是说,操作之前必须先找到父节点(通过查找)
接下来我们讲一下如何复制节点:
();复制一个节点,接受一个参数 true 或 false。如果为 true,则复制该节点及其子节点。如果为 false,则复制节点本身(复制的节点不会有任何子元素)。该方法返回复制的节点。如果需要操作某个节点,则需要使用上面提到的四种方法将此节点放入 HTML 中。
到此为止,Node类型常用的属性和方法就介绍完了,结合一开始说的,所有的节点类型都是继承自Node类型,所以这些方法是所有节点共用的。
3.类型
在我们第一次讲什么是 DOM 的时候,我们提到了类型。其实这个类型最重要的就是它的一个子类有一个实例对象。而这个对象就是我们最常使用的。
该对象被挂载在对象上,因此可以在浏览器中直接访问。
和往常一样,我将首先讨论对象的属性,然后再讨论其方法。
对象的一些属性
. 继承自上面提到的Node类型,可以返回文档的直接子节点(通常包括文档声明和html节点)
.可以直接获取html节点的引用(相当于.("html")[0])。
.body 对 body 节点的引用
.title 页面的标题,可修改,会改变浏览器标签上的名称
.URL 页面的 URL
.获取,也就是打开这个页面的页面地址,在做源统计的时候比较有用
. 获取域名,可以设置,但通常只能设置不包含子域名,在某些跨域的情况下比较有效。
接下来我们介绍两种常见的方法
和
,传入id,获取元素节点。参数区分大小写(IE8-不区分)。注意:如果有多个元素id相同,则返回第一个。IE7-中,表单元素名称也会当做id来使用。
通过标签获取元素,并获取类型,传入“*”可以获取所有元素。
还有一种方法只对类型(即对象)可用。顾名思义,它根据名称返回元素。
对象也有一些集合,例如 .forms,它返回所有形式。类型也是如此。
说到这里,我们再说一遍
它是一个包含一个或多个元素的集合,和上面介绍的挺像的。这个类型有两种方法,一种是通过下标(或者 .item())获取具体元素,一种是通过 ['name'](或者 .())获取具体元素。
最后,还有一组关于对象的重要方法,它们是
写入() () 打开() 关闭()
open和close分别用于打开和关闭网页的输出流,在页面加载过程中,相当于打开状态,这两个方法一般不用。
然后重要的方法是 write 和 ,它们都将东西写入页面,不同之处在于后者会增加一个额外的换行符。
注意:您可以使用这两种方法在页面加载时向其添加内容。如果页面已加载并调用 write,则整个页面将被重写。
还有一点就是如果你要动态的写一个脚本,比如这个,那么要注意单独组装,不然会误认为是脚本的结束,导致这个结束符跟上面的起始符对上了,可以这样写"";
类型
接下来我们来谈谈最重要也是最常见的类型,类型。
我们日常生活中操作的都是类型(其实为了方便,就这么讲吧),比如
document.getElementById("test")
返回的是类型,我们日常说“DOM对象”通常是指类型的对象。
然后说一下该类型的常见属性:
首先它具备开头提到的Node类型上的所有属性和方法,这里就不再赘述,主要说一下它特有的。
首先,这与从其继承的 Node 类型相同。它返回标签名称,通常为大写,结果取决于浏览器。因此在比较时
最好调用一个类似的方法比如()来进行比较。
我们来谈谈上面提到的类型。
Type继承自Type,也是HTML元素的实际类型,我们在浏览器中使用的元素都是这种类型。
此类型具有一些标准属性,例如:
id 元素的唯一标识符
标题通常是鼠标移到其上时显示的信息。
类名
等等,这些属性都是可读可写的,也就是说你改变它们就会得到相应的效果。
除了属性之外,还有几个重要的方法
首先我们来说一下如何操作节点属性。
,,这3种方法。
这些是操作属性最常用的方法。我不会解释如何使用它们,它们非常简单,顾名思义。
还有一个属性,它保存了元素的所有属性。
我们在这里停下来并提出一个问题:ele. 和 ele.(“class”) 返回相同的东西吗?
