
经过研究,我们发现每页的链接标识符“page”的数值每次增加30,这代表着下一页的链接地址。
【分析每一条投诉信息】
在列表里点某条投诉信息,进入到某条投诉详情页。
投诉信息的编号、标题、内容如下:
查看这些字段在页面里的位置。
通过对页面的分析,得出需要保存的数据字段在页面上的位置。
#标题
获取标题时,使用.title定位到对应元素,然后通过.xpath方法筛选出class属性为空或未指定的div标签,接着提取该标签下的所有文本内容,最后选取这些文本中的第一个作为标题。
# 编号是标题里的一部分,通过字符串切片,得到编号的内容。
该id值等于将title字符串通过空格分割后,取最后一个元素,再通过冒号分割,取最后一个部分的结果。
# 内容
选取位于具有“c1”类名的div标签内的文本内容,并获取该文本序列中的第一个元素。
#链接就是请求返回的URL
url=.url
在第三阶段,创建名为 items.py 的文件,并在此文件中配置好所需保存的各项数据字段。
class (.Item):
在此处输入您商品的详细信息,例如:
# 标题
title = .Field()
# 编号
id = .Field()
# 内容
= .Field()
# 链接
url = .Field()
第四步:创建爬虫。
在 dos下切换到目录
D:\\\\
用命令 -t crawl sun " " 创建爬虫。

第五步:编写爬虫文件。
,sys,os
# 导入类和Rule
from . , Rule
# 导入链接规则匹配类,用来提取符合规则的连接
from .
sys.path.(path)
from .items
class ():
name = 'sun'
= ['']
= ['']
#多条 Rule
rules = (
规则限制为:允许类型为4的请求,且分页参数以数字表示。
设定规则,允许访问模式为“/html/”,后跟两位数字,再接“/”,接着是两位数字,最后以“.shtml”结尾,且不进行任何替换,同时该规则生效。
def (self, ):
item = ()
#标题
item['title'] 被赋值为通过.xpath方法选取的特定元素,该元素位于class属性为"p3"的div标签内,并且提取出的文本内容是第一个匹配的。
# 编号
item['id'] 被赋值为 item['title'] 字符串通过空格分割后最后一个元素,再通过冒号分割后得到的最后一个元素。
# 内容
该条目赋值操作为:通过.xpath方法选取指定路径下的第一个文本内容,并将其存储在相应的位置。
# 链接
item['url'] = .url
yield item
第六步:编写管道文件:。
json
class ():
# 方法是可选的,做为类的初始化方法
def (self):
# 创建了一个 sun.json 文件,用来保存数据
self. = 打开文件名为"sun.json",以二进制写入模式进行操作
# 方法是必须写的,用来处理item数据
def (self, item, ):
将字典项转换为JSON字符串,不进行美化格式化,之后添加逗号和换行符。
将收集到的信息录入至名为“sun.json”的文档,并确保文件以UTF-8编码格式保存。
self..write(text.("utf-8"))
item
