
为何设立表分区?如何进行分区操作?哪些是常见的分区指令?总结要点。
松哥先前已撰写文章向各位介绍了如何利用MyCat实现MySQL的分库分表操作。不知是否有朋友对此有所探究。实际上,MySQL本身也具备分区功能。我们能够构建一个包含分区的表格,而且无需依赖任何外部工具。今天,我们就来共同探讨这一话题。
1. 什么是表分区
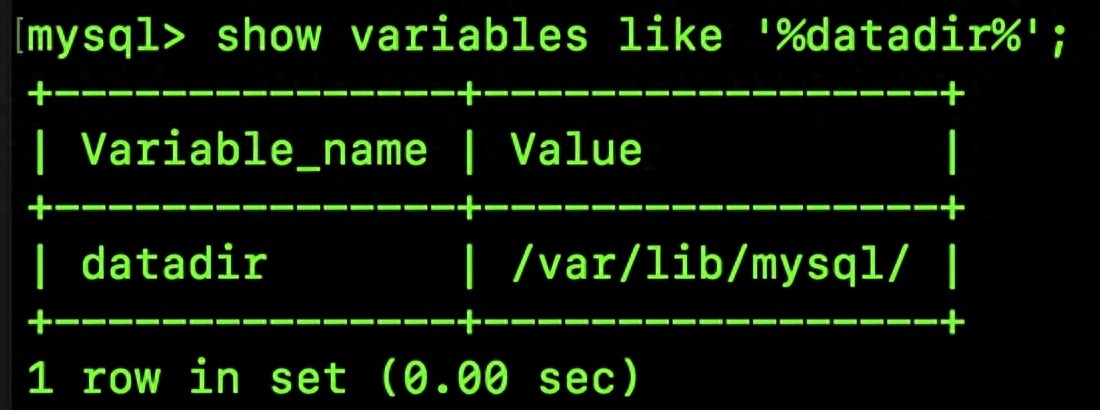
进入该目录后,我们将发现所定义的全部数据库,每个数据库对应一个文件夹,其中包含相应的表格信息,具体如下:
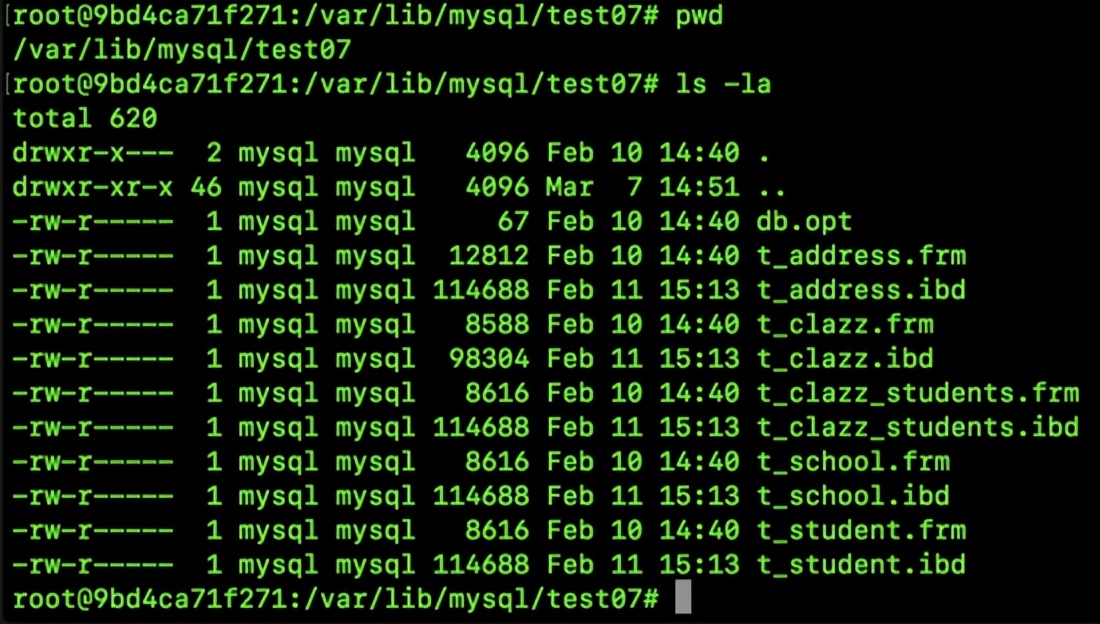
在 MySQL 数据库中,若选用的存储引擎为特定类型,那么在 data 文件夹中,您将观察到三种不同类型的文件,它们分别是 .frm、.myi 和 .myd 文件,各自承担着以下功能:
*.frm文件用于定义表结构,它是一个描述表格组成的文档。*.myd文件则是存储表格数据的文件,它包含了具体的数据信息。*.myi文件则是记录索引信息的文件。
若采用的存储引擎为特定类型,那么在data目录中,您将观察到两种类型的文件:分别是.frm和.ibd文件,它们各自承担着以下功能:
.frm文件代表的是表结构文件,而*.ibd文件则存储着表的数据和索引信息。
无论采用何种存储机制,一旦某张表格的数据规模超出了限度,便会使*.myd、*.myi以及*.ibd等文件体积膨胀,进而使得数据检索的速度显著降低。
