

0x01
恶意软件通常使用域生成算法 (DGA) 作为联系其 C&C 服务器的机制。近年来,已经提出了基于机器学习的不同方法来自动检测生成的域名。但也存在一些问题。第一个问题是,由于缺乏独立的标准,很难系统地比较这些 DGA 检测算法。第二个问题是,当攻击者的机器学习模型已知时,他们绕过这些分类器的难度有多大。
本文在同一个DGA集上比较了两种不同的检测方法:使用人工特征工程的经典随机森林和深度学习循环神经网络。独立进行标准测试,并比较两种最新的DGA检测方法:
(a)FANCI 是最近使用人工特征工程进行随机森林分类的
(b)LSTM,一种基于深度循环神经网络的分类器
0x02 DGA
在不知情的情况下安装在计算机上的恶意软件可用于攻击其他计算机、发送未经请求或网络钓鱼的电子邮件、窃听通信、窃取电子邮件地址、加密计算机内容并要求用户支付赎金。解密功能以及更恶意的情况。大量受感染的机器被称为僵尸网络,它们由命令和控制 (C&C) 服务器控制。
为了防止这些 C&C 服务器被关闭或无法访问,恶意软件通常会使用域生成算法 (DGA) 来定期创建一组新的伪随机域名。上图显示了使用 DGA 连接 C&C 服务器的过程。恶意软件会生成一些随机域名,然后恶意软件会尝试这些域名,只有僵尸网络所有者必须注册其中一个,僵尸网络才能成功重新连接到其 C&C 服务器。这使得清除僵尸网络成为一项艰巨的任务。
相反,识别算法生成的域名可以帮助检测受感染的主机并标记旨在控制僵尸网络的域名注册。能够成功区分算法生成的域名和人工创建的域名的分类器对安全研究人员、执法人员和网络运营人员非常有用。
在安全和隐私领域,深度神经网络已经展示了其自主查找和提取相关特征的能力,并且与传统机器学习方法相比,其分类准确率更高。同样对于DGA检测,最近的相关工作提出了基于深度学习方法的解决方案。然而,恶意攻击者也可以利用这些AI分类方法来逃避对其恶意软件的检测。这些观察反映了对抗的升级。一是涉及进一步改进先进的深度学习方法,以提取更好的特征用于进攻或防御目的。二是无论使用哪种机器学习方法,对手都会试图绕过安全专家开发的新防御措施。
0x03 真相
恶意(DGA)和正常(非DGA)域名的数据来自不同的来源:
恶意数据集来自 FKIE 提供和维护的服务。由于可用的顶级域名 (TLD) 数量有限,并且域名生成算法使用的特定 TLD 对分类准确性没有影响,因此从 DGA 域名中删除了 TLD。从域名中省略 TLD 时,将选择所有具有 100,000 个或更多可用唯一记录的域名的 DGA。这将生成下表中显示的 26 个 DGA 列表。

对于常见的数据集,许多人选择 Alexa 访问量最大的网站前 n 个列表。然而,事实证明 Alexa 列表已经包含由 DGA 生成的域名。此外,最受欢迎域名的列表可能偏向于比平均注册域名数量更短、更容易发音和更容易记住的域名。因此,我们选择使用 2016 年来自知名 TLD 的前 100,000 个注册域名列表,这些域名的筛选依据如下:
•域名未出现在下列任何黑名单中:
安全浏览列表,
DBL 黑名单,
SURBL 黑名单。
• 没有使用国际化域名(截至撰写本文时,没有任何 DGA 使用国际化 (IDN) 域名 - 这使得 IDN 对于分类而言并不重要)
•未知的域名。
对于每个 DGA,我们构建了一个由 100,000 个常见域名和 100,000 个恶意域名混合而成的数据集,并使用相同的常见域名数据对每个 DGA 进行评估。
0x04 DGA
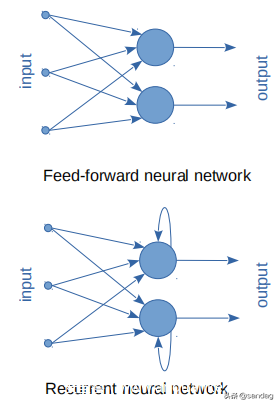
LSTM: 等人提出的长短期记忆 (LSTM) 神经网络。STM 是一种特定类型的循环神经网络 (RNN)。RNN 通常用于识别或预测顺序数据中的模式。与前馈神经网络相比,RNN 具有内部短期记忆,可保留有关其接收的输入的重要信息。它们通过复制输出并将其循环回网络来实现这一点,如上图所示。此功能使 RNN 能够更深入地了解序列及其上下文,并预测接下来会发生什么。LSTM 通过使此类网络能够在更长的时间内记住其输入来扩展 RNN,从而将其存储容量扩展到两个时间步之外。LSTM 中的单元具有可以通过一组可编程门读取、写入或重置的状态。这些门将输入连接和循环连接都调制为 0 到 1 之间的值,从而使当前状态在时间步之间保持不变。
LSTM 非常适合用来识别 DGA,因为 LSTM 可以在不需要人工根据原始输入进行特征工程的情况下,学习和泛化众多 DGA 的生成过程。LSTM 是一个黑盒子,如果没有相同的训练集,攻击者很难绕过分类器。
LSTM 由以下连续层组成:
• 嵌入层,将可变长度的域名字符序列转换为固定长度、零填充的特征数组。
• LSTM 层,从嵌入层接收大小为 38 的输入(编码 26 个字符、10 个数字、破折号和结束符号),并生成大小为 128 的输出
•0.5 层防止过度拟合
•具有输出维度的密集输出层,后跟激活函数
使用 5 倍交叉验证分别评估每个 DGA 分类器的性能:使用 4/5 的数据在 10 个 epoch 中训练网络,批大小为 128;训练后剩余的 1/5 数据随后用于测试网络。使用不同数量的数据折叠重复 4 次,丢弃先前训练过的网络,从而确保测试数据永远不会用于训练。
0x05 范西
根据 FANCI 对域名进行特征工程,将提取的 41 个特征输入到 100 棵树的随机森林中,每棵树考虑 6 个随机特征,然后使用 5 倍交叉验证来评估其性能。FANCI 系统不仅通过检查域名字符序列来检测 DGA 生成的域名,还可以查看从 DNS 查询中得出的其他特征。

FANCI 系统使用的许多特征实际上不会在比较测试中使用。这些特征如上所列。例如,FANCI 的特征 5,“具有有效的 TLD”是一个二分类特征,表示域名具有有效的顶级域。显然,没有 DGA 会输出具有无效 TLD 的域名,因为这些域名永远不会被解析,因此毫无用处。但这个特征在 FANCI 系统中非常有用,因为它可以很容易地检测到域名 TLD 部分的人为输入错误,因此这些错误显然不是 DGA 生成的域名。