# 方法是可选的,结束时调用这个方法
def (self, ):
self..close()
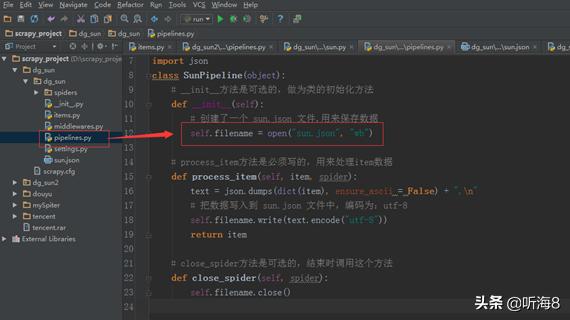
第七步:修改 文件。
在.py文件配置里指定刚才编写的管道文件名:。
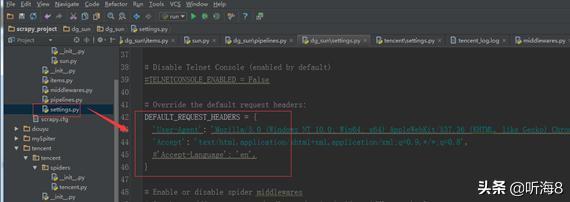
设置爬虫请求的默认头信息。
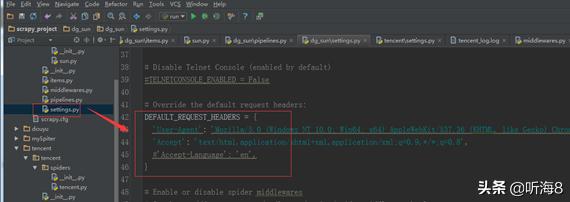
第八步:运行爬虫。
在 dos下切换到目录
D:\\\ 下
通过命令运行爬虫 : crawl sun
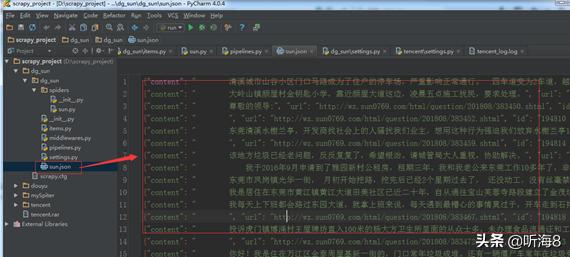
第九步:查看爬取的结果。
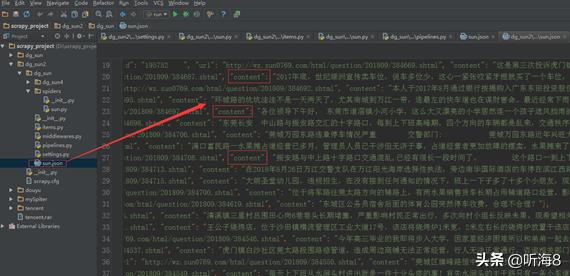
查看新建的sun.json 数据文件。
1.2 爬虫进阶案例二
爬虫案例二:完善东莞阳光热线问政平台案例。
在先前的讨论中,我们以东莞阳光热线问政平台为例,探讨了爬虫的应用。通过观察爬取得到的数据,我们识别出了三个主要问题。
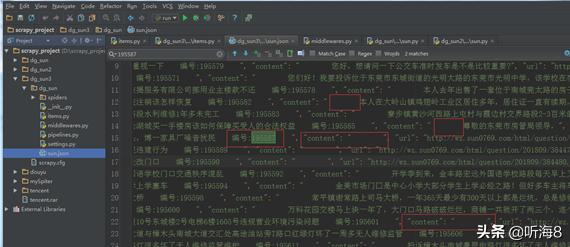
(问题一)提取的投诉内容前面有空格。
某些投诉帖子的内容摘要并不完整,比如在某个帖子中,尽管包含了两段文字,但仅对第一段进行了摘录。
开学季来临,金丰路上的宏远外国语学校附近路段每日清晨再次出现交通拥堵现象。该路段不仅设有宏远外国语学校和阳光第二小学,而且每日早晨接送学生的车辆众多,周边小区居民在上班高峰期也加入交通流,极易导致交通堵塞。更严重的是,宏外路口摆摊卖花和水果的三轮车随意停放在路口,而宏外的学生家长在路边随意停车,未能做到即停即走。实际上,家长只需将孩子交给学校的义工或保安,便可驾车离开。然而,许多家长却选择停车后送孩子进校,然后再驾车离开,导致后方车辆排队越来越长。更有一些司机不顾交通规则,强行加塞抢道,进一步加剧了道路的拥堵。", "url": "
"},
分析页面的结构:
1、内容如果有几段话,每一段话有个
2、每段话前有一串字符: (文本里的空字符);
通过 XPath 去定位内容,查看结果是 OK 的。
在代码执行过程中,我们通过item[''] = .xpath('//div[@class="c1 "]/text()')这一操作获取到了文本列表,而当我们需要具体内容时,通过()[0]的方式获取,因此我们所获得的是列表中的第一条文本,即第一段话的内容。
修改爬虫文件代码,只取 内容,看爬取得到的结果是什么。
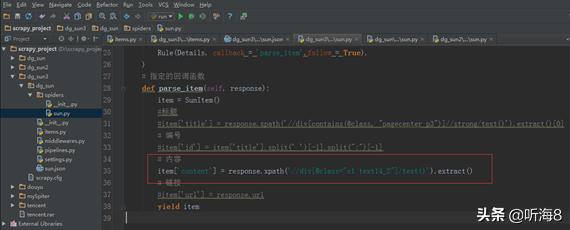
运行的结果:
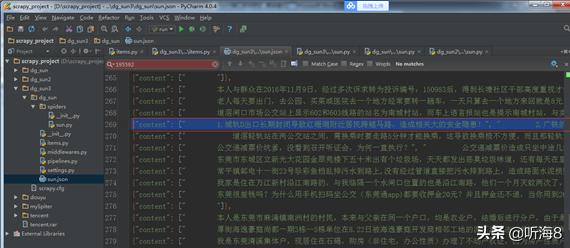
该数据指出:一、城轨D出口的长期封闭使得红珊瑚周边居民不得不穿越马路,此行为带来了极大的安全隐患;二、广铁工作人员表示,领导层明确表示不允许开放,原因是成本过高。然而,考虑到附近众多居民横穿马路,一旦发生人员伤亡事故,责任应由广铁公司或松山湖管委会的相关负责人承担吗?若您觉得费用过高,可以选择让乘客步行上下楼梯,然而,在接到众多投诉之后,管委会,难道这就是我们所说的服务于人民的政府吗?今天下班时分,我看到一大群人横穿马路,若发生意外,我想要问问管委会,他们又是如何向人民作出解释的!