为了应对这一挑战,我们可以借助MySQL的分区特性,将这张表的物理文件切分成众多部分。这样一来,在检索特定数据时,我们无需对整个文件进行扫描,只需确定数据所在的具体数据块,随后在该数据块内进行搜索即可。此外,若某张表的数据量过于庞大,以至于无法被单个磁盘容纳,那么通过实施表分区策略,我们便可以将数据分散存储到多个磁盘上。
自MySQL 5.1版本起,引入了对数据分区的功能,这一过程涉及将单一表或索引拆分成为若干更小、便于管理的单元。对于开发者来说,分区后的表格在应用上与未分区时几乎相同,只是物理存储方面有所区别,原本的单一数据文件现在演变为多个,每个分区均作为一个独立实体存在,既可以独立操作,亦能作为更大整体的一部分参与处理。
需要特别指出的是,分区操作并非在存储引擎层面进行,诸如 、、NDB 等常见的存储引擎均具备分区功能。然而,并非所有存储引擎都提供这一功能,例如 CSV、、MERGE 等存储引擎则不支持分区。因此,在启用分区功能之前,有必要详细了解所选存储引擎是否支持分区。
2. 分区的两种方式
MyCat 允许进行垂直和水平的分割操作,而 MySQL 数据库仅支持水平分区,不提供垂直分区的功能。
2.1 水平切分
先来一张简单的示意图,大家感受一下什么是水平切分:
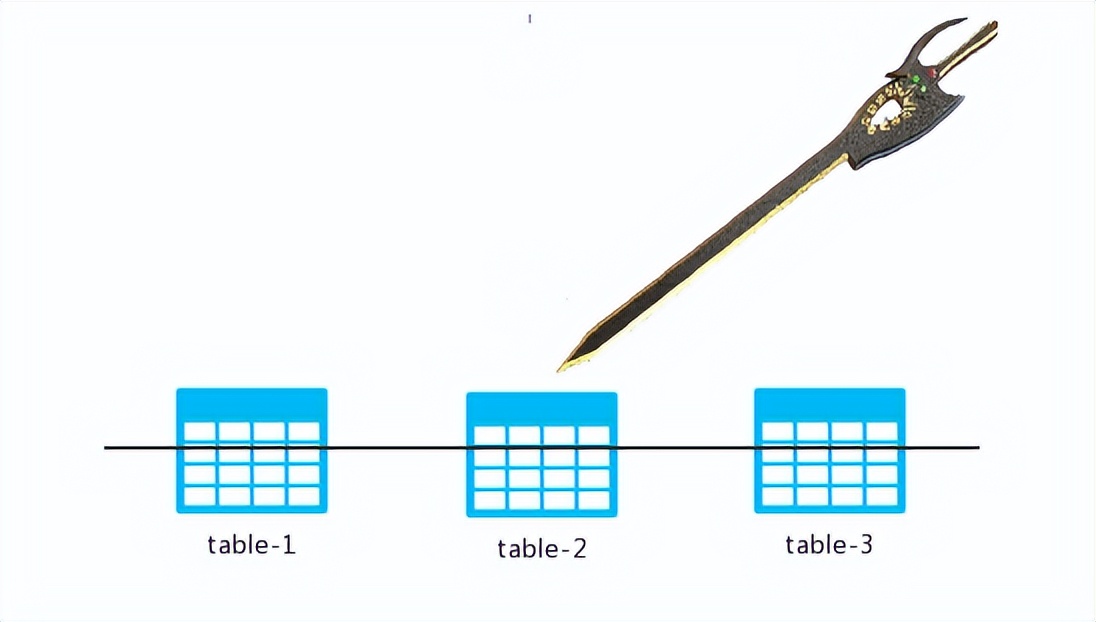
若我的数据库中存在table-1、table-2和table-3这三张表格,进行水平切分的过程,就好比手持一把40米长的巨刀,瞄准那道黑色的线条,挥舞一剑,或者连续挥舞N剑!
