
介绍
它是一个接收、处理和转发日志的工具。支持系统日志、日志、错误日志、应用程序日志,总之所有可以抛出的日志类型。听起来很棒,对吧?
依赖:JAVA
运行只依赖于java运行环境(jre)。可以在命令行运行java - 命令
启动和运行的两个命令示例
第一步是下载
curl -O https://artifacts.elastic.co/downloads/logstash/logstash-6.4.0.tar.gz现在您应该有一个名为 -6.4.0.tar.gz 的文件。我们来解压一下
现在让我们运行它:
现在我们可以在命令行输入一些字符,然后我们将看到输出:
hello world
2013-11-21T01:22:14.405+0000 0.0.0.0 hello world
在上面的例子中,当我们运行时,我们定义了一个名为“stdin”的输入和一个“”。无论我们输入什么字符,我们输入的字符都会以一定的格式返回。这里注意,我们在命令行上使用了-e参数,它允许直接通过命令行接受设置。这尤其快速地帮助我们反复测试配置是否正确,而无需编写配置文件。
让我们尝试一个更有趣的例子。首先,我们在命令行中使用CTRL-C命令退出之前的运行。现在我们使用以下命令重新运行:
让我们再输入一些字符,这次我们输入“moon”:
goodnight moon
{
"message" => "goodnight moon",
"@timestamp" => "2013-11-20T23:48:05.335Z",
"@version" => "1",
"host" => "my-laptop"
}
在上面的例子中,通过重置“”参数(添加“codec”参数),我们可以改变输出性能。同样,我们可以通过在你的配置文件中添加或修改,让日志数据可以随意格式化,从而定制更合理的存储格式,方便查询。
使用存储日志
现在,您可能会说:“它看起来很酷,但手动输入字符并从控制台回显它们在实践中并不实用。”说得好,接下来我们将设置存储输入日志数据。如果还没有安装,可以下载RPM/DEB包或者使用以下命令手动下载tar包:
curl -O https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-6.4.0.tar.gz
tar zxvf elasticsearch-6.4.0.tar.gz
cd elasticsearch-6.4.0/
./bin/elasticsearch
注意
本文中的示例使用 6.4.0 和 6.4.0。不同的版本有对应的推荐版本。请确认您使用的是哪个版本!
有关安装和设置的更多信息,请参阅官方网站。由于我们主要介绍入门级使用,默认的安装和配置已经满足我们的要求。
言归正传,它现在正在9200端口上运行和监听,通过简单的设置就可以作为它的后端。默认配置就足够了,我们忽略一些附加选项设置为:
输入一些随机字符,日志将像以前一样进行处理(但是这次我们不会看到任何输出,因为我们没有将其设置为选项)
我们可以使用curl命令发送请求来查看ES是否收到数据:
返回内容如下:
恭喜您已经成功使用并收集日志数据。
插件(题外话)
这里我们介绍另一个非常有用的查询数据(中等数据)的工具,称为 -kopf 插件。请参阅插件以获取更多信息。要安装-kopf,只需在安装目录中执行以下命令:
下次访问:9200//kopf 浏览保存在其中的数据、设置和映射!
多个输出
作为设置多个输出的简单示例,我们将其设置并重新运行:
当我们输入一些短语后,输入的内容将回显到我们的终端,并且也会被保存到! (可以使用curl和kopf插件来验证)。
默认配置 - 按每日日期索引
你会发现你可以灵巧地创建索引... 默认格式是-YYYY.MM.DD 每天创建一个索引。在午夜(GMT),索引会根据时间戳自动更新。我们可以根据数据回溯的时间来决定保留多少数据。当然,你也可以将较旧的数据迁移到其他地方()以方便查询。另外,如果您只是简单地删除一段时间的数据,我们也可以使用。
下一个
接下来我们开始学习更高级的配置项。在接下来的章节中,我们将重点关注一些核心功能以及如何与引擎交互。
事件生命周期
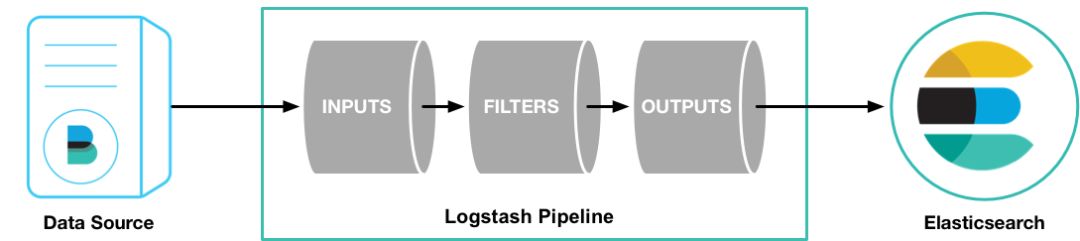
,,,构成核心配置项。通过建立事件处理管道,从日志中提取数据并存储在其中,为高效的数据查询提供基础。为了让您快速了解许多可用选项,我们首先讨论一些最常用的配置。有关更多信息,请参阅事件管道。
input和input指的是日志数据传输到哪里。常见配置如下:
充当处理链中的中间处理组件。它们通常组合起来实现特定的行为,以处理匹配特定规则的事件流。常见的有以下几种:
它是处理管道的最后一个组件。一个事件在处理过程中可以经历多个输出,但是一旦所有输出都被执行,该事件就完成了它的生命周期。一些常用的包括:
是一个基于数据流的过滤器,可以配置为输入的一部分。它可以帮助您轻松拆分发送的序列化数据。流行的包括 json、plain(text)。
完整的配置信息请参考文档的“ ”部分。
使用配置文件获得更多有趣的内容
在命令行中使用-e参数指定配置是一种常见的方式,但如果需要配置更多设置,则需要很长时间。本例中,我们首先创建一个简单的配置文件,并指定这个配置文件的用途。例如,我们创建一个文件名为“-.conf”的配置文件,并将其保存在与.conf相同的目录中。内容如下:
input { stdin { } }
output {
elasticsearch { host => localhost }
stdout { codec => rubydebug }
}
接下来,执行命令:
我们看到,根据刚刚创建的配置文件来运行示例会更加方便。请注意,我们使用 -f 参数从文件获取配置,而不是使用 -e 参数从命令行获取配置。上面的演示是一个非常简单的例子。当然,分析完之后我们还会继续写一些更复杂的例子。
筛选
它是一种行处理机制,将提供的格式化数据组织成您需要的数据。让我们看下面的一个例子,一个名为 grok 的过滤器。
input { stdin { } }
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
elasticsearch { host => localhost }
stdout { codec => rubydebug }
}
执行遵循以下参数:
现在将以下行粘贴到您的终端中(这当然会处理标准输入):
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 