
由于问题是样本不够,所以增加样本量。我们延长了1%阶段的维护时间,让新VIP有机会收集足够的样本来“稀释”非常规数据点的整体影响。
您可以参考下图。假设老VIP的rps为90,新VIP的rps为5,那么新VIP在90分钟内的样本数(5*90)等于老VIP在5分钟内的样本数分钟(90*5)。相同数量的样本,我们可以完成“公平”的比较。
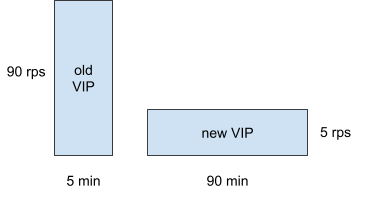
(点击查看大图)
经过这次调整,误报率确实明显降低了。
计划
当然,我们最终采用的解决方案比我们刚才讲的要复杂得多,包括:
(点击查看大图)
(点击查看大图)
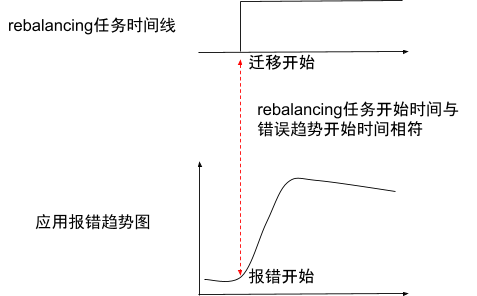
当后端服务器发生重大变化(例如从VM迁移到k8s pod)时,此功能更有意义。因为应用环境的变化,很可能对应用层造成干扰,造成不可预测的情况。监控HTTP返回码可以很容易地发现这种情况,如下图所示:
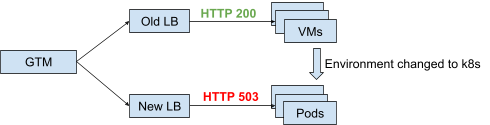
(点击查看大图)
(点击查看大图)
(点击查看大图)
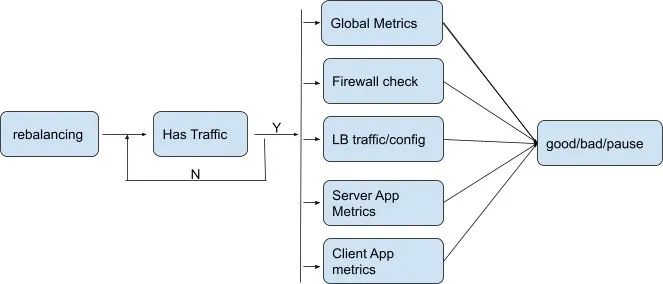
挑战二:如何选择合适的VIP进行迁移?
思考
对于LB这样的网络系统来说,带宽()和CPU是两大类资源开销。所谓“热LB”问题所关注的资源对象到底是哪些?
10G LB时代,就是带宽。
40G LB时代,CPU已经超越带宽成为新的瓶颈。
这一变化也给我们带来了一个新的问题:某个VIP迁移后,我们如何知道原来的LB上可以减少多少CPU开销?令人沮丧的是,即使是LB制造商也没有这样的数学模型。
在半自动化时代,我们的做法是:
为什么我们需要进行第3步的审核?原因是缺乏模型,我们无法知道这次 VIP 迁移后对 CPU 降级的实际影响。简单来说,就是“尝试转成VIP,看看效果”。
所以我们必须有这样一个模型。假设这样的情况:
某热点LB当前CPU峰值为80%,目标CPU峰值为65%。上面有100位VIP。如果我们根据数学模型以及qps和bps监控值计算出相应消耗的CPU资源:
VIP1: 8% CPU
VIP2:7% CPU
VIP3:3% CPU
VIP4:2% CPU
……
由于我们的目标是迁移至少 15% 的 CPU 开销,那么由于 VIP1 和 VIP2 的 CPU 开销正好是 15%(8% + 7%),所以我们的全自动化可以选择这两个 VIP 进行迁移。
我们认为,对于流量特征(rps、IN bps、OUT bps)确定的 VIP,其对应的 CPU 开销值也应该是可确定的(至少可以缩小到一定的精度范围)。从原理上讲,VIP流量本质上是数据包在LB的网卡、L4处理(TCP)、L6处理(TLS)、L7(HTTP)处理的开销。我们来一一分析:
