
随着多模态大型模型 (LMM) 的不断发展,评估 LMM 性能的需求也在增长。 尤其是在中文环境下,评估LMM的先进知识和推理能力变得更加重要。
在此背景下,为了评估基础模型在各类中文任务中的专家级多模态理解能力,MAP开源社区联合香港科技大学、滑铁卢大学和零一玩物联合发起CMMMU(多与)基准。 该基准旨在为大规模多学科多模态中文理解与推理提供综合评估平台。 该基准允许研究人员测试各种任务的模型,并将其多模式理解能力与专业水平进行比较。 该联合项目的目标是促进中文多模态理解与推理领域的发展,并为相关研究提供标准化参考。
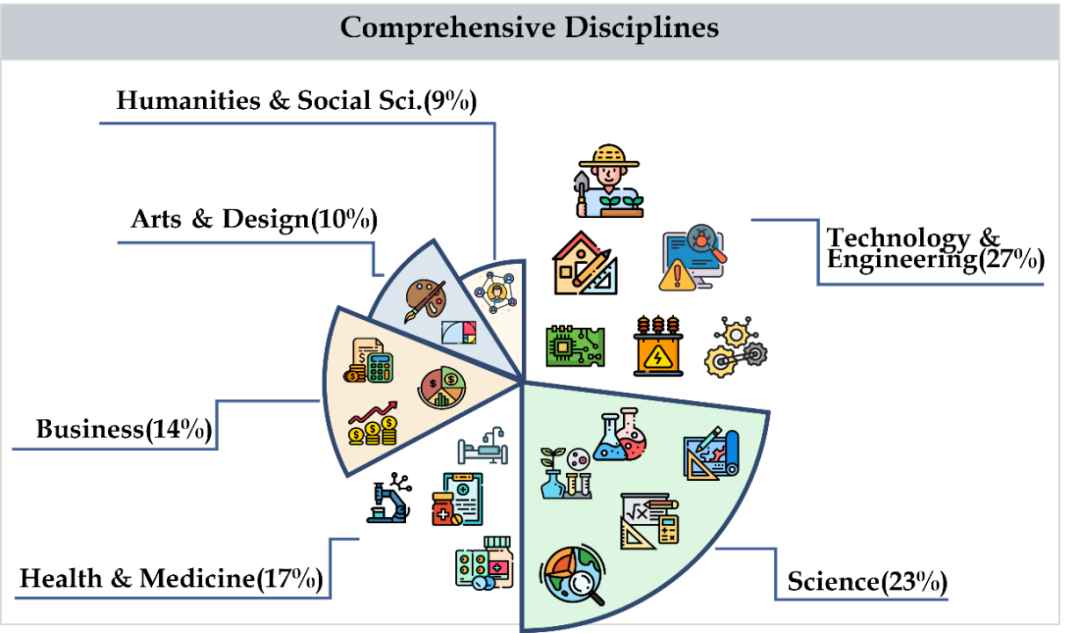
CMMMU涵盖艺术、商学、健康与医学、科学、人文与社会科学、技术与工程等六大类学科门类,涉及30多个子领域学科。 下图显示了每个子领域主题的问题示例。 CMMMU 是中国背景下最早的多模态基准测试之一,也是少数考察 LMM 复杂理解和推理能力的多模态基准测试之一。
数据集构建
数据采集
数据收集分为三个阶段。 首先,研究人员收集了每个符合版权许可要求的主题的问题来源,包括网页或书籍。 在此过程中,他们努力避免题源重复,保证数据的多样性和准确性。 其次,研究人员将问题来源转发给众包标注者进行进一步标注。 所有注释者都是具有学士学位或更高学历的人,以确保他们能够验证注释的问题和相关解释。 在标注过程中,研究者要求标注者严格遵循标注原则。 