
1. 背景
目前,AI算法的开发,尤其是训练环节,主要依赖某种技术。主流的AI计算框架,诸如和,均提供了多样化的接口。常言道,人生短暂,我选择效率。然而,由于作为动态语言,其解释执行缺乏成熟的即时编译方案,且在计算密集型场景中,多核并发能力受限,因此难以直接满足对实时服务性能的高要求。在性能要求较高的特定场合,依然有必要采用C/C++进行开发。然而,若算法团队必须全面采用C++来构建线上推理服务,其成本将极为高昂,进而影响开发效率并造成资源浪费。鉴于此,若能找到一种简便的方法,将C++编写的部分核心代码与其它技术融合,便能在确保开发效率的同时,维护服务性能。本文重点阐述了腾讯广告多媒体AI算法的加速实施情况,并对实施过程中的诸多经验进行了归纳总结。
2. 业内方案2.1 原生方案
官方推出了/C API,该API允许使用C语言来创建库,下面先展示一段示例代码,让大家体会一下:
static PyObject *
构建spam检测系统,函数名为spam_system,接收两个参数:PyObject *self和PyObject *args。
{
const char *command;
int sts;
若无法解析参数组(args),且格式不符合字符串("s"),则无法获取命令(command)的指针。
return NULL;
sts = system(command);
return PyLong_FromLong(sts);
}显而易见,改造所需的成本相当高昂,因为所有的基础类型都需要被逐一转换成由解释器封装的绑定类型。因此,这一点可以很好地解释为什么官方网站上会推荐大家采用第三方解决方案[1]。
2.2 赛通
主要目标在于打通与C和C++的连接,以利于为C++编写扩展。这有助于将代码转换为C代码,而这些C代码能够访问/C的API。本质上,它是一个包含C数据类型的库。目前,numpy以及我们厂的tRPC-框架都有所应用。
缺点:
2.3 SIWG
SIWG 主要针对高级语言与C和C++之间的交互问题进行解决,兼容包括Java、C#在内的十余种编程语言。在使用过程中,需通过*.i文件来定义接口,并借助工具生成跨语言交互的代码。然而,由于它支持的语言种类繁多,导致其在性能表现上相对不尽如人意。
特别需要指出的是,在早期阶段,我们确实采用了SWIG进行接口的封装,然而,由于SWIG在性能上不尽如人意、构建过程繁琐复杂以及绑定的代码难以理解等问题,我们已于2019年将其替换为[2]。
2.4 Boost.
C++领域广泛使用的Boost开源库,同样具备此类功能。在应用层面,它通过宏定义与元编程技术,极大地简化了API的调用过程。然而,其最大的不足之处在于必须依赖庞大的Boost库,这使得编译过程和依赖关系变得复杂,若仅为了解决绑定问题,似乎有些大材小用,如同用高射炮打蚊子一般。
2.5 吡宾德11
可以视为以Boost为参照,仅具备C++功能的简化版本,相较于Boost,它在体积和编译效率方面展现出显著优势。对C++的兼容性极佳,依托C++11标准,充分利用了众多新特性,或许“11”这一后缀正是缘于此。
利用C++编译过程中的自我检查功能,推断出类型信息,以此尽可能降低在传统模块扩展过程中所需编写的大量模板代码,同时,它还支持对常见数据类型,例如STL数据结构、智能指针、类、函数重载以及实例方法的自动转换,这些转换允许函数接收并返回自定义数据类型的值、指针或引用。
特点:
"说话很便宜,给我看看你的代码。
定义模块libcppex,并在其中声明变量m。
定义了一个名为"add"的函数,其接受两个整数参数a和b,通过调用该函数,可以返回它们的和。具体实现如下:m.def("add", [](int a, int b) -> int { return a + b; });
}3. 调C++3.1 从 GIL 锁说起