如果有这样一个数学模型,输入值包括:qps、bps、、model,输出值是CPU开销,那么“如何选择合适的VIP进行迁移”的问题就可以回答了一半。另一半主要与业务特点有关。
计划
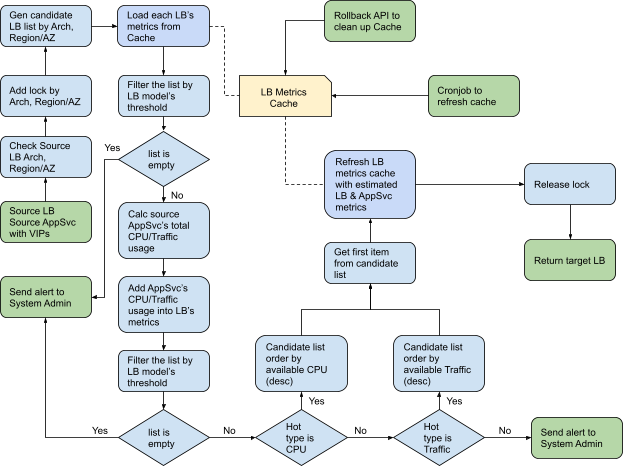
为了获得这样的数学模型,我们做了两件事。
首先是样本数据的收集。我们在测试LB上配置了一些具有代表性的VIP,然后对这些VIP进行了压力测试。当CPU达到一定值时,我们记录CPU使用率、VIP rps、IN bps和OUT bps。
然后是数据建模。使用numpy库对之前的样本数据进行函数拟合,得到对应的函数曲线。
一旦有了模型,就可以计算它。将线路上的实际数据(VIP rps、IN bps、OUT bps等)代入建立的数学模型中,即可得到相应的LB CPU开销值。
(点击查看大图)
上图中,横坐标是阶数,纵坐标是误差级别。显然,阶数越高,误差越小。一阶误差较大,而二阶误差则显着下降。从“成本效益”的角度出发,我们选择了二阶拟合函数。
(点击查看大图)
经过空运行阶段的测试和调整,该模型给出的CPU估算是比较准确和充足的。与过去“没有数据可参考”、全靠“尝试迁移”的时代相比,现在基于数学模型的做法不仅避免了重复迁移或反复迁移,也避免了这种方式带来的风险。
\ | /
★
挑战三:如何选择合适的LB?
思考
与前两个挑战相比,“如何选择合适的LB”相对容易。一般来说,我们只需要做以下几件事:
但由于真实环境的复杂性,我们还需要考虑一个重要的问题:如果迁移ATB池(即支付等最关键的功能),原来分布在多个LB的ATB池是否会受到影响?感动吗? ,他们都集中在同一个LB上吗?那样的话,这个LB不就成了“鸡蛋都放在一个篮子里”的篮子了吗?
注:ATB是eBay的可用性指标,其全称是To。这也是技术团队最关注的指标。 ATB池是最关键的应用。
这也体现了eBay运维工作的特点:除了技术之外,系统设计时还需要充分考虑业务特点。因为系统最终是为业务服务的,所以“量身定做”的部分不能缺少。
我们为ATB池设计了一个数据表。 LB选择等逻辑会避开这些ATB池,选择其他非ATB池。由于eBay应用较多,LB热点关注的焦点是LB负载是否降回安全线。只要选择的迁移池能够达到这个效果,就满足需求。
计划
我们最终选择的LB的自动选择机制如下:
(点击查看大图)

计划确定
基于以上准备工作,全自动化解决方案所需的所有环节均已完成。我们来看看最终的整体解决方案。
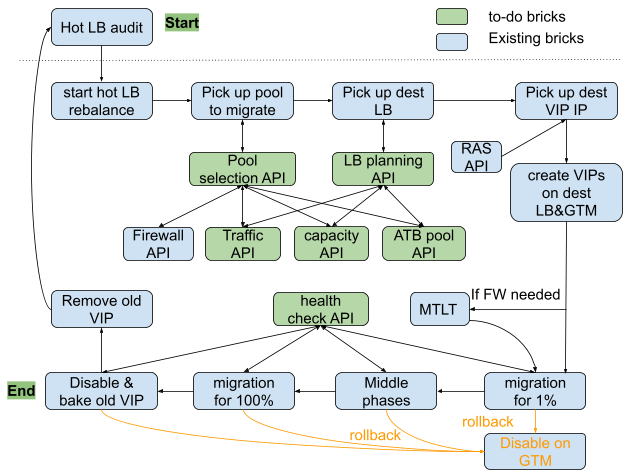
(点击查看大图)
图中浅蓝色组件是半自动化时代已经具备的基础设施能力,绿色组件是全自动化项目中需要完成的部分。当这些绿色组件就位后,我们终于可以将全自动系统的初始版本上线,然后开始在监督下进行空运行并继续收集问题。
毫不奇怪,我们“获得”了一些新的挑战。

新挑战一:如何保证Web层的流量分布严格匹配GTM?
