
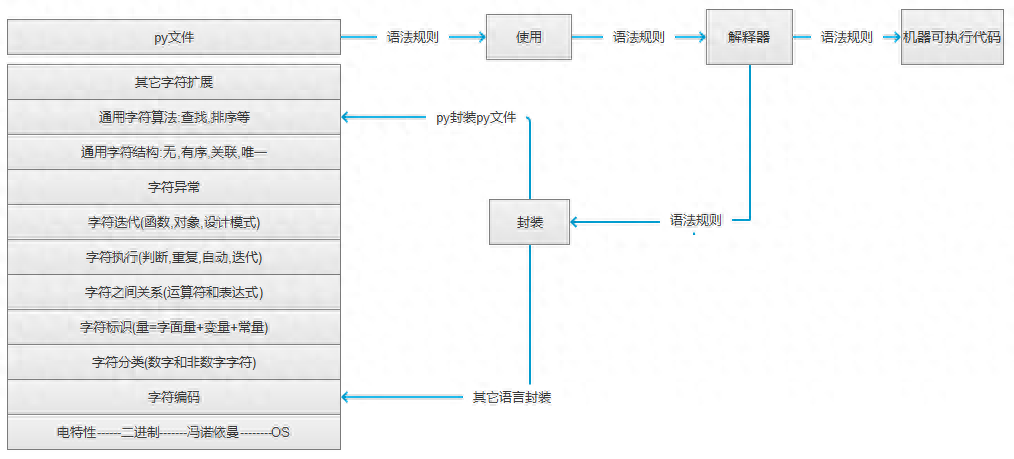
字符编码:
编码,编译成01;解码:将01转换成人类可以识别的字符;乱码:无意义的字符;
计划:
要点:编码和解码一致;
字符集(key-value):key指的是01,value指的是字符;
字符编码原理:解释器将内存中的所有字符进行转换;由于它兼容所有字符集,因此可以作为其他字符转换的中转站;
具体流程:
第一阶段:解释器启动,相当于启动一个文本编辑器。
第二阶段:解释器相当于一个文本编辑器打开test.py文件,将test.py文件内容从硬盘读取到内存中; pyhon的可解释性决定了解释器只关心文件内容而不关心文件内容。关心文件后缀名;
第三阶段:解释器解释并执行刚刚加载到内存中的test.py的代码(ps:这个阶段,也就是代码真正执行的时候,会识别语法,将文件中的代码当执行 name="egon" 时,会开辟内存空间来存储字符串“egon”)
以下两种场景涉及到字符编码问题:
1、文件中的内容是由一堆字符组成的,访问涉及字符编码问题(文件不执行,前两个阶段属于此类)
这时解释器会读取test.py的第一行#:utf-8,来确定读入内存的编码格式。该行是设置解释器软件使用的编码格式。可以使用 sys.() 查看该编码。如果文件中没有指定头信息#-*-:utf-8-*-,则使用默认的,中默认使用ascii,中默认使用utf-8;
2. 中的数据类型由一串字符组成(文件执行时,即第三阶段)
在程序执行之前,一切确实都在内存中。例如,从文件中读取行 x="egon"。 x、等号和引号具有相同的状态。它们只是普通字符,以该格式存储在内存中;但在程序执行过程中,它会申请内存(与程序代码所在的内存是两个空格)来存储数据类型的值,而字符串类型涉及到x=”等字符的概念egon”将被解释器识别为字符串,并分配内存空间来存储字符串类型值。至于字符串类型值采用何种编码方式进行识别和存储,这与解释器有关。和 的字符串类型不同。
文件中存储的文件的编码格式需要与解释器的编码格式一致,否则无法正常工作;从硬盘解码到内存;
在py3中,也会转为bytes类型,解码时会转回bytes;
中的str类型是bytes类型;
py2:只要是ascii编码范围内的字符对象,在进行字符串操作时,都会默认从bytes存储转移到;
汉字及其他非ascii编码的字符在存储时会被py2转换为字节存储;
print '元昊' # 苑昊
print repr('袁浩') #'\xe8\x8b\x91\xe6\x98\x8a'
print (u"你好"+"元")
#print(u'元浩'+'最帅')#: 'ascii'编解码器无法字节0xe6
# in 0: 不在范围内(128)
py3:文本总是用str类型表示,二进制数据用bytes类型表示。 3 不以任何隐式方式混合str和bytes;
json
s='元浩'
打印(类型)#
print(json.dumps(s)) # "\u82d1\u660a"
b=s.('utf8')
打印(类型(b))#
print(b) # b'\xe8\x8b\x91\xe6\x98\x8a'
u=b.('utf8')
打印(类型(u))#
print(u) #苑昊
print(json.dumps(u)) #"\u82d1\u660a"
print(len('袁浩')) #
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 