
这里有8个现成的自动化脚本可供直接使用,今天我要向大家介绍8个极具实用价值的自动化脚本。

1、自动化阅读网页新闻
此脚本具备从网页提取文字内容的功能,并能实现语音自动朗读,若您需要听新闻,它无疑是一个不错的选择。
该代码主要分为两个主要部分,首先是通过爬虫技术来搜集网页上的文本内容,其次则是利用阅读软件对所获取的文本进行朗读。
需要的第三方库:
Soup是一款备受推崇的HTML/XML文档解析工具,主要用于从所抓取的网页中提取所需的信息。
- 好用到逆天的HTTP工具,用来向网页发送请求获取数据
- 将文本转换为语音,并控制速率、频率和语音
import pyttsx3
import requests
from bs4 import BeautifulSoup
初始化语音合成器,采用sapi5引擎,并赋值给变量engine。
获取引擎属性中的“voices”值,并存储到变量“voices”中。
设置新的语音速率值为130,以降低说话速度。
设置属性时,将“voice”指定为“voices”数组中第二个元素的ID。
def speak(audio):
engine.say(audio)
engine.runAndWait()
请输入文章内容,将其粘贴后,系统将转换为字符串类型。
res = requests.get(text)
通过使用`html.parser`解析器,将`res.text`内容转换成`soup`对象。
articles = []
在遍历过程中,通过使用range函数,我们针对soup对象中select方法筛选出的所有类名为".p"的元素数量进行循环,实现从0到该数量的迭代。
文章内容等于从soup中选取带有类名“p”的元素,在索引为i的位置上,获取其文本内容,然后去除首尾空格。
articles.append(article)
text = " ".join(articles)
speak(text)
将语音内容保存为音频文件,请执行以下操作:engine.save_to_file函数,传入text参数和文件名'测试.mp3'。
engine.runAndWait()
2、自动化数据探索
数据科学项目的开展,首先需要进行数据探索;这一步骤至关重要,因为它要求你掌握数据的基本情况;只有在此基础上,你才能深入挖掘数据中更深层次的价值。
通常我们借助诸如等工具来挖掘数据,然而这往往要求我们编写大量的程序代码。若想提升工作效率,Dtale则成为了一个非常合适的选择。
Dtale的功能在于仅需一行代码即可生成自动化分析报告,该工具巧妙地融合了Flask的后端技术与React的前端技术,从而为我们提供了一种直观便捷的方式来查看与解析数据结构。
我们可以在上实用Dtale。
需要的第三方库:
Dtale - 自动生成分析报告
导入Seaborn库以处理某些数据集
import seaborn as sns
Seaborn库内置数据集的打印
输出sns获取的数据集名称列表。
### Loading Titanic Dataset
### Importing The Library
import dtale
#### Generating Quick Summary
dtale.show(df)
3、自动发送多封邮件
该脚本能够实现邮件的批量定时发送功能,同时支持对邮件内容和附件进行个性化设置,实用性极高。
相较于邮件客户端,脚本在部署邮件服务方面展现出智能、批量操作以及高度定制化的优势。
需要的第三方库:
Email - 用于管理电子邮件消息
向SMTP服务器投递邮件时,会创建一个SMTP客户端会话,这个会话能够将邮件传递至全球任何一台安装有SMTP或ESMTP监听程序的电脑。
- 用于数据分析清洗的工具
import smtplib
引用电子邮件消息模块,使用EmailMessage类
import pandas as pd
定义一个发送电子邮件的函数,该函数接受收件人邮箱地址、邮件主题和邮件内容作为参数。
创建了一个EmailMessage类的实例,用于处理电子邮件消息。
邮件的发送者信息设置为“Pythoneer在此”,即指代那位正在发送邮件的人。
邮件的接收者地址设置为接收者的电子邮箱地址,即:email['to'] = remail,这代表了我们即将向其发送邮件的对象。
邮件的主题被设置为rsubject,即邮件的主题内容。