文章开头我们介绍了两种流量迁移的方法。虽然它们本质上都是通过“上层调整比例”来实现流量迁移,但是Web层和App层还有一个区别:Web层流量分配的实际效果往往与我们的配置值相差甚远。这是为什么呢?
思考
Web层的流量调度采用eBay的GTM。 GTM本质上是一个智能DNS,这种流量控制是基于DNS的原理来实现的。因此,必然会受到DNS本身机制的限制,尤其是其缓存机制。我们看一下一个典型的eBay内部应用实例的域名解析路径:

(点击查看大图)
eBay的典型技术栈是Java,所以一般来说,我们的应用程序在名称解析中会遇到以下几种缓存:
1、JVM本身有缓存机制(比如60秒,不遵循DNS TTL)
2、JVM所在主机的本地缓存(遵循DNS TTL)
3.本地解析服务器DNS缓存(遵循DNS TTL)
4、权威服务器(本例为GTM)配置修改生效时间
如果从客户端到服务器存在一条链条,那么上面的链接实际上是松散的。它们都像()函数一样,不同程度地增加了随机性。累加的结果就是最终的结果(即实际有效的流量分配)带来了较大的干扰。
然而,这些缓存机制并不是那么容易修改的。例如,如果要改变JVM的60秒缓存机制,就需要进行充分的应用测试和全面的框架升级。这条路并不容易,也不一定是最好的解决方案。
DNS TTL 可以调整吗?可以预见,TTL值越小,查询压力越大。但有时候事情就是这么奇妙,我们担心的事情可能并没有真正发生。当我们期间“破天荒”地将TTL调整为0时,DNS和GTM的CPU占用率仅略有上升,完全在安全范围内。因此,通过将 TTL 调整为 0,主机和 DNS 缓存(即上面的第 2 项和第 3 项)的影响也最小化。
分析完JVM和DNS的TTL,我们来到最后一个环节,GTM。我们发现GTM经常没有按照我们预期的比例返回结果,这也是迁移过程中Web层流量分配不准确的原因之一。
为了验证解析结果是否准确,我们使用dig命令多次解析GTM。事实证明,当解析数量比较少(数百个)时,解析结果中新旧IP出现次数的比例确实与GTM设置值相差较大。
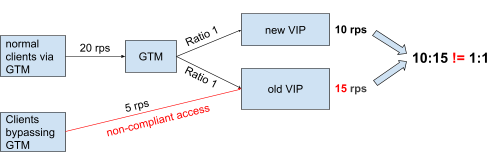
类似如下:GTM上新老VIP的实际权重值是10:90,但分析结果是1:33(往往是其他比例)。
for i in {1..100};do dig +noall +short ;完成 |排序|优衣库-c
33 209.100.100.100(老VIP)
1 209.100.100.101(新VIP)
33 209.100.100.102
33 209.100.100.103
此外,我们发现如果增加解析次数(几千次),解析结果会非常接近GTM设置值,如下所示:
for i in {1..3000};do dig +noall +short ;完成 |排序|优衣库-c
900 209.100.100.100(老VIP)
100 209.100.100.101(新VIP)
999 209.100.100.102
1001 209.100.100.103
经过反复思考,我们发现问题在于我们之前只关注了“比例”而没有关注“原值”。例如,我们直观地感觉90:10和9:1是一样的。他们不是都是九比一吗?但是,在GTM层面,两者有很大的区别,因为GTM严格按照原始值返回和解析。
还是上面的例子。老VIP和新VIP的权重值分别为90和10,那么GTM将在前90次解析时返回旧VIP,而仅在第91到100次解析时返回新VIP!改成9:1后,老VIP前9次返还,新VIP第10次返还,这样流量就能尽快按照我们的预期分配。您可以参考下图。
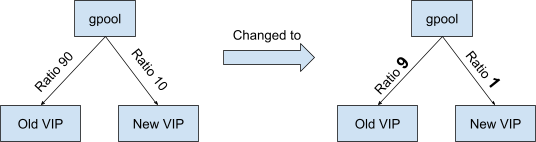
(点击查看大图)
流量未按预期分配的根本原因是解析生效的延迟。现在DNS解析完成了,问题解决了吗?并不真地。还有一个因素也有重要影响,那就是TCP长连接。也就是说,解析效果延迟的原因其实有两个:
1.DNS缓存
2、长连接
不过相比之下,长连接的问题更容易解决:我们只需要断开长连接即可。当然,说起来容易,我们也不能修改客户端的代码。如何让客户端放弃这些长连接呢?
