
一、简介
无论是在面试中还是在日常工作中,你都会或多或少地使用或听到别人谈论索引技术。
然而,大量程序员对索引的理解仅限于“添加索引可以使查询更快”的概念。
使用索引也非常简单。 不过,会不会使用索引是一回事,深入理解索引原理并能够恰当地使用索引又是另一回事。
这已经是两个截然不同的技术层面了。
2、千万级数据表索引与无索引查询效率对比
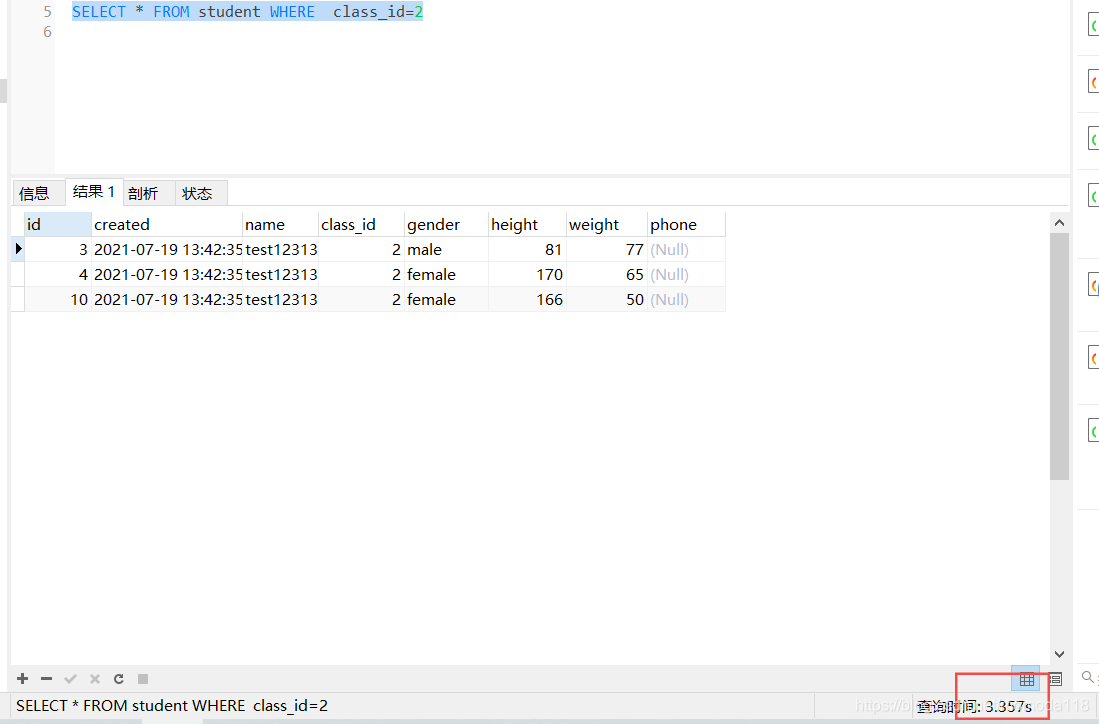
现在有一张表,有1000万条数据
没有索引的情况下,查询=2的学生信息耗时: * FROM WHERE =2 耗时3.357秒
包含索引,查询=2的学生信息耗时: * FROM WHERE =2 耗时0.017秒
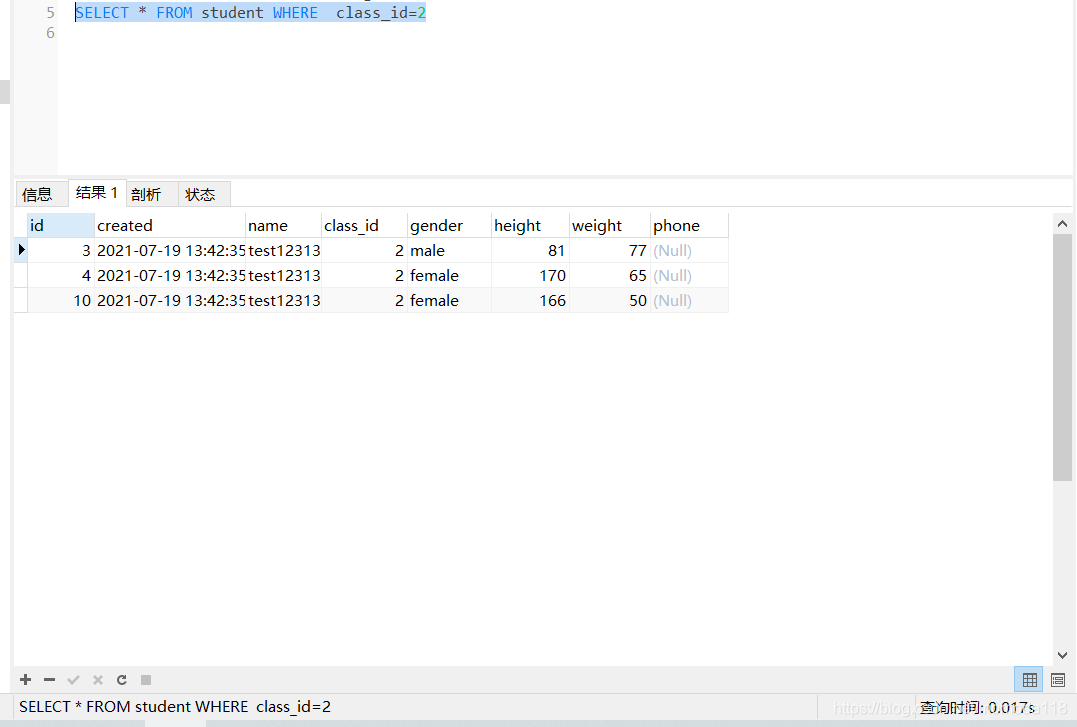
1000万条数据,两次查询的性能差了近200倍! !