砍伐完毕后,需将所砍割的资料转移至另一数据库副本,其结构将呈现如下形态:
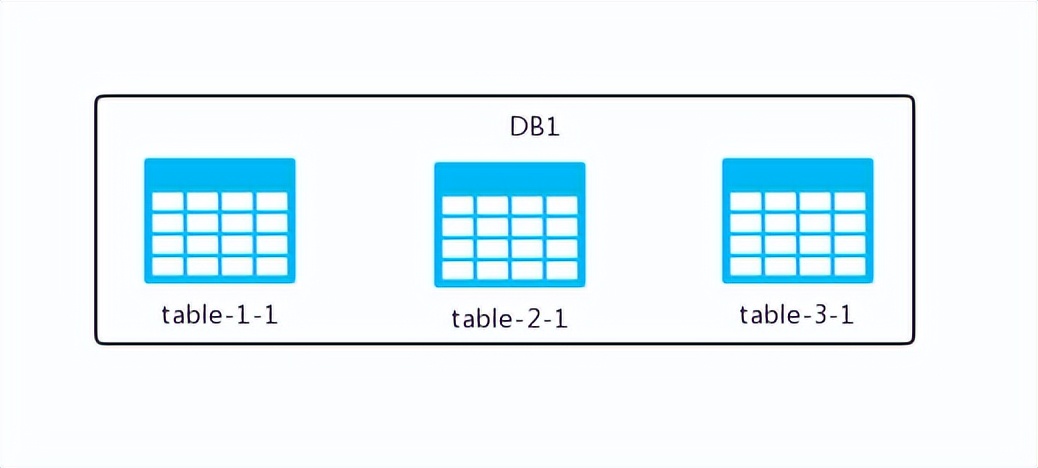
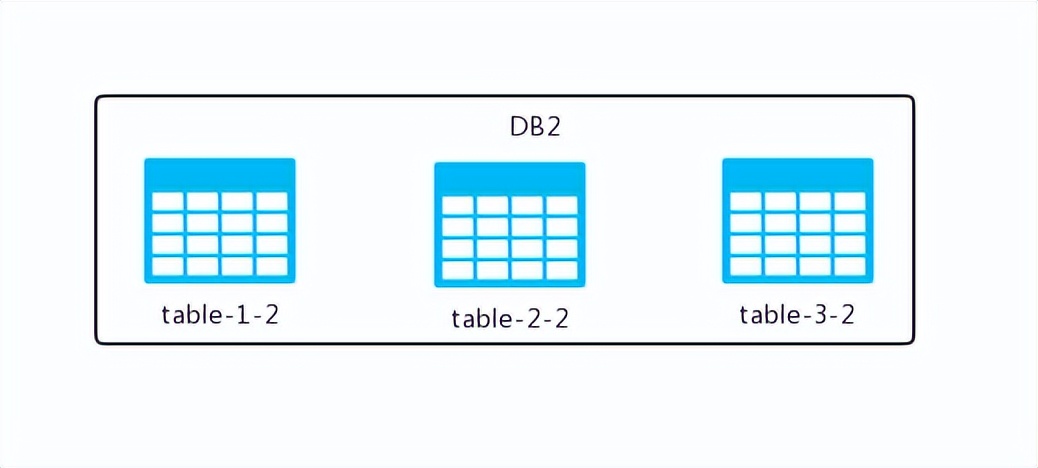
如此一来,原本集中在一个数据库中的表格如今分散到了两个数据库中,经过观察我们发现:
两个数据库中的表格数量保持不变,与之前相同,无论是之前还是现在,表的数量都没有增减。然而,每个表格里的数据却并不完整,因为数据已经被分散到了不同的数据库中。
这就是数据库的水平分割技术,换句话说,它就是基于数据行的分割方式,具体来说,是根据表中某个特定字段的特定规则,将表中的数据分散存储到多个数据库中。在这种分割方式下,每个数据库中只保存了部分数据,但表的结构本身并未发生改变。
2.2 垂直切分
先来一张简单的示意图,大家感受一下垂直切分:
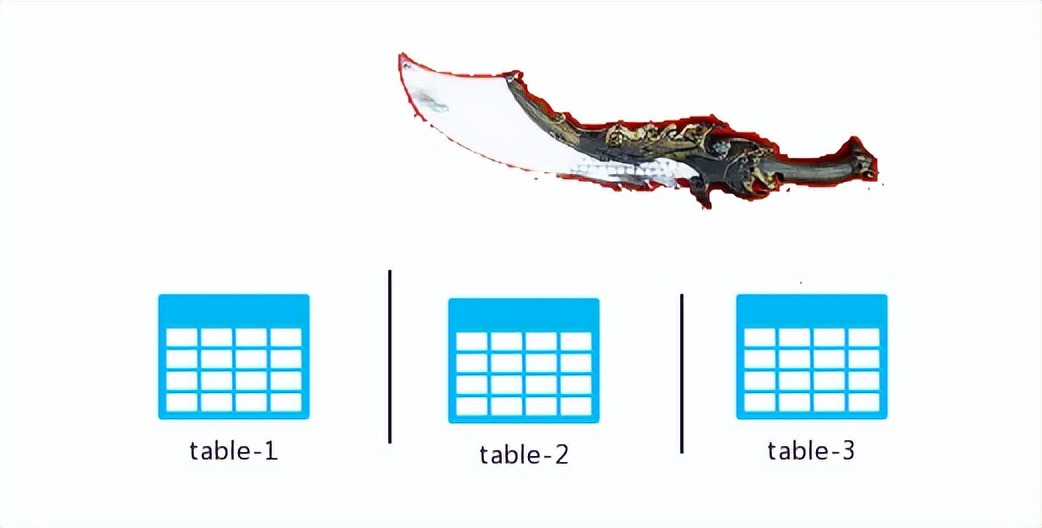
所谓的垂直分割,便是手持我那40米长刀,瞄准那黑色线条进行切割。切割完毕后,将分割后的表格分别存入各自对应的数据库实例中,呈现如下状态:
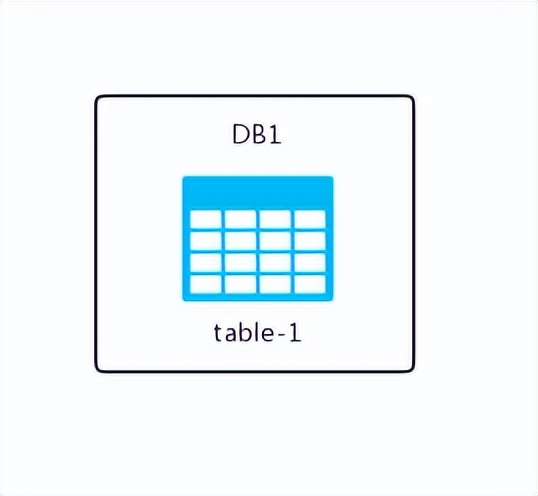
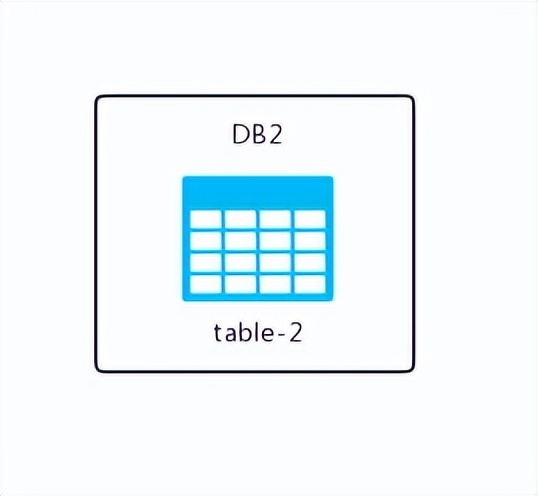
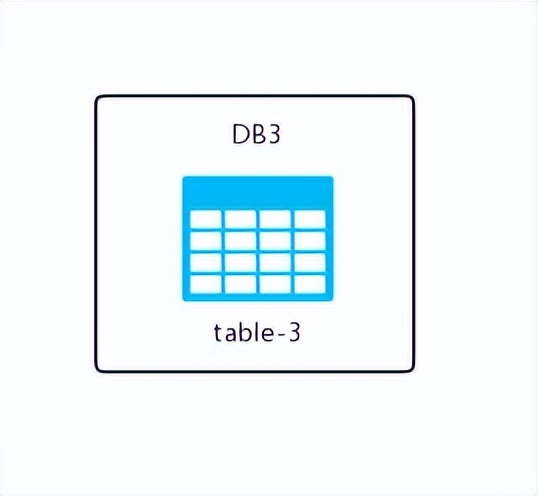
这个时候我们发现如下几个特点:
每个数据库实例所包含的表格数量并不齐全,而同一实例中的表格数据却是完整无缺的。