GIL(全局解释器锁)机制规定,在单个进程中,同一时间仅允许一个线程访问解释器,这限制了多线程在多核处理器上的实际效能。然而,当线程执行I/O密集型函数或进行其他等待操作时,会自动释放GIL锁,因此,对于这类服务,采用多线程策略仍能取得一定效果。针对CPU密集型任务,鉴于每个周期内仅能允许一条线程实际进行计算,其对性能的潜在影响不言而喻。

这里需要明确指出,GIL并非本身的瑕疵,而是源于当前默认采用的解析器所采用的线程安全保护机制。通常所说的GIL锁问题,实际上仅限于解释器层面。若能找到绕过GIL锁的方法,或许能够实现显著的性能提升。结果明确无疑,一个可行的办法是转向使用诸如 pypy 这样的其他解释器,然而这种方法在处理成熟的 C 扩展库时表现不佳,且维护费用较高。还有另一种途径,即通过 C/C++ 扩展技术将计算密集型的代码部分进行封装,并在程序执行过程中解除 GIL 锁。
3.2 算法性能优化
该接口允许在 C++端手动解除 GIL 锁,故此,我们只需将密集计算的相关代码转换为 C++版本,并在执行前释放、执行后获取 GIL 锁,算法的多核处理能力便得以释放。自然,除了展示如何通过接口来解除 GIL 锁之外,我们还可以在 C++环境中,将计算密集的部分代码交由其他 C++线程进行异步处理,这样同样能够绕过 GIL 锁的限制,实现多核的利用。
以城市间球面距离的100万次计算为例,进行C++扩展前后的性能差异比较:
C++端:
#include
#include
#include
#include
namespace py = pybind11;
定义一个名为pi的浮点型变量,其值为3.1415926535897932384626433832795。
double rad(double d) {
return d * pi / 180.0;
}
定义函数double geo_distance,该函数接受五个参数:经度lon1、纬度lat1、经度lon2、纬度lat2和测试次数test_cnt。
py::gil_scoped_release release; // 执行GIL锁的释放操作
double a, b, s;
double distance = 0;
for (int i = 0; i < test_cnt; i++) {
double radLat1 = rad(lat1);
double radLat2 = rad(lat2);
a = radLat1 - radLat2;
b = rad(lon1) - rad(lon2);
s = pow(sin(a/2),2) + cos(radLat1) * cos(radLat2) * pow(sin(b/2),2);
distance = 2 * asin(sqrt(s)) * 6378 * 1000;
}
py::gil_scoped_acquire acquire; // C++执行结束前恢复GIL锁
return distance;
}
PYBIND11_MODULE (libcppex, m) {
m.def("geo_distance", &geo_distance, R"pbdoc(
Compute geography distance between two places.
)pbdoc");
} 调用端:
import sys
import time
import math
import threading
from libcppex import *
def rad(d):
返回值等于d乘以圆周率π,再除以180.0。
定义一个名为geo_distance_py的函数,该函数接受五个参数:lon1、lat1、lon2、lat2和test_cnt。
distance = 0
for i in range(test_cnt):
radLat1 = rad(lat1)
radLat2 = rad(lat2)
a = radLat1 - radLat2
b = rad(lon1) - rad(lon2)