这个差距实在是太大了! 难怪你需要添加索引! ! !
3.什么是索引?
网上很多解释索引的文章都是这样描述索引的:
索引就像一本书的目录。 通过一本书的目录,可以准确定位该书的具体内容。
这句话概括得非常正确!
但说出来和不说是一样的。 懂的人自然会懂! 不懂的人感觉自己懂了,但还是很困惑!
其实想要了解索引的原理,就必须知道一个数据结构:
“平衡树”(非二叉树),即b树或b+树
当然,有些数据库也使用哈希桶作为索引数据结构。 然而,主流的RDBMS使用平衡树作为数据表的默认索引数据结构。
我们通常在创建表的时候给表添加一个主键。 在某些关系数据库中,如果建表时没有指定主键,数据库会拒绝执行建表语句。
事实上,有主键的表不能称为“表”。 对于没有主键的表来说,它的数据是乱序放置在磁盘存储上的,并且是一行一行整齐排列的。
如果给表分配一个主键,那么表在磁盘上的存储结构就从整齐排列的结构转变为树形结构,也就是前面提到的“平衡树”结构。 换句话说,整个表变成了一个索引。
是的,再次,整个表变成了索引!
这就是所谓的“聚集索引”。 这就是为什么一张表只能有一个主键,一张表只能有一个“聚集索引”,因为主键的作用就是将“表”的数据格式转换成“树(索引)”格式。
在不添加索引的情况下,之前执行的查询SQL会导致数据库系统逐行遍历整个表,对于每一行,检查其字段是否等于“2”。 因为我们要找到所有值为“2”的员工,所以当我们找到值为“2”的记录时,我们不能停止搜索,因为可能还有其他等于“2”的记录。
这意味着对于表中的数千万条记录,数据库必须检查每一条记录。 这称为“全表扫描”
添加索引最大的作用就是加快查询速度。 它可以从根本上减少需要扫描的记录/行数。
4.Mysql中的索引
在MySQL中,索引有两种分类方法:逻辑分类和物理分类。
按照逻辑分类,索引可以分为:
主键索引:一张表只能有一个主键索引,不允许重复或NULL;
唯一索引:不允许数据列重复,允许NULL值。 一张表可以有多个唯一索引,但一个唯一索引只能包含一列。 例如身份证号、卡号等可以作为唯一索引;
普通索引:一张表可以创建多个普通索引,一个普通索引可以包含多个字段,允许数据重复和NULL值插入;
全文索引:使关键字搜索更加高效的索引。
根据物理分类,该指标可分为:
聚集索引:一般是表中的主键索引。 如果表中没有显示指定的主键,则选择表中第一个不允许为NULL的唯一索引。 如果仍然没有NULL,则将使用存储引擎构建每行数据。 6 字节 ROWID 充当聚集索引。 每个表只有一个聚集索引,因为聚集索引中键值的逻辑顺序决定了表中对应行的物理顺序。 聚集索引在精确搜索和范围搜索方面都有很好的性能(相对于普通索引和全表扫描),聚集索引极其珍贵,聚集索引的选择要谨慎(一般情况下,你不会允许语义上不智能的自动搜索)。 增加id作为聚集索引);
非聚集索引:该索引中索引的逻辑顺序与磁盘上行(非主键列)的物理存储顺序不同。 一个表可以有多个非聚集索引。
在最常用的MySQL存储引擎中,都是采用B+Tree索引方法来创建索引。
B+树索引是B+树在数据库中的一种实现。 它是数据库中最常见、最常用的索引。
B+树中的B代表平衡(),而不是二叉(),因为B+树是从最早的平衡二叉树演化而来的。 首先了解二叉搜索树、平衡二叉树()和平衡多路搜索树(B-Tree)。 B+树是由这些树逐步优化而成的。
具体解释可以参考:这篇博客。
5. 索引的优点和缺点
优势:
1、索引可以提高数据检索的效率,降低数据库的IO成本。
2、通过创建唯一索引,可以保证数据库表中每一行数据的唯一性,创建唯一索引。
3、使用分组和排序子句进行数据检索时,查询中分组和排序的时间也可以显着减少。
4、为了加快两个表之间的连接速度,通常会在外键上创建索引。
缺点:
1. 创建和维护索引需要时间,并且这个时间随着数据量的增加而增加。
2、索引需要占用物理空间。 除了数据表占用的数据空间外,每个索引还占用一定的物理空间。 如果要建立聚集索引,需要的空间会更大。
3、在表中增删改数据时,必须动态维护索引,降低了数据维护速度。
6.什么时候应该使用索引?