这就是所谓的垂直分割。通常情况下,我们可以依据业务类型来进行垂直分割,将属于不同业务的表格分别存放在各自的数据库实例里。
MySQL 数据库支持的分区类型为水平分区。
此外,MySQL数据库的分区采用了局部分区索引的方式,这意味着每个分区不仅存储了数据,还包含了相应的索引。然而,截至目前,MySQL数据库尚不支持全局分区功能,即数据分散存储于不同分区,但所有数据的索引却集中在一个单独的对象中。
表分区的必要性在于它能够使单一表存储更多的数据量。这种分区方式使得数据的维护变得更加便捷,我们能够通过删除整个分区来批量移除大量数据,或者通过添加新的分区来适应新增的数据。此外,对单独的分区进行优化、检查和修复等操作也更为简单。部分查询操作由于能够根据查询条件直接定位到少数分区,因此执行速度会显著提升。分区表中的数据可以分散存储于多个物理设备,以此实现多硬件资源的有效运用。通过分区表,能够有效规避某些特定瓶颈,比如单个索引的并发访问限制、ext3文件系统中inode锁的竞争问题。此外,还能够对单个分区进行备份与恢复操作。
分区的限制和缺点:
每个表最多容纳1024个分区,若分区字段包含主键或唯一索引的列,则所有这些主键列与唯一索引列均需纳入其中。分区表不支持外键约束的使用。NULL值的引入将导致分区筛选失效。此外,所有分区需采用一致的存储引擎。关于分区操作的实践,请予以关注。
说了这么多,来个例子看一下。
首先我们先来查看一下当前的 MySQL 是否支持分区。
自6月1日起,该参数已被取消,取而代之的是使用SHOW。若存在行数和列数相等的情形,则表明系统支持分区,具体可参照以下格式:
确认我们的 MySQL 支持分区后,我们就可以开始分区啦!
