
[]
前言
数据库拆分是中高级开发者需要处理的任务,但具体操作还需根据企业实际情况来定。各种情形都可能发生,本文将围绕Mycat展开数据库拆分的实现方法。至于拆分的核心理念,将在后续文章中详细阐述。在此,我们先简要概述,暂不讨论其优缺点,读者在实践或阅读过程中可自行体会,大致可分为两大类:
分库分表这项技术看似强大,但在实际项目操作中,往往无需采用,甚至不进行分库分表可能更为适宜!
垂直拆分-分库
垂直分库是指依据业务间的相互依赖程度,将那些相互关联性较小的多个表格分散存储至不同的数据库中。这一做法与将大型系统拆分成若干个小系统的策略相仿,都是依据业务类别进行独立分割。它和“微服务治理”的实践相呼应,即每一个微服务都配备了一个专用的数据库。
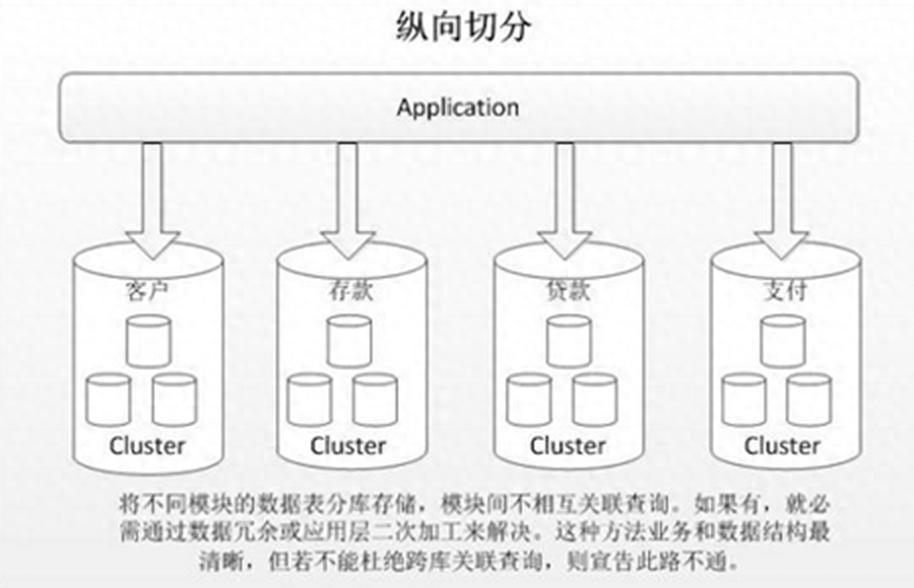
垂直拆分-分表
在数据库操作中,垂直分表是按照“列”来进行的。若某个表的字段数量较多,我们可以创建一个新的扩展表。这样,可以将那些不常使用或字段长度较大的字段从原表中分离出来,并放置到这个扩展表中。当涉及众多字段时,比如一个包含超过100个字段的庞大表格,采用“大表拆小表”的策略将大大提升开发与维护的便捷性。此外,这种方法还能有效规避跨页现象。须知,MySQL系统底层是以数据页的形式进行数据存储的,若单条记录占用的空间过大,便可能引发跨页,进而增加不必要的性能损耗。此外,数据库以行为基准将数据导入内存,由于表中字段长度较短且被频繁访问,内存能够容纳更多的数据,提高了数据检索的命中率,进而降低了磁盘输入输出的次数,有效提升了数据库的整体性能。

水平拆分
当一款应用难以进一步在细小的垂直方向上进行分割,或者分割后数据量庞大,导致单个数据库在读写和存储方面出现性能限制时,便有必要采取水平切分的方式。
水平切分涉及库内分表与分库分表两种方式,这一过程依据表中数据的内在逻辑关系,将单一表中的数据根据特定条件分散至多个数据库或不同的表中。每个单独的表仅承载部分数据,这样做可以有效减小单个表的数据量,进而实现数据分布的效果。具体如图所示:

库内分表仅针对单个表数据量庞大这一问题有所缓解,然而并未实现将表分散至不同机器库中的目的。故此,其对减轻MySQL数据库压力的效用有限。大家依然在争夺同一物理机的CPU、内存和网络I/O资源。因此,最理想的解决方案还是采用分库分表策略。
垂直拆分-分库实现方式配置mycat的配置文件
select user()
select user()
在两个mysql实例中分别创建数据库
CREATE DATABASE orders;登陆Mycat创建四张表
-- 用户表,假如有20W用户
CREATE TABLE customer(
id INT AUTO_INCREMENT,
NAME VARCHAR(20),
PRIMARY KEY (id)
);
-- 订单表,假如有2000W个订单
CREATE TABLE orders(
id INT AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY (id)
);
-- 订单详情表,数据量和订单表一样
CREATE TABLE order_detail(
id INT AUTO_INCREMENT,
detail VARCHAR(20),
order_id INT,
PRIMARY KEY (id)
);
字典表中,若数据量达到20条,则与订单类型相对应的字典会以数字来表示类型说明,而订单表中仅需存储这些数字即可。
CREATE TABLE dict_order_type(
id INT AUTO_INCREMENT,
order_type VARCHAR(20),
PRIMARY KEY (id)
);查看表
正如图中所示,完成Mycat的创建后,Mycat界面能够成功查询到四张表格,其中一张位于上方,另外三张也排列在上方,这与我们预期的效果完全一致。

水平拆分-分库分表
我们注意到order表以及另一张表中的数据量极其庞大,若将它们存放在同一节点上的同一数据库中,性能将遭受影响。鉴于此,我们计划将order表和该表拆分,并将全量数据分布式存储,均匀分布在两个节点上。