问题一和问题二处理的方案:
#获取每个投诉的 内容列表
使用xpath定位到具有class属性值为"c1"的div标签,提取其内部的文本内容,并执行相应的操作。
#把列表转化成字符串,并去掉前面的空格
item[''] = "".join().strip()
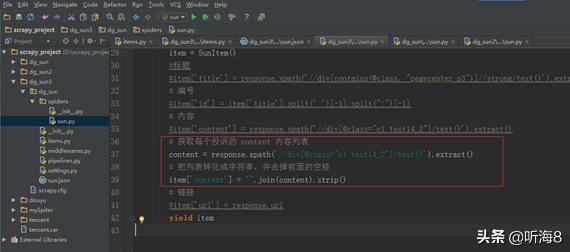
重新运行看结果:
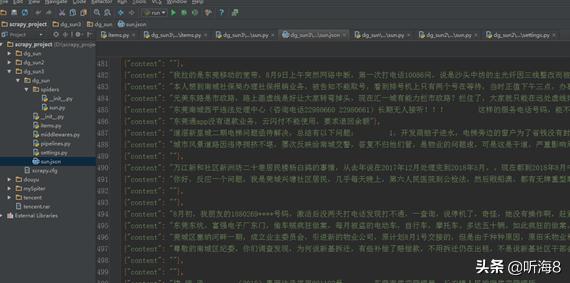
(问题三)很多投诉内容为空。
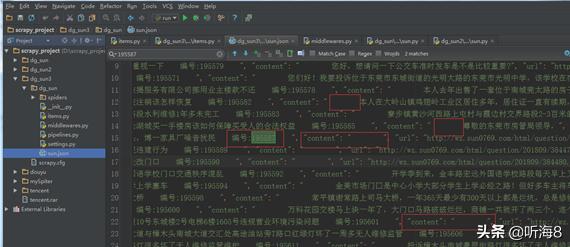
经过分析页面,发现个别投诉信息上传了图片。
页面元素分析:
如果投诉有图片,内容的路径是如下:
使用xpath定位选择器,选取具有特定类名的div元素,提取其中的文本内容,并执行相应的操作。
问题三的处理方案:修改爬虫代码
在处理内容时,首先遵循图片存在时的匹配准则,一旦存在相关内容,即返回包含所有相关内容的列表集合。
= .xpath('//div[@class=""]/text()').()
若内容为空,则应返回一个空列表,并按照无图片时的匹配规则进行处理。
if len() == 0:
= .xpath('//div[@class="c1 "]/text()').()
item[''] = "".join().strip()
else:
item[''] = "".join().strip()
分析完问题,有了处理方案之后,重新完整的实现爬虫案例。
案例步骤:
第一步:创建项目。
在 dos下切换到目录
D:\
新建一个新的爬虫项目:
在第二步中,我们需要确定具体要抓取的数据字段,并对网站的结构进行深入分析,包括其URL的构成以及所需抓取字段的具体布局。
【分析分页URL地址】
从图片中看到投诉信息列表有3192页。
第一页的链接地址:
第二页的链接地址:
最后一页的链接地址:
通过分析我们得知,每一页的的链接地址page的值递增30,就是下一页的地址。
【分析每一条投诉信息】
在列表里点某条投诉信息,进入到某条投诉详情页。
投诉信息的编号、标题、内容如下:
查看这些字段在页面里的位置。
通过对页面的分析,得出需要保存的数据字段在页面上的位置。
#标题
title=.xpath('//div[(@class, "")]///text()').()[0]
# 编号是标题里的一部分,通过字符串切片,得到编号的内容。
id =title.split(' ')[-1].split(":")[-1]
# 内容,先使用有图片情况下的匹配规则,如果有内容,返回所有内容的列表集合
= .xpath('//div[@class=""]/text()').()
# 如果没有内容,则返回空列表,则使用无图片情况下的匹配规则
if len() == 0:
= .xpath('//div[@class="c1 "]/text()').()
item[''] = "".join().strip()
else:
item[''] = "".join().strip()
#链接就是请求返回的URL
url=.url
第三步:编写 items.py 文件,设置好需要保存的数据字段。
class (.Item):
# the for your item here like:
# 标题
title = .Field()
# 编号
id = .Field()
# 内容
= .Field()
# 链接
url = .Field()
第四步:创建爬虫。
在 dos下切换到目录
D:\\\\
用命令 -t crawl sun " " 创建爬虫。
第五步:编写爬虫文件。
,sys,os
# 导入类和Rule
from . , Rule
# 导入链接规则匹配类,用来提取符合规则的连接
from .