接下来我们来看几种不同的分区策略。
4.1 RANGE 分区
RANGE分区操作相对简便,主要是依据某个特定字段的数值来进行数据划分。然而,该字段需满足特定条件,即它必须是主键或者是构成联合主键的若干字段之一。
例如根据 user 表的 id 进行分区:
若id的值低于100,数据应被存入p0分区;而当id的值介于100与200之间(含100,不含200),则数据应被存入p1分区;若id的值达到或超过200,数据则需存入p2分区。
上述规定涵盖了id的所有相关范畴,若缺失第三项规则,则在尝试插入一个id值为300的条目时,系统将出现错误提示。
建表 SQL 如下:
create table user(
id int primary key,
username varchar(255)
)engine=innodb
partition by range(id)(
对分区p0中的数值进行限制,确保其低于100。
将小于200的p1值进行划分。
对分区p2中的数值进行筛选,排除所有小于maxvalue的值。
);
成功创建表格后,我们便转入了 /var/lib/mysql/ 这一文件夹,目的是查看新近创建的表格文件。
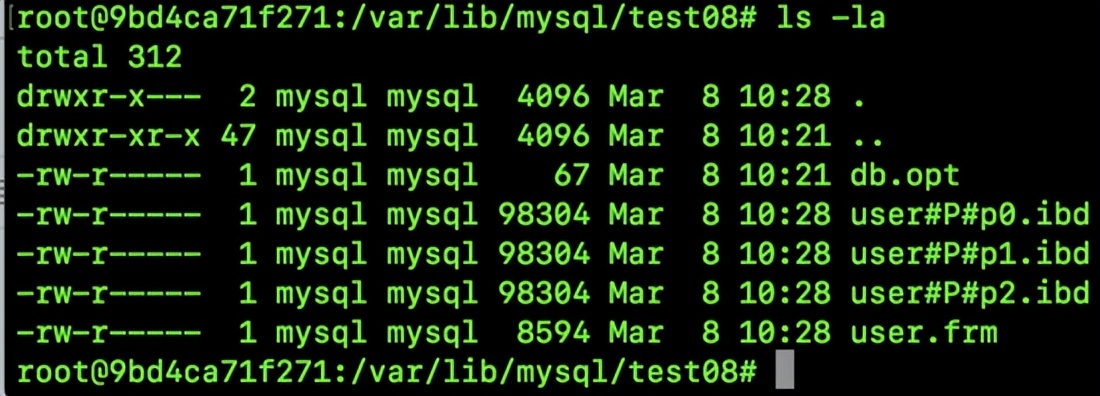
可以看到,此时的数据文件分为好几个了。
. 表中,我们可以查看分区的详细信息:
也可以自己写个 SQL 去查询:
查询information_schema.partitions表中的所有数据,条件是table_schema为'test08',且table_name为'user',执行结果以分号结束。
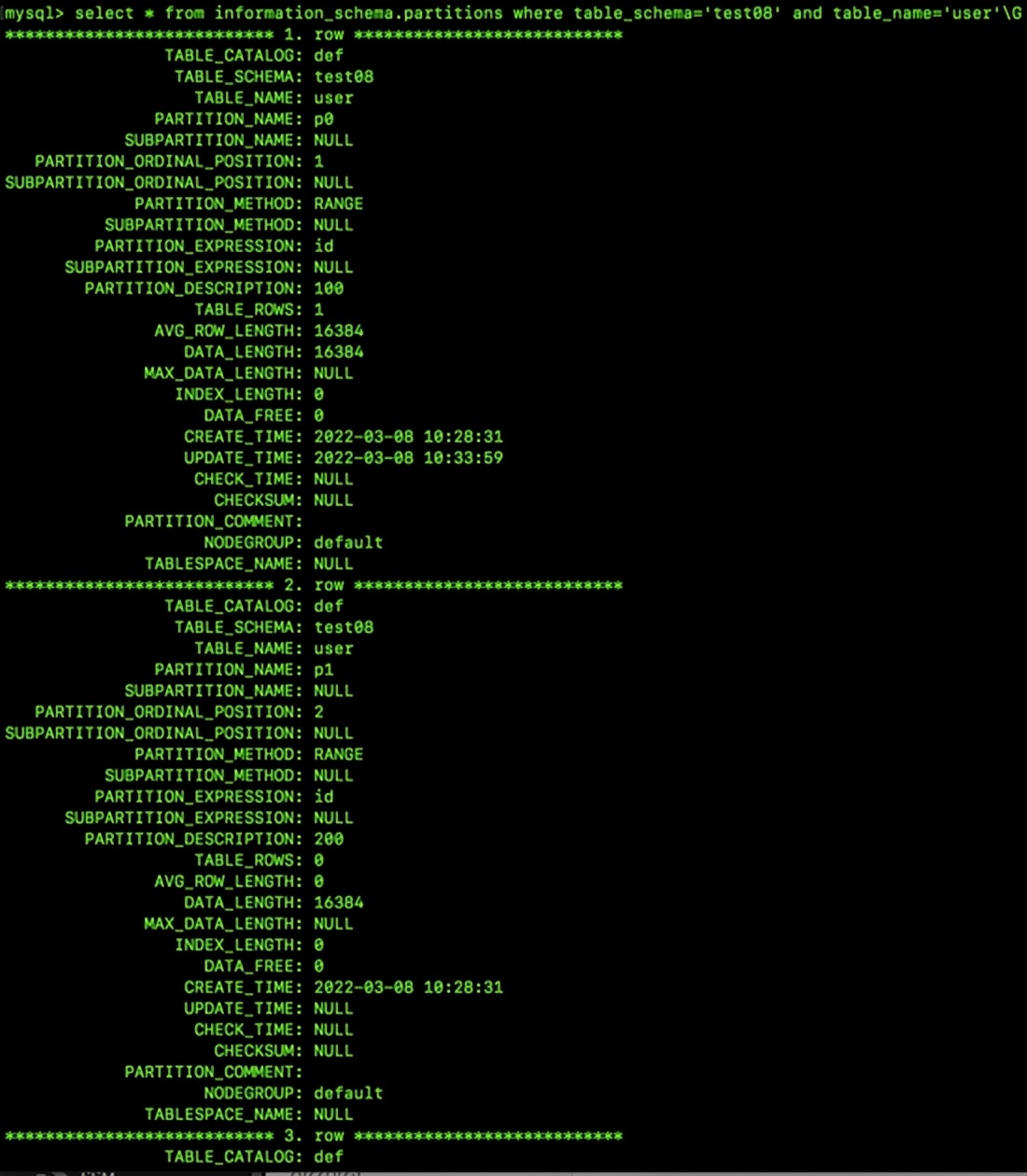
每行均呈现特定区域的数据,涵盖该区域的划分方法、具体覆盖区域、所依据的划分字段以及当前区域内的记录数量等信息。
RANGE分区在实际应用中存在一个显著的应用场景,那就是依据时间对数据库表进行划分。比如,可以将同一年份注册的用户信息集中在一个特定的分区里,具体示例如下:
create table user(
id int,
username varchar(255),
password varchar(255),
createDate date,
primary key (id,createDate)
)engine=innodb
按照年份范围对创建日期进行划分
对2022年的分区值进行筛选,排除那些低于2023年的数值。
