
如果mysql批量更新一条一条的进行的话,效率是相当慢的。它循环一条一条地更新记录,一次更新一条记录。这样性能很差,很容易造成阻塞。
mysql批量更新有四种方法: 1.进入批量更新
replace into 表名l (id,字段1) values (1,'2'),(2,'3'),...(x,'y');
2.进入...关键批量更新
insert into 表名l (id,字段1) values (1,'2'),(2,'3'),...(x,'y') on duplicate key update 字段1=values(字段1);
3、创建临时表,先更新临时表,然后从临时表中删除临时表。
create temporary table tmp(id int(4) primary key,dr varchar(50)); insert into tmp values (0,'gone'), (1,'xx'),...(m,'yy'); update test_tbl, tmp set test_tbl.dr=tmp.dr where test_tbl.id=tmp.id;
注意:该方法需要用户有表权限。
4.使用mysql自带的语句构建批量更新
Mysql批量实现可以通过一些技巧来实现:
UPDATE yoiurtable SET dingdan = CASE id WHEN 1 THEN 3 WHEN 2 THEN 4 WHEN 3 THEN 5 END WHERE id IN (1,2,3)
这条sql的意思是更新字段。如果id=1,则值为3,如果id=2,则值为4...
where部分不会影响代码的执行,但会提高SQL执行的效率。确保sql语句只执行需要修改的行数。这里只更新3行数据,where子句保证只执行3行数据。
例子:UPDATE book
SET Author = CASE id
WHEN 1 THEN '黄飞鸿'
WHEN 2 THEN '方世玉'
WHEN 3 THEN '洪熙官'
END
WHERE id IN (1,2,3)如果更新多个值,只需要稍微修改即可:
UPDATE categories SET dingdan = CASE id WHEN 1 THEN 3 WHEN 2 THEN 4 WHEN 3 THEN 5 END, title = CASE id WHEN 1 THEN 'New Title 1' WHEN 2 THEN 'New Title 2' WHEN 3 THEN 'New Title 3' END WHERE id IN (1,2,3)
至此,一条mysql语句更新多条记录就完成了。
PHP中使用数组赋值批量更新的代码:
$display_order = array( 1 => 4, 2 => 1, 3 => 2, 4 => 3, 5 => 9, 6 => 5, 7 => 8, 8 => 9 ); $ids = implode(',', array_keys($display_order)); $sql = "UPDATE categories SET display_order = CASE id "; foreach ($display_order as $id => $ordinal) { $sql .= sprintf("WHEN %d THEN %d ", $id, $ordinal); } $sql .= "END WHERE id IN ($ids)"; echo $sql;
在此示例中,有 8 条记录需要更新。代码也很容易理解。你学会了吗?
从测试结果来看,测试时使用into更新bar数据的性能更好。
into 和 into on key 之间的区别是:
相似点:
(1) 无键时与..on相同。
(2) 当有键时,保留主键值并自动+1。
差异
当有一个key的时候,它是一条旧记录,有新记录进入,那么所有原来的记录都会被清除。此时,如果语句的字段不完整,则会自动填充一些原始值如示例中的c字段。 为默认值。
而..只执行该标记后的sql,表面上相当于一条简单的语句。