为了回答这个问题,我想讲一个重要的知识点,元素的属性结构是这样的,比如一个inpnt元素
id="test" checked="checked">
然后将这个元素的属性包含在input中,比如你在HTML元素上看到的class,id或者你自己定义的data-test属性。
那么这三个方法可以认为是快捷收集方法,直接的 input.id 或者 input. 都是直接附加在 input 上的属性,和 是同一级别的,所以返回的东西可能看上去一样,其实是不一样的,不信你可以试试 input.this input.(“”)。
关于这个知识点我可以另外写一篇文章来详细讲,我在我的博客从is(“:”)开始讲过,大家可以看这篇文章以及文章后的讨论就知道到底是怎么回事了。
一般情况下,这三个方法通常用于处理自定义属性而不是id、class等“已经识别出的特征”。
接下来我们来谈谈创建元素
.() 可以创建一个元素,例如:
document.createElement("div");
一般情况下,给元素设置属性有两种方式,一是直接使用node.,二是node.("","value")等。
但完成所有这些操作后,该元素仍然不在页面上,因此您仍然需要使用与顶部提到的类似的方法将该元素添加到页面中。
在 IE 中,你也可以直接传入整个 HTML 字符串来创建元素,例如
document.createElement("test");
最后,元素节点还支持类型搜索方法,例如。但是,它只会找到自己的后代节点。因此,您可以像这样编写代码
document.getElementById("test").getElementsByTagName("div"); // 找到id为test元素下的所有div节点
5. 文本类型
这种类型很特殊,也是第三种最常见的类型(第一和第二种分别是和)。
这个节点只是一个字符串。
很重要的一个特性就是它没有子元素(不过这个只要你仔细想一想就能想明白= =)
要访问文本节点的文本内容,可以使用或数据属性。
以下是它提供的一些方法:
appendData(); // 在text末尾加内容deleteData(offset, count); // 从offset指定的位置开始删除count个字符
还有诸如、、等等方法我就不一一说了,很少用到,有用的时候可以去查一下。
然后它还有一个返回字符长度的属性。
这是一个常见的陷阱。例如,以下 HTML 结构
这里,ul的第一个子节点()是什么呢?乍一看,你会认为是li,但实际上,你会发现,它并不是li,而是一个文本节点!
这是因为浏览器认为 ul 和第一个 li 之间有空格,因此有一个文本节点。
这里经常遇到的一个问题就是在遍历ul的时候,要判断遍历到的元素是否等于1(等于1说明是元素节点),这样就可以跳过这个坑了。否则的话,也可以把空格和换行符号全部删除。
创建文本节点的方法是。
然后接下来就和操作类型一样了,重新插入到元素里面,浏览器就可以看到啦。
6. 其他类型及
这些不常见的词语被带过来
是注释节点
它是一个节点,可通过它访问。
此节点是文档片段,偶尔会用到。
例如,常见的用法是在 ul 中插入 3 个 li。
如果插入三次循环,浏览器将必须渲染三次,这将对性能产生重大影响。
所以每个人通常都会这样做
第一的
var fragment = document.createDocumentFragment();
然后循环并将 li 插入其中
最后再插入到ul里就可以了,这个会很快的。
7. DOM 扩展
上面讲了这么多的节点类型,相信大家对 DOM 节点已经有了很深的理解了,接下来我们再讲一下关于 DOM 扩展的一些事情。
为了方便开发者,浏览器扩展了一些DOM功能。
因为它是一个浏览器扩展,所以在使用之前一定要注意兼容性问题。
通过 和 确定“标准模式”与“混合模式”。
上面我们不是提到过使用文本节点作为第一个子元素存在一个陷阱吗?因此,浏览器实现了另一个仅包含元素节点的属性。
为了方便判断节点A是否是节点B的子节点,引入一种方法,例如
B.contains(A); // true就代表是,false就代表不是
此方法存在兼容性问题,使用前请先一下解决方法。
为了访问元素,提供了 4 种方法///。
通过这些方法,可以读取和写入元素。
其中*TEXT返回文本内容,*HTML返回HTML文本。
而outer*表示是否包含元素本身。
在实际使用中,读取内容时inner*和outer*没有区别。
当向元素写入内容时,区别在于是否包含元素本身。
重要的是这些方法都存在性能问题,比如在IE中,通过inner*删除的节点绑定的事件还在内存中,很容易消耗大量内存。
另一个技巧是插入大量 HTML 代码,这非常快并且值得推荐。
8. 结论
首先感谢看到这里的朋友,哈哈,DOM 的东西太多了,不过这也是前端最重要的知识点之一,文章比较长,可能有点枯燥,不过希望大家能耐心看完,看完一定有所收获^^。
- 结束 -
关于作者

W先生
白天搬砖,晚上筑梦。
我相信每个人都有故事,程序员也有很多意外,我把最接地气的程序员故事写出来,给大家找到更好的资料。
扫一扫在手机端查看
-
Tags : 文本节点的nodetype值_DOM之通俗易懂讲解
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 