例如,过滤掉不需要图片来回答的问题、过滤掉尽可能使用相同图像的问题、过滤掉不需要专业知识来回答的问题。 最后,为了平衡数据集中每个科目的问题数量,研究人员特意对问题较少的科目进行了补充。 这样做保证了数据集的完整性和代表性,让后续的分析和研究更加准确和全面。
数据集清理
为了进一步提高CMMMU的数据质量,研究人员遵循严格的数据质量控制协议。 首先,每个问题都至少由论文作者之一亲自验证。 其次,为了避免数据污染问题,他们还筛选出了几位LLM无需借助OCR技术就可以回答的问题。 这些措施保证了CMMMU数据的可靠性和准确性。
数据集概述
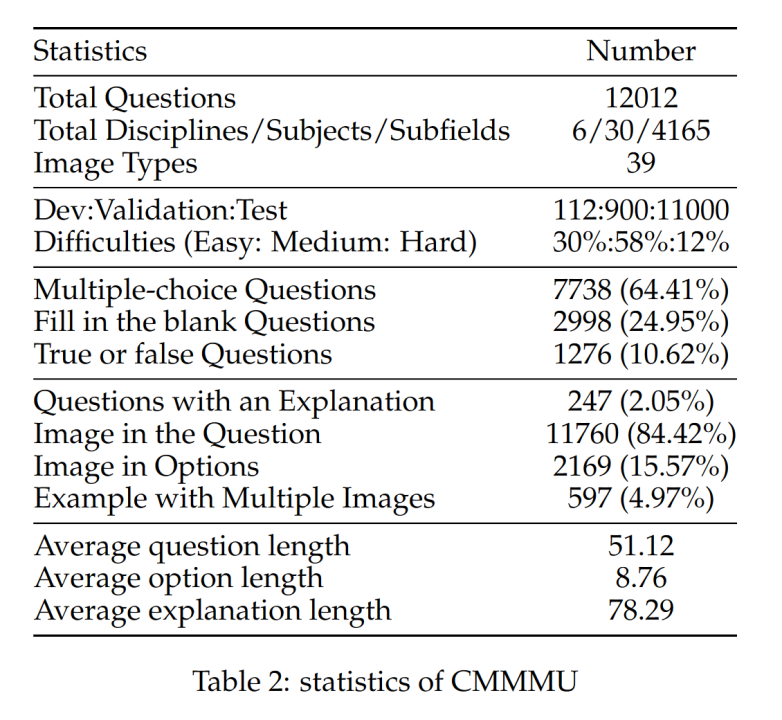
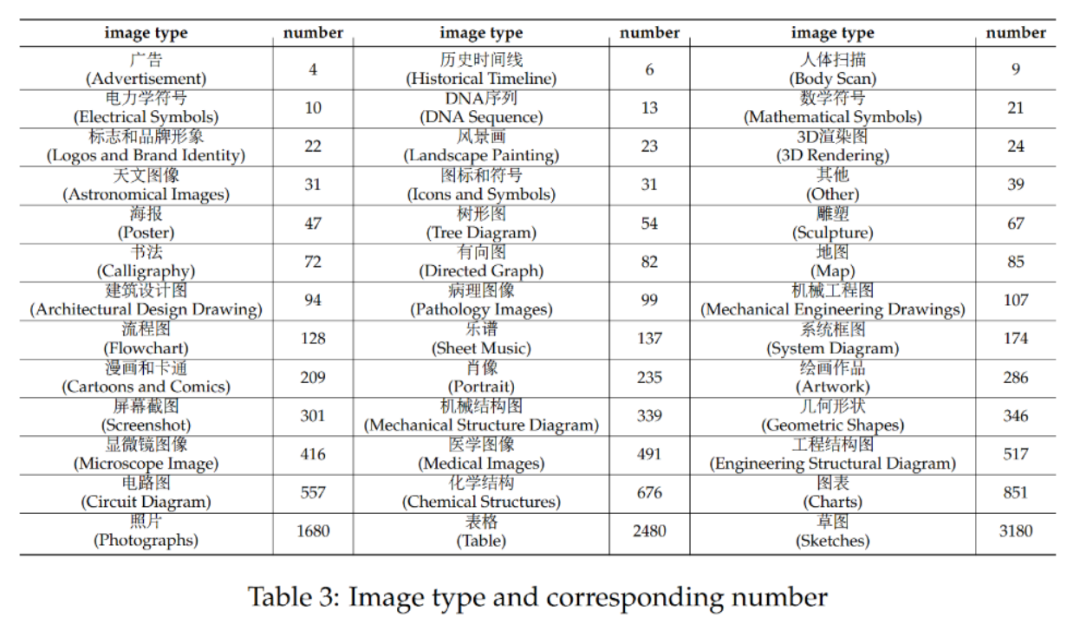
CMMMU共有12K题,分为少样本开发集、验证集和测试集。 少样本开发集包含每个主题约 5 个问题,验证集有 900 个问题,测试集有 11K 个问题。 试题涵盖39种图片,包括病理图、简谱图、电路图、化学结构图等。试题分为简单(30%)、中(58%)、困难(12%)三个难度等级。 %) 基于逻辑难度而不是智力难度。 更多问题统计见表2和表3。
实验
团队在CMMMU上测试了多种主流中英双语LMM和数个LLM的表现。 包括闭源和开源模型。 评估过程使用零样本设置而不是微调或少样本设置来检查模型的原始功能。 LLM还增加了一个以图像OCR结果+文本作为输入的实验。 所有实验均在 A100 图形处理器上进行。
主要结果
表4为实验结果:
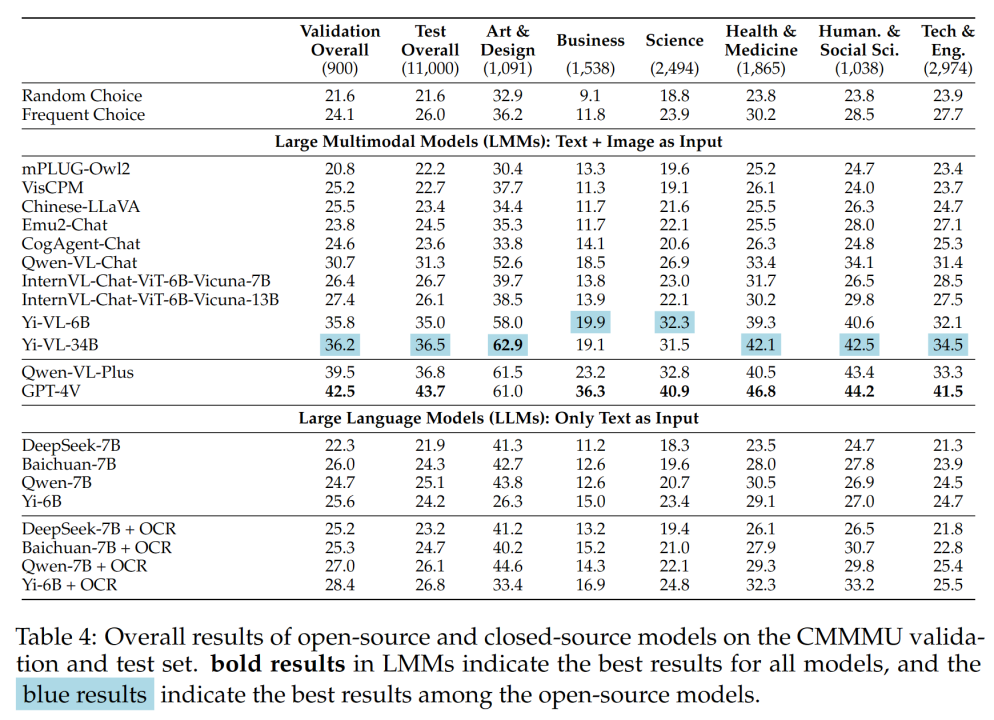
一些主要发现包括:
- cmmmu比mmmu更具挑战性,这是在mmmu已经非常具有挑战性的前提下。
GPT-4V在中文上下文中的准确率仅为41.7%,而在英文上下文中的准确率为55.7%。 这表明现有的跨语言泛化方法即使对于最先进的闭源 LMM 来说也不够好。
- 与MMMU相比,国内代表性开源模型与GPT-4V差距较小。
Qwen-VL-Chat 与 GPT-4V 在 MMMU 上的差异为 13.3%,而 BLIP2-FLAN-T5-XXL 与 GPT-4V 在 MMMU 上的差异为 21.9%。 令人惊讶的是,Yi-VL-34B 甚至将开源双语 LMM 与 GPT-4V 在 CMMMU 上的差距缩小到 7.5%,这意味着在中文环境下,开源双语 LMM 与 GPT-4V 相当,即开源社区中一个有希望的进步。
- 在开源社区,中国专家追求多模态通用人工智能(AGI)的游戏才刚刚开始。
团队指出,除了最近发布的 Qwen-VL-Chat、Yi-VL-6B 和 Yi-VL-34B 之外,所有来自开源社区的双语 LMM 都只能达到与 CMMMU 相当的精度。
不同题型难度及题型分析
- 不同的问题类型
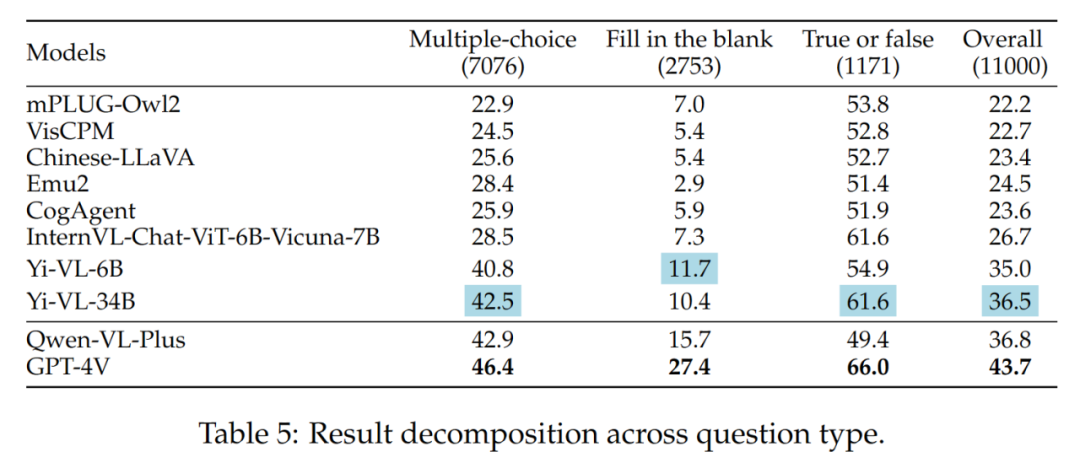
Yi-VL系列、Qwen-VL-Plus和GPT-4V之间的区别主要在于它们回答多项选择题的能力不同。
不同题型的结果如表5所示:
-不同的问题难度
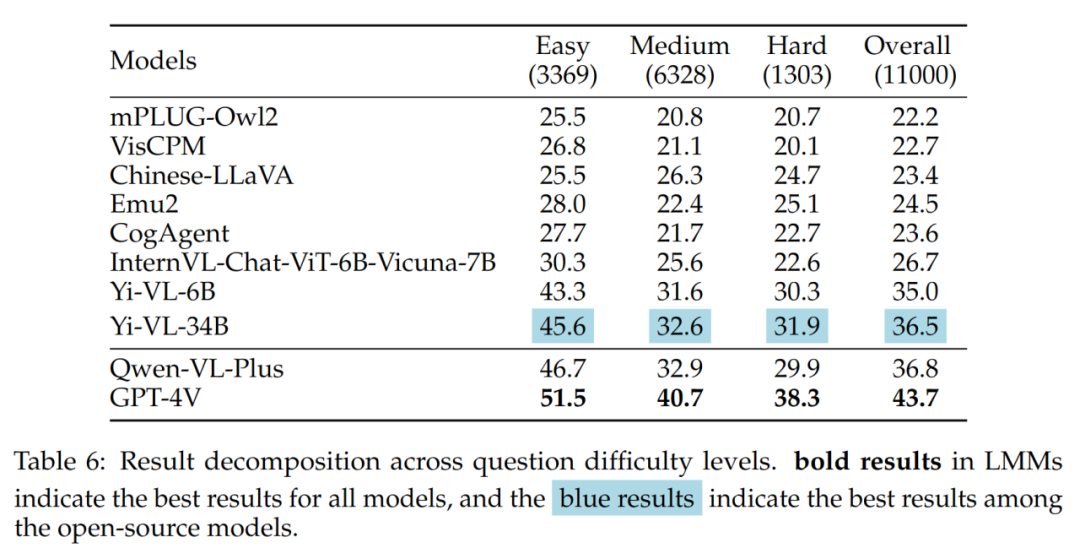
结果中值得注意的是,在面对中难问题时,最好的开源LMM(即Yi-VL-34B)与GPT-4V之间存在较大差距。 这进一步有力地证明了开源LMM与GPT-4V的关键区别在于复杂条件下的计算和推理能力。
不同题目难度的结果如表6所示:
误差分析
研究人员仔细分析了GPT-4V的错误答案。 如下图所示,错误的主要类型有感知错误、知识缺乏、推理错误、拒绝回答、注释错误。 分析这些错误类型是了解当前 LMM 的功能和局限性的关键,也可以指导未来的设计和训练模型改进。
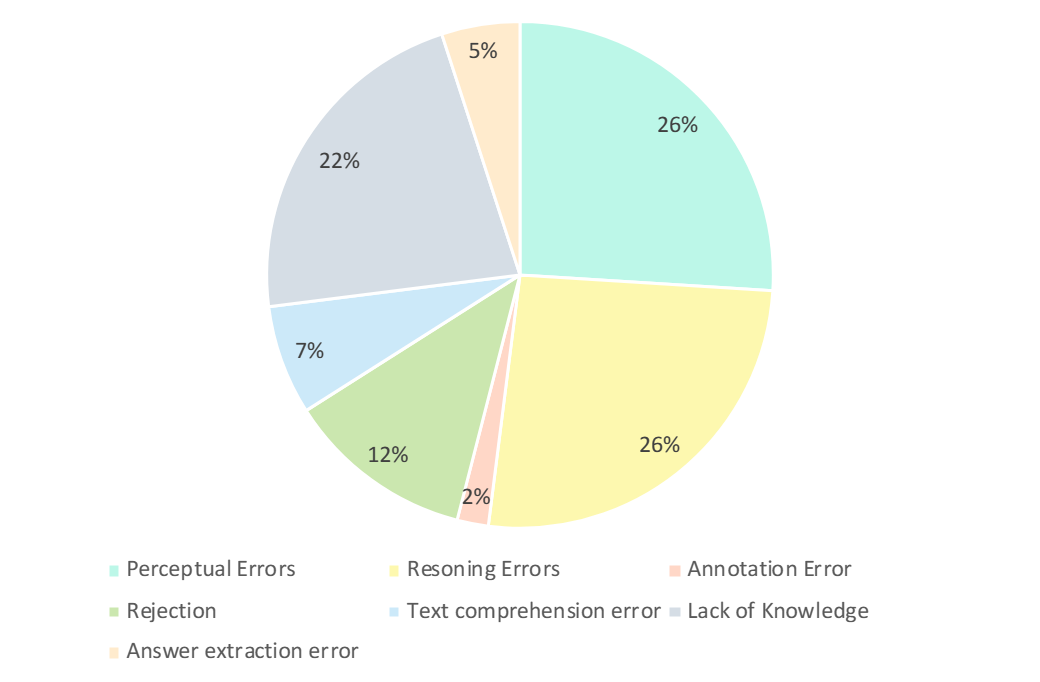
- 感知错误(26%):感知错误是 GPT-4V 产生错误示例的主要原因之一。 一方面,当模型无法理解图像时,就会对图像的潜在感知产生偏差,从而导致错误的响应。 另一方面,当模型遇到特定领域知识的歧义、隐含含义或不清楚的公式时,它通常会表现出特定领域的感知错误。 在这种情况下,GPT-4V往往更多地依赖基于文本信息的答案(即问题和选项),优先考虑文本信息而不是视觉输入,导致对多模态数据的理解出现偏差。
- 推理错误(26%):推理错误是 GPT-4V 产生错误示例的另一个主要因素。 即使模型正确地感知了图像和文本所传达的含义,在解决需要复杂逻辑和数学推理的问题时,推理过程中仍然可能会出现错误。 通常,这种错误是由模型的逻辑和数学推理能力较弱引起的。