0x06 DGA
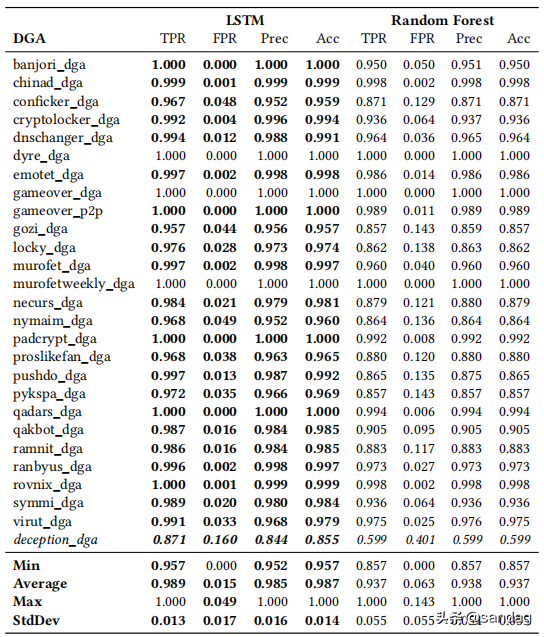
下表列出了两种分类器测试的 DGA 分类结果。对于所有测试的 DGA,LSTM 分类器得出了检测率 (TPR)、假阳性率 (FPR)、精度和准确率。平均而言,随机森林分类器的 FPR 是 LSTM 的 4 倍以上。LSTM 分类器的平均准确率为 98.7%,而随机森林分类器的平均准确率为 93.7%。
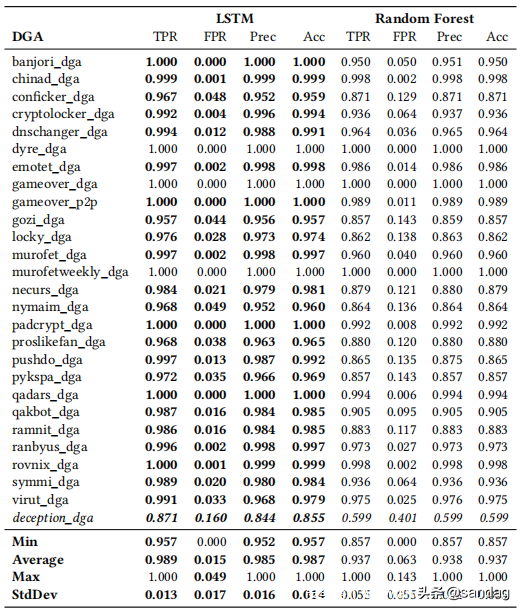
随机森林分类器的FPR标准差为3倍,随机森林分类器的准确率标准差为4倍,说明LSTM不仅能得到更优的分类结果,而且不同DGA的分类结果一致性更高。值得注意的是,加入FANCI特征的随机森林在、、、和DGA上的表现要差很多。
LSTM 分类器一致性更好的一个可能解释是,LSTM 网络在训练期间自动学习其使用的分类特征,而随机森林需要手动特征工程,这可能更适合或更不适合不同的 DGA。然而,使用人工特征工程还有另一个危险:DGA 开发人员可以了解所使用的特征并修改域生成算法,使其更难被发现。
0x07 新的 DGA

接下来,FANCI 分类结果用于创建一个名为 的新 DGA,该 DGA 考虑到分类器的特性以避免检测。攻击者迭代改进其 DGA(如上图所示),直到达到所需的次优分类结果,从而有效绕过 DGA 检测分类器。创建 DGA 时仅使用来自 Alexa 列表的数据,模仿 DGA 作者可用的信息。
下图显示了 DGA “模拟”不同特征时对分类准确率的影响。通常,随着 DGA 模拟更多特征,随机森林分类器的准确率开始下降。新的 DGA 也给 LSTM 带来了困难,将其准确率降低到 0.855,这是迄今为止 LSTM 的最低记录,与 、 、 和 DGA 的随机森林准确率相当。将 LSTM 上的轮数从 10 增加到 15 会略微提高准确率到 0.860。将 LSTM 输出空间维度从 128 更改为 256 可使分类准确率达到 0.865。同时应用更大的输出空间维度并将训练周期数增加到 15 个组合仍可获得 0.864 的分类准确率。
0x08
本文在有足够多DGA生成的域名的情况下,对两种检测域名生成算法的机器学习方法进行了比较,结论表明深度学习方法始终优于采用人工特征工程的随机森林,其中循环神经网络的平均分类准确率为98.7%,随机森林的分类准确率为93.8%。
结果还表明,手动特征工程的缺点之一是 DGA 可以根据用于检测的特征知识调整其策略。为了证明这一点,使用所用特征集的知识设计了一种新的 DGA,这将随机森林分类器的分类准确率降低到 59.9%。深度学习分类器也受到了影响(尽管影响较小),其准确率降低到 85.5%。
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 