通过探索,我们发现只用协议规范就可以实现这个需求,而无需改变一行应用代码。 eBay的大部分应用程序都是基于HTTP协议的,而HTTP协议恰好有一个可以控制长短连接的功能,那就是“:Close”头。当服务器的 HTTP 响应包含此标头时,根据 HTTP 规范,客户端应断开 TCP 连接。当客户端发起新的请求时,必须创建一个新的TCP连接。创建新连接时,一般需要再次进行DNS解析(应用程序缓存解析结果的情况并不常见)。因此,GTM上的比率配置将反映在本次分析的结果中。
计划
插入“:Close”头并不复杂,我们只需要在LB上设置相应的即可。如下图所示,LB将这个插入到HTTP响应报文中,相当于告诉客户端:你可以关闭连接了。
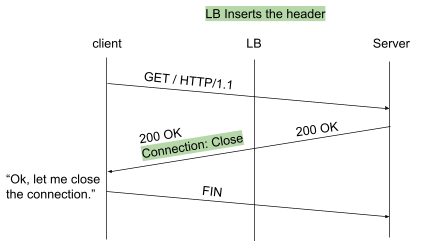
(点击查看大图)
下图展示了我们应用两种对策(DNS TTL=0 和 LB)后,Web 层流量如何从非常不规则变为非常规则且流畅。
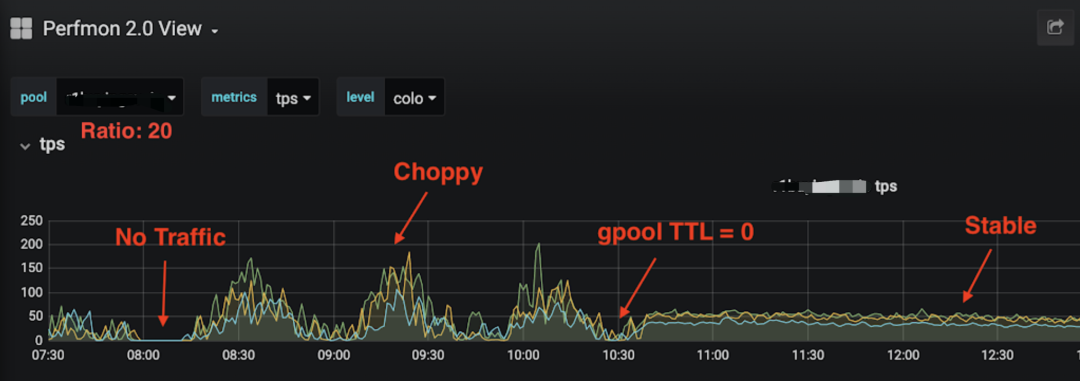
(点击查看大图)
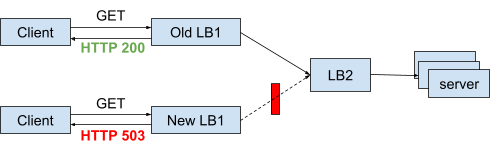
另外一个问题,即旧VIP上的流量因长连接而不易停止的问题,也通过LB来解决。

(点击查看大图)
新挑战二:如何保证全自动化任务的成功率?