- 缺乏知识(22%):缺乏专业知识也是 GPT-4V 答案不正确的原因之一。 由于CMMMU是评估LMM专家AGI的基准,因此需要不同学科和子领域的专家级知识。 因此,向LMM注入专家级知识也是可以努力的方向之一。
- 拒绝回答(12%):模特拒绝回答也很常见。 通过分析,他们指出了模型拒绝回答问题的几个原因:(1)模型未能从图像中感知信息; (2)涉及宗教问题或个人现实生活信息的问题,模型会主动回避; (3)当问题涉及性别和主观因素时,模型避免提供直接答案。
- 其错误:其余错误包括文本理解错误(7%)、注释错误(2%)和答案提取错误(5%)。 这些错误是由多种因素造成的,例如复杂的结构跟踪能力、复杂的文本逻辑理解、响应生成的限制、数据标注的错误以及答案匹配提取中遇到的问题。
综上所述
CMMMU 基准测试标志着先进通用人工智能 (AGI) 发展的重大进步。 CMMMU 旨在严格评估最新的大型多模态模型 (LMM),并测试特定领域的基本感知技能、复杂的逻辑推理和深厚的专业知识。 本研究通过比较汉英双语环境下 LMM 的推理能力指出了差异。 这种详细的评估对于确定模型与每个领域经验丰富的专业人士的熟练程度进行比较至关重要。
以上是适合中国人LMM体质的最新基准CMMMU:包含30多个细分和12K专家级问题的详细内容。 更多信息请关注php中文网其他相关文章!
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 