对2023年之前的分区值进行限制,不得低于2024年。
对2024年之前的数值进行划分,排除低于2025的数据。
);
它是构成联合主键的一部分。若该字段非主键,仅作为常规属性存在,在创建过程中将触发以下错误:
目前,若需检索2022年度注册的用户信息,系统将仅针对p2022这一特定区域进行检索。这一做法可通过执行计划得到验证,从而证实我们的推断:
若需移除2022年度注册的账户,只需对该分区进行删除操作即可。
对用户表进行修改操作,移除名为p2022的分区。
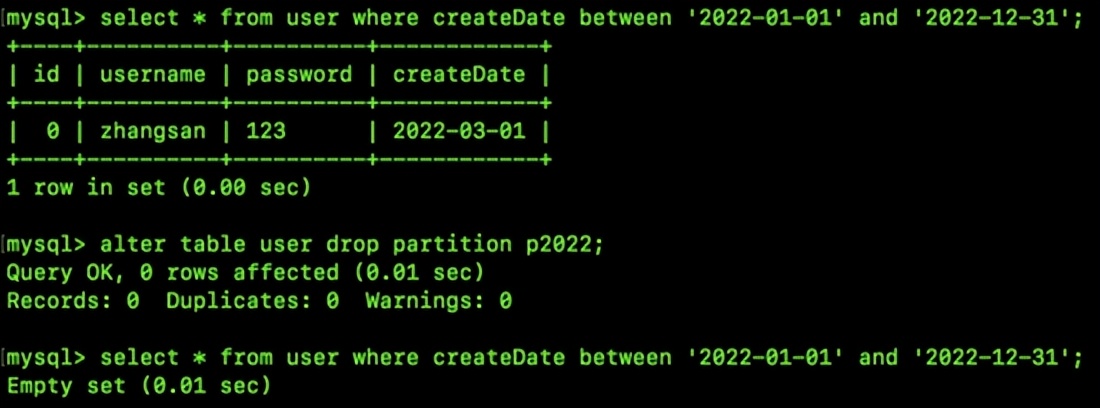
由上图可以看到,删除之后,数据就没了。
4.2 LIST 分区
LIST分区与RANGE分区有相似之处,但二者有所不同。具体来说,LIST分区是依据列值与一个离散值集合中的特定值进行匹配,从而进行数据的选择,而不是基于连续的值。若您能通过一个实例来观察,便更容易理解这一概念了。
若我拥有一张用户资料库,其中包含用户的性别信息,目前我希望依据性别特征对用户数据进行分类存放,具体做法是将男性用户集中保存在一个特定区域,而女性用户则被安排在另一个单独的区域,相应的SQL语句如下:
create table user(
id int,
username varchar(255),
password varchar(255),
gender int,
primary key(id, gender)
)engine=innodb
partition by list(gender)(
将(1)中的价值观念进行划分。
划分女性在(0)中的价值观。
该表格未来将分为两个区域,分别用于存放男性和女性的数据,其数值设定为1或0,若选取其他数值,系统将无法正常执行,最终呈现的执行效果为:
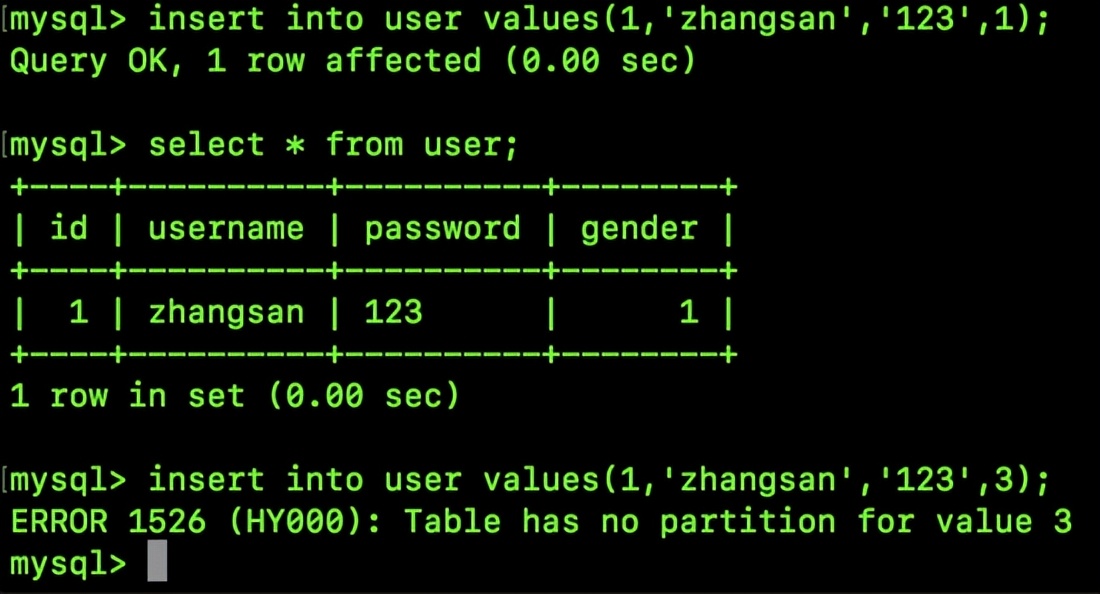
分区域处理之后,未来检索男性信息或女性信息的效率将显著提升,而在删除特定性别用户时,操作效率也会相应提高。
4.3 HASH 分区
HASH分区的主要作用是确保数据被平均分配至预先设定的各个区域,从而确保这些区域的数据量相差无几。在 RANGE 和 LIST 分区模式下,需确切指明某个特定的列值或列值组合应存放在哪个分区;相对地,在 HASH 分区模式下,MySQL 会自动处理这些任务,用户仅需为即将进行哈希分区的列定义一个表达式,并确定分区的具体数量。