s 等于正弦函数(a/2)的平方加上余弦函数(radLat1)乘以余弦函数(radLat2)再乘以正弦函数(b/2)的平方。
距离等于2倍的正弦值(以弧度为单位)乘以平方根(s)再乘以6378千米,最后再乘以1000。
print(distance)
return distance
创建函数以调用C++扩展模块,其中包含参数lon1、lat1、lon2、lat2和test_cnt。
执行地理距离计算,其中输入参数分别为lon1、lat1、lon2和lat2,并考虑测试次数test_cnt,得到结果res。
print(res)
return res
if __name__ == "__main__":
threads = []
test_cnt = 1000000
test_type = sys.argv[1]
thread_cnt = int(sys.argv[2])
start_time = time.time()
for i in range(thread_cnt):
if test_type == 'p':
创建了一个名为t的线程,其目标函数为geo_distance_py,以执行地理距离计算任务。
参数设定为:(113.973129, 22.599578, 114.3311032, 22.6986848, 测试次数,)
当测试类型等于字母“c”时:
创建了一个线程对象t,其目标函数为调用C++扩展模块。
args=(113.973129, 22.599578, 114.3311032, 22.6986848, test_cnt,))
threads.append(t)
t.start()
for thread in threads:
thread.join()
输出:“计算耗时为%d毫秒”,其中%d代表将当前时间与起始时间的差值乘以1000后的整数值。性能对比:
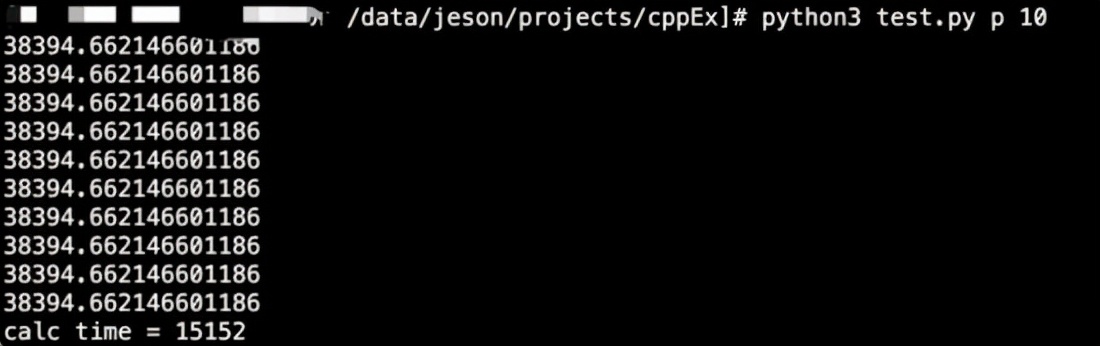
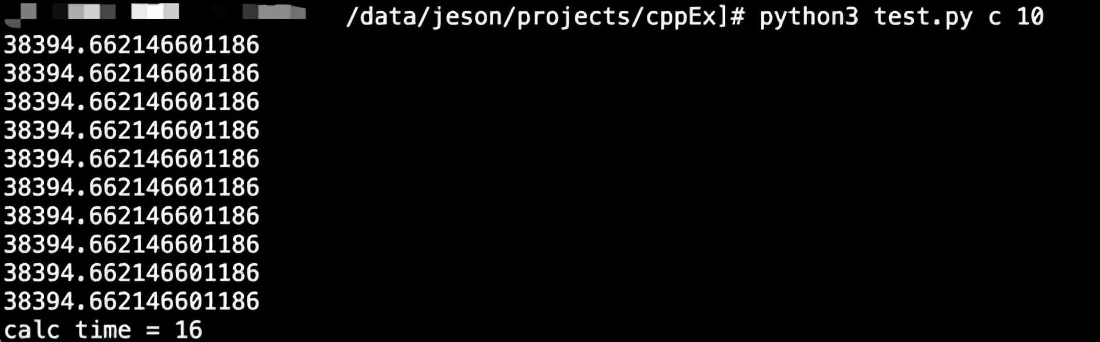
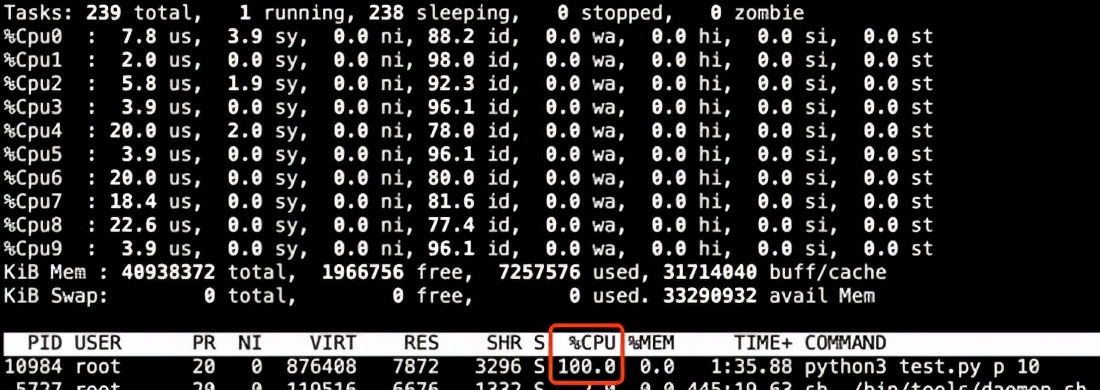
多线程无法同时刻多核并行计算,仅相当于单核利用率
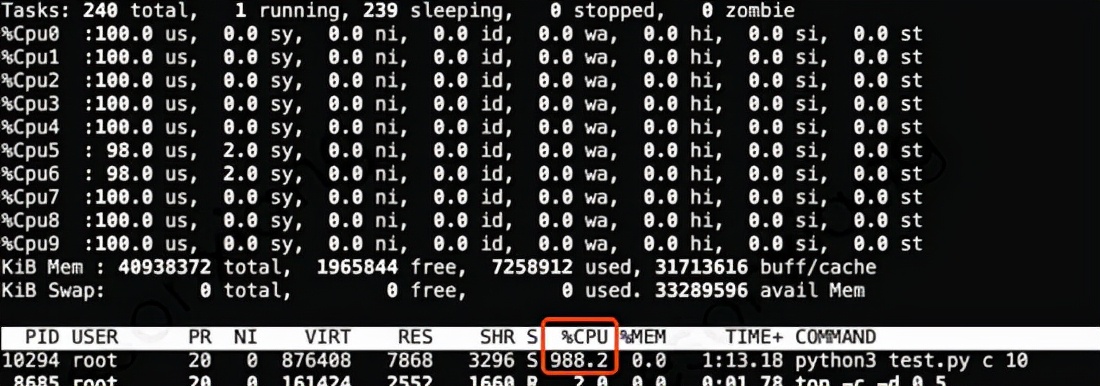
C++可以吃满 机器的 10 个 CPU 核
结论:
计算密集型程序若采用C++进行编写,便能显著提高执行效率;借助多线程技术解除GIL锁的限制,能够更充分地利用多核处理器,实现性能的线性增长,从而大幅度增强资源的使用效率。尽管在现实应用中,多进程技术同样能够发挥多核处理器的优势,然而随着模型规模的不断增大,动辄达到数十吉字节,不仅内存消耗巨大,而且进程间频繁的切换以及编程语言自身性能的不足,这些因素使得其与C++扩展方法相比,仍存在较大的差距。
请注意,此测试的演示地址为//c1,测试所采用的硬件环境是拥有10核处理器的容器,有兴趣的朋友们不妨亲自进行性能测试。
3.3 编译环境
编译指令:
使用g++编译器,加入-Wall警告选项,设置共享库编译标志,采用GNU++11标准,优化等级为2,隐藏符号可见性,启用位置无关代码,指定头文件搜索路径为当前目录下的perfermance.cc,并输出名为libcppex.so的库文件,同时使用Python3-config工具获取编译和链接所需的各种标志和库。如果 环境未正确配置可能报错:
此处的依赖关系通过“--libs”参数自动设定,您可以通过单独执行该命令来检验依赖项的配置是否准确无误。若依赖项配置无误,执行依赖项的“-dev”版本,可依照以下指令进行安装:
yum -devel
4.C++调
通常情况下,这类封装主要用于C++代码的端接口设计,然而,C++端调用也是可行的。只需使用#。
头文件可以直接应用,其内部功能是通过集成解释器来实现的。操作起来相当简便,且具有良好的可读性,与直接调用接口的使用方式极为相似。例如,针对 numpy 数组执行某些操作,可以参照以下示例:
// C++
pyVec执行了transpose方法,得到了转置的结果,接着又调用了reshape方法,将转置后的结果重新塑形,最终得到的形状与pyVec的原始尺寸相同。
# Python
pyVec等于pyVec进行转置操作后的结果,再通过reshape方法将其重塑为与原pyVec相同大小的形状。以我们自主开发的C++ GPU高效版本抽帧工具为例,此工具不仅向用户提供可供调用的抽帧接口,而且还需通过回调机制向相关端发送通知,以便告知抽帧的进展情况以及帧数据的更新。
端回调接口:
设定解码回调函数,参数包括任务标识符(字符串类型)和进度(整数类型)。
输出信息显示解码回调函数执行,任务编号为:%s,当前进度为:%d。
if __name__ == "__main__":
decoder = DecoderWrapper()
decoder注册了Python回调函数,该函数位于当前工作目录下的"decode_test.py"文件中。
"on_decoding_callback")C++端接口注册 & 回调 :
#include
DecoderWrapper类中,对Python回调函数的注册操作通过指定Python脚本路径来实现,具体为:使用py_path参数来标识Python脚本文件的位置。
构造函数接受一个字符串引用,名为func_name,用于指定函数名称。
int ret = 0;
获取Python模块路径后,将其存储在名为pyPath的字符串引用中。
获取模块名称后,将其存储在名为pyName的字符串引用中,该名称通过调用py_get_module_name函数并传入py_path参数获得。
SoInfo显示获取到的Python模块名称为:%s,路径信息为:%s,具体名称是pyName的内容,路径则是pyPath的内容。
获取Python全局解释器锁的操作已执行,acquire变量被成功创建。
导入模块sys,将其对象赋值给py::object类型的变量sys。
sys.attr("path").attr("append")(py::str(pyPath.c_str())); 这行代码设置了Python脚本的路径。
通过导入指定的名称,创建了名为pyModule的Python模块对象;该操作是通过调用py::module的import方法实现的,其中pyName是以字符形式提供的。
if (pyModule == NULL) {
记录错误信息:“无法加载pyModule模块。”
在执行代码时,需要使用py::gil_scoped_release来释放全局解释器锁;同时,应当创建一个release对象来确保锁的释放操作得到正确执行。
返回错误代码,表示找不到指定的Python文件。
}
若pyModule对象具有func_name字符串所表示的属性。
} else {
返回值设为PYTHON函数未找到错误码;
}
在代码中,我们执行了以下操作:首先声明了一个名为release的变量,接着将其定义为py::gil_scoped_release类型。
return ret;
}
在解码监听器类中,执行on_decoding_progress函数,接收任务ID字符串引用以及进度整数,以处理解码过程中的实时更新。
if (py_callback != NULL) {
try {
获取Python全局解释器锁的操作已执行,使用py::gil_scoped_acquire进行封装。
执行py_callback函数,传入任务ID和进度信息。
py::gil_scoped_release release;
捕获到Python错误已设置的情况,处理py::error_already_set类型的异常。
记录错误("捕获到Python异常:%s", PythonErr.getWhat());
捕获到std::exception类型的异常对象e后,{
记录错误信息:“捕获到异常:%s”,e.what();