但其实根据我的推测,如果是简单的语句,是不会+1的,应该是先做,然后,并且过程中只保留除以下字段之外的所有字段的值。
所以两者之间只有一处区别。 .. on 保留所有字段的旧值,然后覆盖它们,然后将它们相加。它不保留旧值,而是直接删除新值。
从底层执行效率来说,比...on高效,但是写入时必须写入所有字段,防止旧字段数据被删除。
例子
创建测试表:注意key是code:key(code)
- 1
- 1
常规 into 只影响一行。测试表数据:
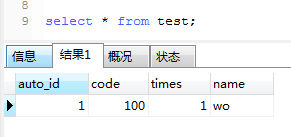
1. 进入…
到现有的密钥中:
- 1
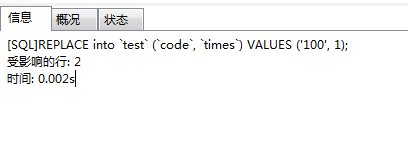
2条线路受到影响。测试表数据:
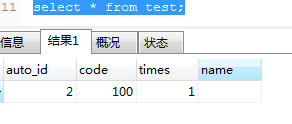
显然,增加了1,name值为空,times更新为2。这说明当key冲突时,相关字段被覆盖,其他字段填充默认值。这可以理解为删除具有重复键的记录并插入新记录。该语句执行+操作,因此该语句影响2行。
当进入不存在的键时:
- 1
只有一行受到影响,相当于只执行了一项操作。测试表数据:
2.进入按键
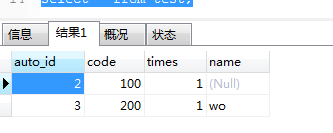
现有密钥:
- 1
2条线路受到影响。测试表数据:
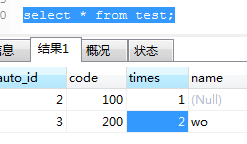
显然,名称保持不变,times更新为2。这说明当与key冲突时,相关字段被覆盖,其他字段保留原来的值。这可以理解为删除具有重复键的记录并插入新记录。该语句执行+操作,因此该语句影响2行。至于是否有自增,我们看一下他插入不存在的key的时候。如果有自增则下一条记录为5,否则为4。
不存在的密钥:
- 1
1 行受影响。测试表数据:
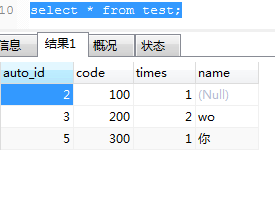
显然,当into on key已经存在时,key会自动增加。当key不存在时,相当于只执行操作。
根据上面的例子,我们可以发现结论和我们一开始列出的异同是一样的。
如果在语句末尾指定ON KEY,则插入行会导致索引或KEY中出现重复值,则将执行旧行;如果它不会导致重复的唯一值列,则会插入新行。例如,如果列 a 定义为并包含值 1,则以下两个语句具有相同的效果:
(一、二、三)
(1,2,3)c=c+1;
=c+=1;
如果该行作为新记录插入,则受影响的行值为1;如果原始记录被更新,则受影响行的值为2。
如果想了解更多INTO..ON KEY的功能说明,详细参见MySQL参考文档:
现在问题来了,如果有多行记录,如何指定ON KEY后字段的值呢?你需要知道一条语句中只能有一个ON KEY,是会更新一行记录,还是会更新所有需要更新的行。这个问题困扰了我很长时间。其实所有的问题都是通过使用()函数来解决的。
例如,字段a定义为,原数据库表中已存在记录(2,2,9)和(3,2,1)。如果插入的记录的a值与原始记录重复,则原始记录将被更新。有记录,否则插入新行:
(一、二、三)
(1,2,3),
(2,5,7),
(3,3,6),
(4,8,2)
b=(b);
上述SQL语句执行过程中,发现a in(2,5,7)与原记录(2,2,9)存在唯一值冲突,则执行ON KEY更新原记录(2 ,2,9) 到 (2,5,9),更新 (3,2,1) 到 (3,3,1),插入新记录 (1,2,3) 和 (4,8,2)
注意:ON KEY只是MySQL特有的语法,不是SQL标准语法!
还有一种我在编写临时脚本时偶尔使用的惰性方法。实现起来很简单,速度肯定不如插入法快,但是相对于逐一更新,效果还是相当明显的。
即在循环之前直接启动事务,循环结束后一起提交,省去了每次连接数据库、解析SQL语句的时间。 (注:如果数量太大,最好分批提交,比如一次1000件,分批提交)
扫一扫在手机端查看
-
Tags : replace into values 批量
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 