需要创建索引的情况:
1.主键,自动创建唯一索引
2. 经常作为查询条件的字段
3、查询中与其他表关联的字段之间存在外键关系。
4. 对查询中的字段进行排序。 如果通过索引来访问排序字段,排序速度将会大大提高。
5. 查询中的统计或分组字段
避免创建索引:
1、数据唯一性差的字段不要使用索引。
例如,性别只有两种可能的数据。 这意味着索引的二叉树层次较少且大多平坦。 这样的二叉树搜索就相当于全表扫描。
2.不要对频繁更新的字段使用索引。
例如,登录次数的频繁变化导致索引频繁变化,增加了数据库的工作量,降低了效率。
3、where语句中没有出现字段时不要添加索引
只有当where语句出现时,mysql才会使用索引
4. 不要对数据量较小的表使用索引。
使用后没有太大改善
7. 哪些SQL可以命中索引?
1、主导模糊查询不能使用索引,比如name like '%Tao'
2、union、in,或者可以命中索引,建议使用in。
3、负条件查询不能使用索引,可以优化成in查询,其中就有负条件! =、、不在、不、不喜欢等。
4、联合索引最左前缀原则,也叫最左查询。 如果在(a,b,c)这三个字段上建立联合索引,那么可以加快a|(a,b)|(a,b,c)三组的查询速度。
5、建立联合查询时,区分度最高的字段在最左边。
6、如果建立了(a,b)联合索引,则无需创建单独的索引。同理,如果创建了(a,b,c)索引,则无需创建a , (a, b) 再次索引。
7、当存在非等号和等号混合判断条件时,建索引时必须将等号条件列放在前面。
8. 范围列可以使用索引,但范围列之后的列不能使用索引。
该索引最多可用于一个范围列。 如果查询条件中有两个范围列,则不能完全使用索引。 范围条件包括:=等。
9. 将计算放在业务层而不是数据库层。 字段上的计算无法命中索引,
10.强制类型转换会扫描整个表。
如果phone字段是phone类型,下面的SQL无法命中索引。 * 其中电话=
11、不适合在更新非常频繁、数据差异性较低的字段上创建索引。
更新会改变B+树,对频繁更新的字段建立索引会大大降低数据库性能。
“性别”是一个不太区分的属性。 创建索引是没有意义的。 无法有效过滤数据。 性能与全表扫描类似。
一般情况下,区分度达到80%以上即可建立指数。 可以使用 count((列名称))/count(*) 来计算差异。
12、使用覆盖索引进行查询操作,避免回表。
查询列的数据可以从索引中获取,而不是通过定位器先行再行,即“查询列必须被建的索引覆盖”,这样可以加快查询速度。
13.索引列不能为空,使用not null约束和默认值。
14、使用延迟关联或者子查询来优化多种分页场景。
MySQL 不会跳过行,而是获取+N 行,然后放弃前一行并返回N 行。 当它特别大时,效率就很低。 您必须控制返回总数或重写超过特定阈值的页面的 SQL。 。
15、具有独特业务特征的字段,即使是多个字段的组合,也必须建立唯一索引。
16、超过三个表时最好不要使用join。 需要连接的字段的数据类型必须一致。 查询多表时,确保相关字段需要有索引。
17、如果明确查询结果只有一个,限制1可以提高效率,比如验证登录时。
18、语句必须指定字段名
19、如果排序字段不使用索引,则尽可能少排序
20. 尝试使用union all而不是union。 Union需要合并集合,然后进行独特的过滤操作,这会涉及排序,大量的CPU操作,增加资源消耗和延迟。 当然,使用union all的前提是两个结果集中没有重复的数据。
八、总结
索引是一项非常重要的技术!
不过,每次创建索引时,实际上都需要在硬盘上开辟一块空间来存放索引所需的数据结构(虽然表述不准确,但就是这个意思),所以不推荐为太长的字段创建索引。
而且,创建的索引越多越好,因为索引虽然可以提高查询效率,但是会极大地影响插入、删除、修改的效率,因为每次数据的更新都会涉及到对索引的修改。
综上所述,在插入大量数据时,我们往往需要先删除数据表的索引,然后在插入完成后重新建立索引,从而最大限度地提高数据库的效率!
扫一扫在手机端查看
-
Tags : 索引越多查询效率越高吗
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 