} catch (...) {
记录错误信息:“捕获到未知的异常情况”
}
}
} 5. 数据类型转换5.1 类成员函数
在处理类与成员函数的关联时,首先必须创建一个对象,这一过程分为两个阶段:首先,需对实例的构造函数进行封装;其次,要设定成员函数的调用机制。此外,还允许使用特定方式来绑定静态方法或成员变量,具体操作方法可查阅官方文档[3]。
#include
class Hello
{
public:
Hello(){}
定义一个函数,名为say,该函数接受一个字符串类型的参数s。
std::cout << s << std::endl;
}
};
PYBIND11_MODULE(py2cpp, m) {
m.doc() = "pybind11 example";
pybind11::class_(m, "Hello")
定义了pybind11的初始化函数,这相当于C++中的类构造函数。若未声明或参数错误,将导致调用失败。
.def( "say", &Hello::say );
}
/*
Python 调用方式:
c = py2cpp.Hello()
c.say()
*/ 5.2 STL 容器
支持STL容器间的自动转换功能,在处理STL容器时,仅需额外引入相应的头文件即可。
提供的转换包括:将std::list和std::array转换为list;将std::set转换为set;将std::map转换为dict。此外,std::pair和std::tuple的转换也在其中。
头文件中提供了。
#include
#include
#include
class ContainerTest {
public:
ContainerTest() {}
void Set(std::vector v) {
mv = v;
}
private:
std::vector mv;
};
定义模块 py2cpp,并对其内容进行初始化,命名为 m。
m.doc() = "pybind11 example";
pybind11::class_(m, "CTest")
.def( pybind11::init() )
定义函数 "set",并将其与成员函数 ContainerTest::Set 相关联。
}
/*
Python 调用方式:
c = py2cpp.CTest()
c.set([1,2,3])
*/ 5.3 字节、字符串类型传递
在中,字符串类型默认采用UTF-8编码方式,若将C++端传递的字符串类型数据传输至,将引发“:'utf-8' 编解码器无法解析字节0xba,位于位置0:无效起始字节”的错误提示。
该方案提供了针对非文本数据的绑定类型,具体为py::bytes。
m.def("return_bytes",
[]() {
字符串s被赋予了一个包含非法UTF-8编码的字节序列"\xba\xd0\xba\xd0"。
返回数据,不进行任何编码转换,直接以py::bytes的形式输出。
}
);5.4 智能指针
std::unique_ptr定义函数create_example,其返回值类型为std::unique_ptr(new Example()); }
定义函数“create_example”,函数实现由“&create_example”引用。 class Child { };
class Parent {
public:
Parent类在初始化时,通过std::make_shared创建了一个指向child成员的智能指针。()) { }
获取子对象的方法:child对象通过get_child()函数返回其值,但请注意,不建议采取这种方式。
private:
std::shared_ptr child;
};
PYBIND11_MODULE(example, m) {
py::class_>(m, "Child");
py::class_>(m, "Parent")
.def(py::init<>())