在执行表分割操作时,需在 TABLE 语句中通过 BY HASH (expr) 选项来指定 HASH 分区,这里的 expr 可以为一个字段或计算返回整数的表达式;同时,还需通过指定属性来明确分区数量,若未明确指定,系统将默认设置为1个分区。值得注意的是,由于 HASH 分区不支持分区删除,因此不能通过 DROP 操作来移除分区。
create table user(
id int,
username varchar(255),
password varchar(255),
gender int,
primary key(id, gender)
设置引擎为InnoDB,采用哈希分区方式对id字段进行分区,共分为4个分区。
4.4 KEY 分区
KEY分区与HASH分区有相似之处,不过KEY分区能够对除了文本和二进制大对象之外的所有数据类型进行分区,而HASH分区则仅限于对数字类型进行分区。
在KEY分区中,用户不能创建个人定制的表达式来划分区域,而是必须采用系统内置的HASH算法来完成分区的操作。
若数据表中设定了主键或独一无二的索引,在设置 KEY 分区操作时,若未明示指定分区字段,系统将自动优先选取主键列作为分区依据;若表中没有主键列,则会选取非空的唯一索引列来作为分区的依据。
举个例子:
create table user(
id int,
username varchar(255),
password varchar(255),
gender int,
primary key(id, gender)
该语句配置了InnoDB存储引擎,采用基于id字段的键值分区方式,并设置了4个分区。
4.5 分区
分区功能自5.5版本起被引入,目前仅包含RANGE和LIST两种类型;该功能支持整数、日期以及字符串等数据类型;其分区方法与RANGE和LIST的分区方法极为相似。
Vs RANGE Vs LIST 分区:
对于日期类型的分区,无需再借助函数进行转换操作。分区功能允许使用多个字段作为分区依据,然而,它并不支持将表达式用作分区键。
支持的类型
举个例子看下:
create table user(
id int,
username varchar(255),
password varchar(255),
gender int,
createDate date,
primary key(id, createDate)
引擎配置为InnoDB,采用按范围分区的方式,具体依据是列(createDate)。
将分区p0设定为包含小于“1990年1月1日”的值。
