
爬虫是入门最好的方式之一,掌握了爬虫之后再去学习其他知识点就会更加得心应手,当然对于零基础的朋友来说,使用爬虫还是比较困难的,所以小伙伴们,你们真的了解爬虫吗?
下面我就简单给大家讲解一下爬虫的相关内容,对于想提升实践能力的小伙伴我们还准备了一篇《编写网络爬虫》的教程,一共212页,内容详实,代码清晰,非常适合初学者。
【文末有获取方法!!】
爬虫基本架构
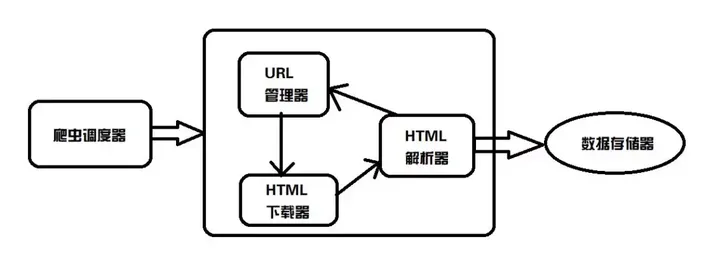
从上图可以看出,基本的爬虫架构大致分为五类:爬虫调度器、URL管理器、HTML下载器、HTML解析器、数据存储设备。
下面对这五个功能做一下简单解释:
抓取数据是否违法?
对于是否违法,众说纷纭,但目前为止,网络爬虫还是在法律允许的范围内。当然,如果抓取的数据用于个人或者商业用途,造成一定的负面影响,是会受到谴责的。所以请合理使用爬虫。
为什么选择爬行?
1. 与其他静态编程语言相比,抓取网页的接口更简单。另外,抓取网页有时需要模拟浏览器的行为,而很多网站会屏蔽刚性抓取。这时候我们就需要模拟用户代理的行为,构造合适的请求。有优秀的第三方包可以帮助你做到这一点。
2、网页爬取后的处理 爬取到的网页通常需要进行一些处理,比如过滤HTML标签,提取文本等。它提供了简洁的文档处理函数,可以用很短的代码完成大部分的文档处理。
其实很多语言和工具都可以做到上述的功能,但是使用.
NO.1 开发速度快,语言简洁,没有太多技巧,所以很清晰,易读。
NO.2 跨平台(由于开源,比Java更能体现“一次编写,随处运行”的理念)
NO.3 解释(无需编译,只需运行/调试代码)
NO.4 架构选择太多(主要的GUI架构有PyGtk,PyQt)。
如何使用网络爬虫?
《编写网络爬虫》共计212页9章,内容涵盖了从基础到实际应用的方方面面,内容详实简洁,代码清晰可复现,非常适合有一定编程经验,又对爬虫感兴趣的朋友阅读。
九章分别阐述了以下内容:
第1章:网络爬虫简介,介绍什么是网络爬虫以及如何爬取网站。
第 2 章:数据抓取,展示如何使用多个库从网页中提取数据。
第 3 章:下载缓存,介绍如何通过缓存结果避免重复下载。
第 4 章:并发下载教您如何通过并行下载网站来加快数据抓取速度。
第 5 章:动态内容,介绍如何通过多种方式从动态网站中提取数据。
第 6 章:表单交互展示如何使用输入和导航表单进行搜索和登录。
第 7 章: 处理,解释如何访问受 图像保护的数据。
第8章:介绍如何使用执行快速并行爬取,以及如何使用Web界面构建网络爬虫。
第 9 章:综合应用总结了本书所学到的网络爬虫技术。
部分内容展示:



包含:激活码+安装包、网页开发、爬虫、数据分析、人工智能、机器学习等教程。带你从零开始系统学习!
以上全套学习资料已上传至CSDN官方,如有需要可以微信扫描下方CSDN官方认证二维码获取。
[[CSDN大礼包:《兼职资源&全套学习资料》免费分享]](安全链接,放心点击)
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 