定义函数名为"get_child",并将其与父类中的"get_child"方法关联;
} 5.5 cv::Mat 到 numpy 转换
当抽帧结果被发送至终端时,鉴于当前版本尚不能自动实现 cv::Mat 数据结构的转换,我们必须手动完成 C++ cv::Mat 与终端端 numpy 数据之间的关联。以下是转换所需的代码:
/*
Python->C++ Mat
*/
将numpy的uint8三通道数组转换为OpenCV的Mat对象,通过函数cv::Mat numpy_uint8_3c_to_cv_mat(py::array_t)实现。& input) {
if (input.ndim() != 3)
抛出异常,提示:“三通道图像必须是三维的。”
获取输入请求后,py::buffer_info 类型的变量 buf 被赋值。
创建了一个名为mat的Mat对象,其行数与buf的行数相同,列数与buf的列数一致,数据类型为CV_8UC3,且其内部数据指针指向buf指针所指向的uint8_t类型数据。
return mat;
}
/*
C++ Mat ->numpy
*/
py::array_t将输入的cv::Mat类型数据转换为numpy数组,函数名为cv_mat_uint8_3c_to_numpy,参数为指向cv::Mat对象的引用。
py::array_t dst = py::array_t输入参数包括行数、列数、数值3,以及输入数据。
return dst;
} 5.6 零拷贝
通常情况下,跨语言调用会带来性能上的损耗,尤其是在处理大数据块传输时。为此,一些技术方案也引入了数据地址传递的方法,这样可以有效避免大数据块在内存中的复制操作,从而在性能上实现了显著提升。
class Matrix {
public:
Matrix构造函数接受行数和列数作为参数,并将行数赋值给成员变量m_rows,列数赋值给成员变量m_cols。
初始化一个长度为rows乘以cols的float类型数组,命名为m_data。
}
提供数据指针函数,函数返回指向成员变量m_data的指针。
获取行数:m_rows成员变量所存储的值即为行数。
获取列数的方法是调用cols函数,它是一个const成员函数,返回类型为size_t,具体数值由成员变量m_cols提供。
private:
size_t m_rows, m_cols;
float *m_data;
};
py::class_接受参数m,表示矩阵,通过py::buffer_protocol()接口进行操作。
定义一个函数,该函数接受一个Matrix类型的引用m作为参数,返回一个py::buffer_info类型的对象。
return py::buffer_info(
指向数据缓冲区的指针,m.data(),禁止修改。
float类型的数据大小,即单个标量的大小。
py::format_descriptor定义格式化函数,类似Python中的结构化格式描述符。
第2项,即维度的数量。
m的行数和列数,即缓冲区的尺寸。
每个索引的字节跨度为 sizeof(float) 乘以 m.cols()。
sizeof(float) }
);
}); 6. 落地 & 行业应用
该方案已成功应用于广告多媒体AI的色彩提取服务、GPU高性能抽帧等算法领域,实现了显著的加速效果。在业界,目前市场上的多数AI计算框架,包括但不限于阿里X-深度学习、百度等,普遍采用某种方式来实现C++至某种端口的接口封装,其稳定性和性能已获得广泛认可。
7. 结语
在人工智能领域,开源节流、降低成本、提高效率已成为普遍趋势。在这种背景下,如何有效运用现有资源,提高资源使用效率显得尤为重要。本文提出了一种简便易行的方法,旨在提升算法服务的性能和CPU的利用率,且该方法在线上应用中已取得显著成效。
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 