切片规则
配置mycat的.xml配置文件
select user()
select user()
配置rule.xml配置文件
customer_id
mod-long
2
在dn2服务器上构建数据表,随后对mycat进行重启操作,并成功登录mycat后向该表中添加数据。
我们之前曾提到,在SQL语法中,表名后的字段名是可以省略的。然而,在mycat进行分库分表的场景下,添加数据时则不能省略字段名,这是因为必须明确指出哪一列数据对应的是customer_id。
向订单表插入一条数据,其中订单编号为1,订单类型为101,客户编号为100,订单金额为100100元。
向订单表插入一条数据,其中订单编号为2,订单类型为101,客户编号为100,订单金额为100300元。
向订单表插入一条记录,其中订单编号为3,订单类型为101,客户编号为101,订单金额为120000元。
向订单表插入数据,其中订单编号为4,订单类型为101,客户编号为101,订单金额为103000元。
向订单表插入数据,其中订单编号为5,订单类型为102,客户编号为101,订单金额为100400元。
向订单表插入数据,其中订单编号为6,订单类型为102,客户编号为100,订单金额为100020元。
从图中可以观察到,向mycat中插入了六条数据,在mycat端进行查询时,能够查到全部数据,但显示的顺序并非依据id进行排列。若需实现数据的有序展示,可以通过使用order by子句进行排序。通过这种方式,我们可以在查询时分别检索出三条数据,从而实现了数据的横向拆分。
水平拆分的join关联查询
观察图表可知,当我们执行join内关联查询时,系统会提示表无法找到;既然我们对主表进行了切分,相应的,我们也需要对从表进行切分并配置。
.xml文件
在dn2上创建表,重启mycat插入数据再做查询
-- 插入数据和查询都是在mycat端操作
-- 插入数据
向订单详情表中插入一条记录,其ID为1,详情内容为'detail',所属订单ID为1。
向订单详情表中插入一条记录,其ID为2,详情内容为'detail',所属订单ID为2。
向订单详情表插入一条记录,其ID为3,详情内容为'detail',所属订单ID为3。
向订单详情表中插入一条新记录,记录编号为4,详情内容为'detail',所属订单编号为4。
向订单详情表中插入一条新记录,其ID为5,详情内容为'detail',所属订单ID为5。
向订单详情表插入数据,指定字段id为6,字段detail的值为'detail',字段order_id的值为6。
-- 连接查询
从订单表中选择所有数据,与订单详情表进行内连接,连接条件为订单表的主键与订单详情表的订单ID相等。
至此,我们的纵向与横向分割工作已暂告一段落,然而,这并非终点,实在令人难以置信,怎么还没结束?心态都快崩溃了。不过,大家别慌,还是按照老规矩,来杯茶,咱们接着干。
全局表
在业务表中,当数据量庞大时,往往需要进行切分处理。然而,即便是一些附属表,例如我们这里的字典表,它们之间也需要建立关联。值得注意的是,字典表的数据量并不大,且数据变动并不频繁,因此进行切片操作并不必要。在Mycat中,这类表被定义为全局表。
特点
修改.xml配置文件
保存在dn2上创建字典表,重启mycat
向字典订单类型表中插入一条记录,其中id字段值为101,order_type字段值为'type1'。
向字典订单类型表中插入一条记录,其中ID为102,订单类型为“type2”。我们检查了数据,发现dn1和dn2上都有两条完整的数据,尽管存在数据重复的情况,幸运的是,这些表中的数据量并不大,因此无需进行数据切分即可直接进行JOIN操作。
常用分片规则
在上面的示例中,我们在进行数据分割时采用了取余数的方法,接下来,我将详细介绍在开发过程中常见的其他数据分割手段。
枚举分片
在配置文件中需设定可能涉及的枚举标识符,自行设定数据分片规则,例如依据省份或县级行政区划分存储。鉴于我国全国范围内的省份和县级行政区划是既定的,这些规则适用于此类场景。
修改.xml配置文件
修改rule.xml配置文件
areacode
hash-int
......