如果说一个全自动化项目的成败只有一个评价标准的话,那就是成功率。成功率低意味着我们的工程师仍然需要花费大量时间进行重试、故障排除和修复。成功率高,当然意味着我们的效率高。
思考
不难想象,要提高成功率,需要从两个方向入手:
内部任务的成功率是我们可控的,但外部依赖的成功率提升存在很多不确定性。最大的困难在于这些服务由不同的团队维护,这不可避免地导致各个团队之间的工作优先级不一致。该怎么办?
我们很快决定直接采用重试策略。用这种简单直接的方法,尽可能地“消化”外部API的失败率。我们来做一个简单的估算。假设外部API的成功率为80%,我们重试两次API调用,那么成功率就会上升到100%-20%*20%*20%=99.2%。
每个热负载均衡任务平均需要约 30 次外部 API 调用。乘以30次99.2%的调用,我们可以得到理论上的成功率:78.58%。
计划
九月底我们要“上台表演”,所以我们得提前在台下练功。为了抓住每一个人,我们进行了大量的演练。 9月份上线之前,我们累计了200多个任务,相当于去年上线实际发生的任务数量。空运行次数越多,上线后可靠性越高。因此,这项投资必须进行,而且是值得进行的。
我们还继续监控任务成功率和失败原因。以2020年Q4为例,这三个月(完全无需人工干预)完成的全自动任务成功率达到89.2%。成功率本身会随着时间的推移而波动。三个月有这样的表现,说明重试策略已经达到了应有的效果。
✦
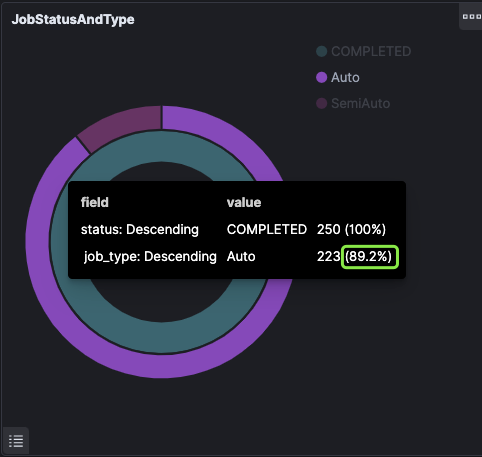
(点击查看大图)
新挑战三:如何保证全自动化不引发事故
思考
不要害怕自动化,但要害怕完全自动化。因为在半自动化的过程中,总有人在看着你,这让你感觉更安心。例如,根据现场情况灵活做出选择和应对,使系统的运行始终处于人的掌控之中。然而,在完全自动化之后,我们往往缺乏信心。我们最担心的其实是担心全自动化会“自己做决定”而引发事故。
这是否意味着它不能完全自动化?如果我们在系统上设置一些不得跨越的“禁区”,这样的担忧是否会大大缓解呢?这堪称“底线思维”——不求最好的操作,但绝对不做不该做的事。
计划
Hot LB的全自动化也运用了底线思维。只要我们做到以下几点,热LB全自动化对生产环境的影响就会降到最低:
效率输出
在陆续解决了前面提到的诸多问题后,热LB全自动化终于在2020年9月上旬正式上线。截至2022年11月25日,这两年零两个月已经完成了3800个任务。在半自动时代,每项任务需要2.5个小时的人力,相当于节省了60个人月。全自动化效率显着!