将邮件内容设置为rcontent,即设定了邮件的具体信息。
使用smtplib库中的SMTP函数,以smtp.gmail.com为主机,587为端口,创建一个SMTP连接,并将其作为smtp对象进行操作。
调用smtp.ehlo()函数,以获取服务器对象。
启动SMTP的TLS功能,此操作旨在在服务器与客户端之间传输数据。
执行登录操作,账户邮箱为“deltadelta371@gmail.com”,密码为“delta@371”。
smtp执行发送邮件操作,email信息被传递。
输出信息显示:“邮件已成功发送至”,remail地址。
若当前模块作为主程序运行:
数据框架df通过读取名为“list.xlsx”的Excel文件而创建。
length = len(df)+1
在遍历数据框df的每一行时,使用index和item变量分别代表行索引和行数据。
email = item[0]
subject = item[1]
content = item[2]
执行发送电子邮件操作,指定邮件地址为email,邮件主题为subject,邮件内容为content。
4、将 PDF 转换为音频文件
脚本具备将PDF文档转换成音频格式的功能,其工作原理相对直观:它首先利用PyPDF工具从PDF文件中提取文字内容,接着再将这些文字内容转换成语音输出。
import pyttsx3,PyPDF2
使用PyPDF2库,我们首先创建了PdfFileReader对象,接着通过以二进制读取模式打开文件“story.pdf”,从而成功初始化了该对象。
speaker = pyttsx3.init()
在遍历PDF阅读器的页数时,以page_num为变量,从0开始,逐页增加,直至达到pdfreader.numPages所指示的总页数。
获取指定页码的PDF内容,通过pdfreader对象调用getPage方法,传入页码参数,再调用extractText方法,从而提取文本信息。
cleaned_text = text经过去除首尾空格和替换换行符为空格的处理,去除了多余的空格和换行符。
输出经过清理的文本内容,展示PDF中的信息。
发言人应朗读经过清理的文本内容,使其能够流畅地传达信息。
演讲者将清理后的文本保存至音频文件,命名为“story.mp3”。
speaker.runAndWait()
speaker.stop()
5、从列表中播放随机音乐
该脚本具备从歌曲存储目录中随机挑选一首歌曲进行播放的功能,但需特别留意,os模块仅能在操作系统为系统的情况下正常运行。
import random, os
音乐文件存放路径设定为G盘下的“new english songs”文件夹。
songs = os.listdir(music_dir)
song等于从0到songs长度范围内随机生成的整数。
输出歌曲名称,即显示songs列表中对应song索引的曲目。
启动文件,通过拼接音乐目录与列表中的第一首歌曲路径,执行os.startfile操作。
6、智能天气信息
国家气象局的官方网站上设有获取天气预报的接口,该接口能够直接输出以 json 格式组织的天气信息。因此,我们只需从这些 json 数据中提取所需的具体信息即可。
请访问所指定城市(县、区)的天气预报网页,点击链接后,即可获取该地的气象信息。例如:
上海徐汇区对应的天气网址。
具体代码如下:
mport requests
import json
import logging as log
def get_weather_wind(url):
r = requests.get(url)
if r.status_code != 200:
日志记录错误:“无法获取天气信息!”
信息内容经过解码处理,随后被转换成了JSON格式。
# get wind data
data是从info字典中提取的,具体为键名为'weatherinfo'的部分。
WD = data['WD']
WS = data['WS']
执行返回操作,格式化输出字符串“{}”,括号内包含参数WD和WS。
def get_weather_city(url):
打开网页链接,获取响应后的数据。
r = requests.get(url)
if r.status_code != 200:
log.error("Can't get weather data!")