对PARTITION p1设定条件,要求其包含的值小于“2000-01-01”。
对分区p2设定条件,使其包含所有小于“2010-01-01”的值。
对分区p3进行设定,其值小于“2020-01-01”。
分区p4包含的数据值均小于最大值。
);
这是 RANGE ,分区值是连续的。
再来看 LIST 分区,这个就类似于枚举了:
create table user(
id int,
username varchar(255),
password varchar(255),
gender int,
createDate date,
primary key(id, createDate)
数据库引擎设置为InnoDB,采用列表分区方式,对(createDate)列进行分区。
PARTITION p0 对应的值域包括,但不仅限于,以下日期:'1990-01-01'。
分区p1中包含的值有:'2000-01-01',以及其他指定日期。
将分区p2的值设定为包含以下日期,即:2010年1月1日。
分区p3针对的值域为“2020-01-01”。
);
5. 常见分区命令添加分区:
对用户表进行修改,新增一个分区,该分区名为p3,用于存储小于4000的值;此操作采用范围分区方式。
对用户表进行修改,增加一个名为p3的分区,该分区包含值域40;这属于列表分区类型。
删除表分区( 会删除数据 ):
对用户表进行修改操作,移除名为p30的分区。
删除表的所有分区(不会丢失数据):
对用户表进行修改,移除分区功能。
重新定义 range 分区表(不会丢失数据):
对用户表进行修改,采用按薪资范围进行分区的方式。
对分区p1中的数值进行筛选,要求这些数值低于2000。
对分区p2进行操作,筛选出值小于4000的数据。
重新定义 hash 分区表(不会丢失数据):
对用户表进行修改,采用哈希分区方式,以薪资字段为依据,新增7个分区。
合并分区:把 2 个分区合并为一个,不会丢失数据:
对用户表进行修改,将分区p1和p2重新组织,并划分为新的分区p1,其值小于1000。原文链接:
&=&=
扫一扫在手机端查看
- 上一篇:mysql独立表空间_MySQL三大日志:binlog、redolog、undolog全解析
- 下一篇:html5 sqlite Python SQLite数据库操作_Python中轻量数据库SQlite3的使用
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 