从任务量来看,全自动化每年完成约1800项任务。与半自动时代每年250个任务相比,产能提升至7.2倍。这是通过显着减少人力投入来实现的。
通过完全自动化实现性能的数量级改进,我们实现了最初的目标。
(点击查看大图)
LB之间的自动平衡
这就是热LB的主要功能。我们直接看一下实际效果。下图中,不同颜色的线代表一个LB设备。有七个高峰和低谷,代表 7 天的交通状况。很明显,橙色线LB的CPU使用率从第五天开始就有所增加,并且在第六天明显高于其他曲线,表明其负载明显增加。完全自动化很快就开始发挥作用(VIP 被转移到其他LB)。这条橙线迅速逼近主力,并在两天内恢复到与其他LB相同的水平。
(点击查看大图)
这是另一个例子。在全面自动化上线之前,我们只能让一个很热的LB变得不那么热,而且多个LB之间的利用率还是存在比较大的差异,不利于LB资源的充分利用。下图中,全自动化上线后,这些不同颜色的曲线差异在9月28日到10月22日之间持续收敛,到10月25日,曲线已经非常接近了。
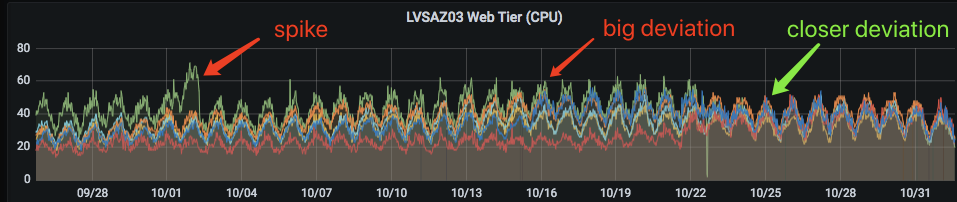
(点击查看大图)
★
新LB自动增加
以往,新LB投产后,主要通过两种方式获得负载:
通过完全自动化,这项工作变得很容易。工作负载会自动迁移到这个新的LB上,使得AZ内多个LB的负载更加均衡。我们只需要让系统“有意识地”运行即可。工程师要做的就是每天看趋势图,确认一切是否运行正常。若有异常情况,应进行相应处理。
下图中,新的LB上线后,不断接收新的VIP,流量不断增加,最终会与其他LB“会合”。
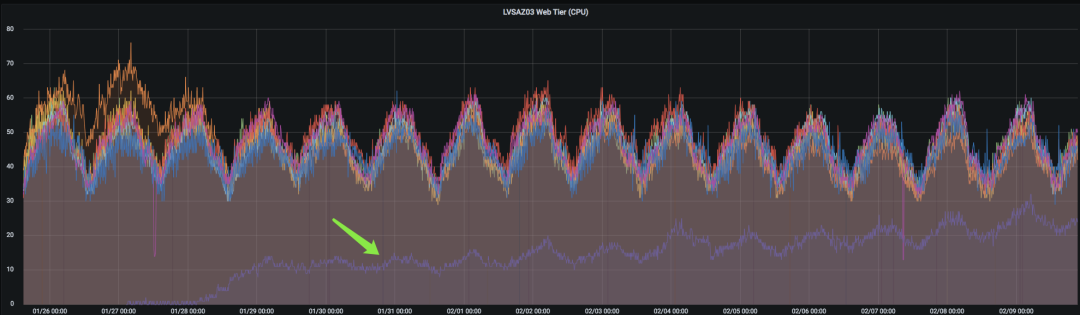
(点击查看大图)
能力
在项目进展过程中,我们涉过深浅的溪流和暗坑,并解决了它们,为后续项目铺平了道路。例如:
事实上,就在过去的一年里,我们已经完成了很多流量迁移工作,包括公网流量到SLB的迁移、新AZ的爬升、新k8s的爬升、池到池的迁移等。得益于我们能力的支持,我们能够以较低的成本完成数千个重要的迁移任务。
员工晋升
虽然放在本节的最后,但这个收获甚至比热LB全自动化本身更重要。西游四师徒到达西天后,不仅获得了西天取经的成就,更重要的是,他们每个人都修行成佛。
我们队员的能力也经历过很多“磨难”,打过怪物(不是吗?我们常说“这个问题太奇怪了!”)。我学到了以前不知道的技能,做了以前做不到的事情。更重要的是,随着项目的进展,我们看到这些原本模糊的目标变得清晰,以前不可能的任务变得可能,于是我们的自信心变得更强。
这样的团队,面对eBay更高的自动化流量管理要求以及从硬件LB到软件LB的根本演变,有信心完成一个又一个全自动化的热LB甚至更多。具有挑战性的任务。
✦
还有很长的路要走
减少热LB对时间的影响
Hot LB已经完全自动化两年了,已经完成了3800个任务。令人欣喜的是,即使达到这个数量级,仍然保持着对ATB零影响的记录。
当然,还有一些小问题。例如,有一个典型的问题:实施Web层可能会导致应用程序时间显着增加。对于时间敏感的应用程序,这有两个副作用:
为什么会导致时间增加?