partition-hash-int.txt
1
0
修改-hash-int.txt配置文件
110=0
120=1重启mycat,创建表插入数据
-- 创建表
创建一个名为orders_ware_info的表结构。
id INT AUTO_INCREMENT,
order_id INT,
address VARCHAR(20),
areacode VARCHAR,
PRIMARY KEY(id)
);
-- 插入数据
向orders_ware_info表插入数据,具体包括id字段为1,order_id字段为1,地址字段为'北京',区域代码字段为'110'。
向订单商品信息表插入数据,其中id为2,order_id为2,地址为天津,区域代码为120。
查询结果显示,在mycat系统中检索到的信息包括两条记录,其中一条位于北京,另一条则位于天津。
范围约定分片
例如,针对我们的用户标识符,我们将其中的0至、至等数字按照一定的区间进行存储,这种做法适用于那些事先已确定范围的应用场景。在此,我们以支付信息表作为具体的应用实例。
配置.xml文件
配置rule.xml配置文件
order_id
rang-long
......
autopartition-long.txt
0
修改-long.txt文件
注意:将原本有的配置删除
0-102 = 0
103-200=1重启mycat,创建表,插入数据
CREATE TABLE payment_info(
id INT AUTO_INCREMENT,
order_id INT,
payment_status INT,
PRIMARY KEY (id)
);
向payment_info表插入数据,其中id为1,order_id为101,payment_status为0。
向payment_info表中插入数据,具体为:id字段值为2,order_id字段值为102,payment_status字段值为1。
向payment_info表插入数据,具体为:id字段值为3,order_id字段值为103,payment_status字段值为0。
向payment_info表插入数据,其中id字段值为4,order_id字段值为104,payment_status字段值为1。
观察mycat,我们发现其能够检索全部数据,具体来说,在某个平台展示了其中两条,而在另一个平台也展示了另外两条,同时数据的分布情况也是准确的。
按照日期分片
我们按照天进行划分,设定时间格式、范围
修改.xml配置文件
修改rule.xml配置文件
login_date
shardingByDate
......