path = os.path.(os.path.(os.path.(os.path.())))
sys.path.(path)
from .items
class ():
name = 'sun'
= ['']
= ['']
针对投诉分页的链接提取规则进行探讨,并生成一个包含所有符合该规则的链接匹配对象的列表(具体提取的是分页链接)。
= (allow=r'type=4&page=\d+')
关于投诉详情页中内容链接的提取方法,系统将提供一组符合既定匹配标准的链接,并将这些匹配到的链接对象以列表形式返回。
禁止对特定页面进行修改,规则为允许访问路径格式为/html/数字/数字.shtml。
# 多条 Rule
rules = (
提取对应信息,并对相关链接进行追踪调查(若未标注“没有”,则视为默认有效)。
Rule(),
Rule(, ='', =True),
# 指定的回调函数
def (self, ):
item = ()
# 标题
item['title'] = .xpath('//div[(@class, " p3")]///text()').()[0]
# 编号
item['id'] = item['title'].split(' ')[-1].split(":")[-1]
# 内容,先使用有图片情况下的匹配规则,如果有内容,返回所有内容的列表集合
= .xpath('//div[@class=""]/text()').()
# 如果没有内容,则返回空列表,则使用无图片情况下的匹配规则
if len() == 0:
= .xpath('//div[@class="c1 "]/text()').()
item[''] = "".join().strip()
else:
item[''] = "".join().strip()
# 链接
item['url'] = .url
yield item
第六步:编写管道文件:。
json
class ():
# 方法是可选的,做为类的初始化方法
def (self):
# 创建了一个 sun.json 文件,用来保存数据
self. = open("sun.json", "wb")
# 方法是必须写的,用来处理item数据
def (self, item, ):
text = json.dumps(dict(item), = False) + ",\n"
# 把数据写入到sun.json 文件中,编码为:utf-8
self..write(text.("utf-8"))
item
# 方法是可选的,结束时调用这个方法
def (self, ):
self..close()
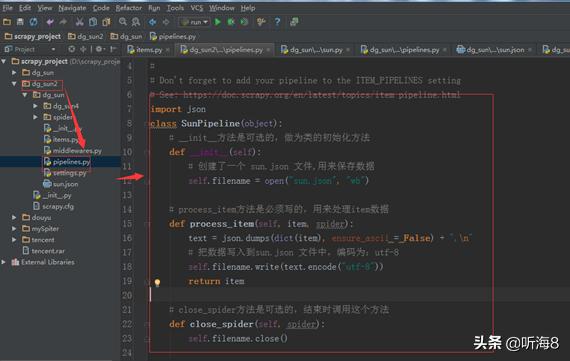
第七步:修改 文件。
在.py文件配置里指定刚才编写的管道文件名:。
设置爬虫请求的默认头信息。
第八步:运行爬虫。
在 dos下切换到目录
D:\\\ 下
通过命令运行爬虫 : crawl sun
第九步:查看爬取的结果。
查看新建的sun.json 数据文件。
1.3 爬虫进阶案例三
爬虫案例三:用 类改写“东莞阳光热线问政平台”案例。
案例步骤:
第一步:创建项目。
在 dos下切换到目录
D:\
新建一个新的爬虫项目:
第二步:明确需要爬取的内容字段,分析网站的结构( URL、需要爬取的字段的结构)。
【分析分页URL地址】
从图片中看到投诉信息列表有3192页。
扫一扫在手机端查看
- 上一篇:php extract($_get); SQL注入原理与分类_科普基础 | 最全的SQL注入总结
- 下一篇:phpmyadmin php7 nginx Linux CentOS7 phpMyAdmin安装教程_Linuxcentos7下安装phpMyAdmin的教程
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 