正如之前提到的,GTM的模式从比率变为比率。在这种情况下,客户端原本是直接与本地数据中心的服务器通信,但在此过程中,有一定比例的请求与远程数据中心进行通信。众所周知,跨数据中心的往返时间(Round Trip Time)将会大幅增加。每增加一个往返,时间可能会增加十几毫秒。如果一笔交易需要10次往返,总时间超过100毫秒,这可能已经超出了客户端可以容忍的上限。
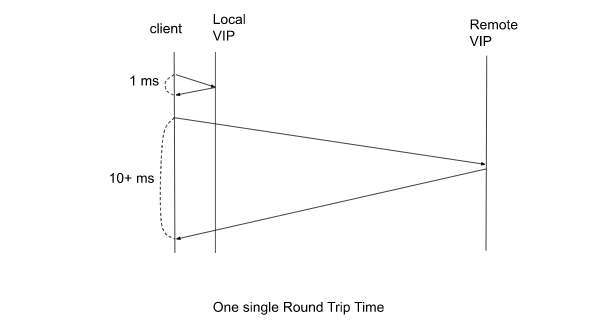
(点击查看大图)
对于这个问题,目前的短期解决方案是将这些时间敏感的应用程序添加到黑名单中,以防止它们被下一个自动化任务选中,并使用其他VIP来完成热LB。
长期计划是将Web层的具体做法改为以下迁移方式:
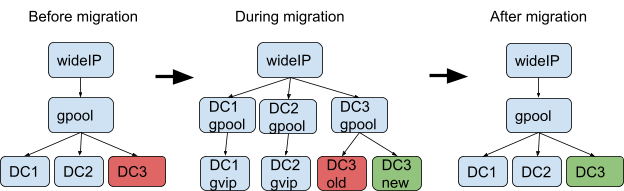
(点击查看大图)
这样的话,客户端在这个过程中会一直获取到这个数据中心的服务器IP,时间不会增加。
问题修复自动化
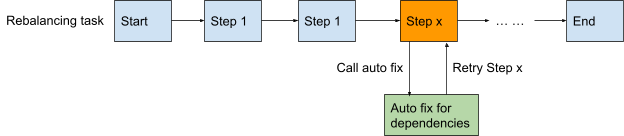
目前,当全自动任务出现故障时,需要人工干预来排除故障并修复。这部分工作仍然有效,可以探索。通过总结分类,寻找共性模式,我们也可以逐步实现修复工作的自动化。
例如,对于脏数据修复的问题,只要确定修复SOP,就可以自动化:系统首先检查故障原因。如果发现原因是脏数据,则会自动清理脏数据,然后自动重试任务。
对于依赖其他团队的修复场景,让工具自动生成相应的场景。当其他团队完成修复工作并关闭后,任务检测到该事件并自动重试,直到任务完成。
对于以上两种情况,尽量减少工程师人工干预的可能性。
(点击查看大图)
提高 API 准确性
目前我们对AP的设计比较保守,就是“即使有误报,也不要漏报负数”。当然,这和我们的业务场景密切相关:生产环境中的ATB始终是第一位的。为了保证不漏网之鱼,我们愿意为此承担额外费用。
从产品打磨的角度来看,API的准确性肯定需要持续提升。 F1 Score等指标是我们继续打磨的方向。我们要尽量减少误报,不漏掉任何一个负片,把这个基本能力打磨得更加准确。
结论
这可以算是一个小小的里程碑。过去我们已经实现了,未来还需要奋力奔向。现在是足球世界杯,我想我们的球队也是如此:
SLB(软件负载均衡)的推进工作就像前场进攻,而热LB的全自动化就像球队中的后卫和门将,确保后端(HLB)无忧。随着后场压力的减轻,前场球员可以更加集中,奋勇拼搏,最终赢得预期的胜利。
据说足球可能是在我国发明的。这也是我们古代圣人的一句话。荀子曰:“岁不寒,无以知松柏;事不艰难,无以知君子。”我想这可以成为我们工作的座右铭。当遇到困难的时候,不妨想想这句话,相信我们都会充满力量。让我们鼓励大家吧。

结尾
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 