# convert string to json
info = json.loads(r.content.decode())
# get useful data
data = info['weatherinfo']
city = data['city']
temp1 = data['temp1']
temp2 = data['temp2']
数据中的天气信息对应于weather键值。
返回数据格式为:城市名称,天气状况,温度范围从temp1至temp2。
若当前模块作为主程序运行:
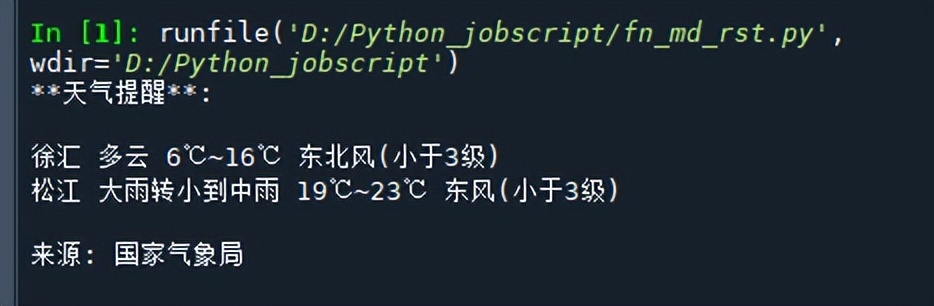
msg = """**天气提醒**:
{} {}
{} {}
来源: 国家气象局
""".format(
获取城市天气信息,访问链接为'http://www.weather.com.cn/data/cityinfo/101021200.html'。
获取天气风力信息,通过访问网址:http://www.weather.com.cn/data/sk/101021200.html。
获取城市天气信息,请访问网址:http://www.weather.com.cn/data/cityinfo/101020900.html。
获取天气风速信息,请访问网址:http://www.weather.com.cn/data/sk/101020900.html。
)
print(msg)
运行结果如下所示:
7、长网址变短网址
那些较长的网址有时会让人感到非常烦躁,阅读和分享起来都十分不便,这款脚本能将它们转换成简洁的短网址。
import contextlib
引用 urllib.parse 模块中的 urlencode 函数。
导入urllib.request模块中的urlopen函数。
import sys
def make_tiny(url):
request_url 等于 'http://tinyurl.com/api-create.php?' 加上
对{'url':url})进行URL编码处理。
使用contextlib模块中的closing函数,对urlopen函数请求的request_url进行封装,确保在操作完成后能够自动关闭响应对象。
返回读取响应内容后,使用UTF-8编码进行解码的结果。
def main():
遍历sys.argv[1:]中的每个元素,使用make_tiny函数将其转换为短链接,并将结果存储在tinyurl变量中。
print(tinyurl)
if __name__ == '__main__':
main()
此脚本极具实用性,例如,若内容平台对公众号文章进行屏蔽,则可将文章链接转换成简短形式,进而嵌入其中,从而成功规避屏蔽机制。
8、清理下载文件夹
开发者的下载文件夹往往是混乱不堪,充斥着杂乱无章的文件。本脚本将依据文件大小设定进行整理,对下载文件夹进行有选择的清理,优先处理那些较为陈旧的文件。
import os
import threading
import time
def get_file_list(file_path):
#文件按最后修改时间排序
获取文件路径下的目录列表,并存储于变量dir_list中。
if not dir_list:
return
else:
dir_list = 对dir_list进行排序,排序依据是每个元素在指定路径下对应的文件最后修改时间,排序操作通过使用os.path.getmtime函数和os.path.join函数结合实现。
return dir_list
def get_size(file_path):
"""[summary]
Args:
file_path ([type]): [目录]
Returns:
[type]: 返回目录大小,MB
"""
totalsize=0
遍历文件路径下的目录列表,对每一个文件名进行操作:
总计大小更新为:总计大小加上文件路径与文件名结合后获取的文件大小。
输出总大小除以1024再除以1024的结果。
返回总大小除以1024再除以1024的结果
检测文件路径大小,同时设定最大尺寸限制为size_Max,删除尺寸超出size_Del的文件。
"""[summary]
Args:
file_path ([type]): [文件目录]
size_Max ([type]): [文件夹最大大小]
当[type]的尺寸超过[size_Max]时,应予以删除的尺寸大小为[size_Del]。
"""
print(get_size(file_path))
若文件路径所对应的文件大小超过了预设的最大值。
获取文件列表的操作通过调用get_file_list函数完成,该函数接收参数file_path,并将返回的文件列表赋值给变量fileList。
遍历文件列表的长度,对每一个索引值进行循环处理。
若获取文件路径的尺寸值超出最大尺寸与删除尺寸之差。
输出:“删除:编号%d,文件名:%s” ,其中%d代表文件列表中元素的索引加1,%s代表文件列表中对应的文件名。
执行删除操作,针对路径为file_path加上fileList中第i个元素的组合路径所指向的文件。
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 