yyyy-MM-dd
2020-04-01
2020-04-04
2
重启Mycat,创建表插入数据
CREATE TABLE login_info(
id INT AUTO_INCREMENT,
user_id INT,
login_date date,
PRIMARY KEY (id)
);
向login_info表插入数据,指定id为1,user_id为101,login_date为“2020-04-01”。
向login_info表插入数据,指定id为2,user_id为102,login_date为“2020-04-02”。
向login_info表插入一条数据,其中id字段值为3,user_id字段值为103,login_date字段值为“2020-04-03”。
向login_info表插入数据,其中id字段值为4,user_id字段值为104,login_date字段值为“2020-04-04”。
向登录信息表插入一条记录,其中ID为5,用户ID为103,登录日期为2020年4月5日。
向login_info表插入一条数据,其中id字段值为6,user_id字段值为104,login_date字段值为2020年4月6日。
观察结果可知,前四份数据因超出了截止日期而需重新划分区域,而对于后两份数据,大家可以依据个人意愿进行操作,检验其效果是否与预期相符,不妨深入感受一番!至此,我们已成功实施了基于Mycat的数据库分割任务,并提供了几种常见的分割方法以供参考。
全局序列
在采用分库分表的架构中,数据库中自增主键的独立性无法得到保障,因此Mycat引入了全局序列机制。这一机制支持本地配置与数据库配置的多样化实现途径。
本地文件
此方法将Mycat的配置信息写入文件,一旦调用该配置,Mycat便会自动更新相应的值。
数据库方式(推荐使用)
采用数据库的某张表执行累计操作时,并非每次生成序列都要对数据库进行读写,这样做效率较低。Mycat会提前将一部分数据加载到其内存中,使得大多数读写操作能在内存内部完成。一旦内存中的序列段用尽,Mycat便会再次从数据库中获取数据。
在dn1上创建序列表
CREATE TABLE MYCAT_SEQUENCE (
name VARCHAR(50) NOT NULL,
current_value INT NOT NULL,
将整数值INT设置为必填项,其默认值为100。
PRIMARY KEY(name)
)ENGINE=InnoDB;创建函数获取当前的值
DELIMITER $
构建一个名为“mycat_seq_currval”的函数,该函数接受一个类型为VARCHAR(50)的参数“seq_name”,并返回一个类型为VARCHAR(64)的字符串值,同时使用utf8字符集。
DETERMINISTIC
BEGIN
DECLARE retval VARCHAR(64);
SET retval="-999999999,null";
执行查询,将当前值转换为字符类型,并与增量值以逗号分隔后,将结果存入变量retval,同时从名为MYCAT_SEQUENCE的序列表中选取对应seq_name的记录。
RETURN retval;
END $
DELIMITER ;创建函数设置的值
DELIMITER $
定义一个名为“mycat_seq_setval”的函数,该函数接受两个参数:第一个参数为字符串类型,长度不超过50个字符,用于指定序列名称;第二个参数为整型,用于设定序列的值。函数执行后返回一个字符串,长度为64个字符,字符集为UTF-8。
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = value
WHERE name = seq_name;
返回当前序列值,该值对应于名为`seq_name`的序列。
END $
DELIMITER ;创建函数获取下一个的值
DELIMITER $
定义一个名为mycat_seq_nextval的函数,该函数接受一个类型为VARCHAR(50)的参数seq_name,返回一个类型为VARCHAR(64)的字符串,并使用utf8字符集。
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
将当前值增加增量,条件是名称等于序列名称,并更新current_value。
RETURN mycat_seq_currval(seq_name);
END $
DELIMITER ;初始化序列表
新增一条记录,指定名称为ORDERS,初始设定为400000,采用increment100规则,即Mycat系统重启后该值将自动增加100,具体数值需根据业务需求自行调整。
向MYCAT_SEQUENCE表中插入数据,指定名称为'ORDERS',当前值为400000,增量设置为100。修改.xml文件
修改Mycat的.文件
序列名称对应于特定节点,例如在dn1上建立的序列,若序列是在dn2上创建的,相应地应将节点名称更改为dn2。
#sequence stored in datanode
GLOBAL=dn1
COMPANY=dn1
CUSTOMER=dn1
ORDERS=dn1修改.xml文件
在配置使用序列时,Mycat支持三种不同的方法,分别是:0号选项采用本地文件配置,1号选项则通过数据库进行配置,而2号选项则是基于时间戳的配置方式。
添加数据
语法操作涉及将ID的数值调整为“咱们这里序列名称”所对应的下一个值。
向订单表插入数据,其中订单编号为MYCATSEQ_ORDERS序列的下一个值,订单类型为101,客户编号为102,订单金额为1000元。查询数据
SELECT * FROM orders;
时间戳方式
全局序列ID由64位二进制数构成,其中包含42位表示毫秒、5位表示机器ID、5位表示业务编码以及12位用于重复累加。将此二进制数转换为十进制后,得到的long类型序列ID为18位,且每毫秒能够支持12位的二进制数进行并发累加。
自主生成
在项目实施过程中,您可以选择自行编写生成序列的代码,亦或是采用redis的incr命令来生成序列,尽管后者也是一种可行的方法,但需要您在程序中添加相应的编码实现。尽管如此,我们仍建议您优先考虑使用Mycat自带的全球序列生成功能,即第二种方案。
总结
觉得内容精彩,不妨动手关注并收藏,若在阅读过程中遇到难以理解或存在错误之处,欢迎在评论区留言指正!
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 