
交易:并发写入、交易、更大的资源
性能:节省资源,消耗低,业务简单,查询快速
默认用法
5.5 及更高版本
5.5 之前
3.1.6 读写分离
读写分离:读写分离可以有效提高查询性能,主从同步采用bin log和relay log。
3.1.7 数据库与表的划分
分库分表:当数据量达到千万级以上时,可以进行垂直拆分(分库),水平拆分(分表),或者垂直+水平拆分(分库分表)。
概念:
拆分原理:
数据量增长数据表类型优化核心思想
数据量在几千万级,是比较稳定的数据量。
状态表
如果不需要拆卸,请勿拆卸。阅读横向扩展要求
数据量动辄数千万级,甚至可能达到数亿级。
流量计
业务拆分、分布式存储设计
数据量动辄数千万级,甚至可能达到数亿级。
流量计
设计分布式扩展以满足存储数据统计需求
数据量是几千万,不应该有这么多数据
配置表
小而简单,避免大统一
拆分数据库和表的步骤:
MySQL调优:数据量能稳定在几千万,未来几年不会达到几亿,其实也不用着急拆,先试试MySQL调优,优化读写性能。
目标评估:评估要拆分多少个数据库和表。例如:现在值20亿,预计5年后100亿,需要多少张表?多少个数据库?答:合理答案是1024张表。16个数据库按1024张表计算,拆分后每张表200万,5年后就是1000万。1024张表*200万≈100亿
表拆分:
按主键范围拆分:比如[1,200w]个主键在一张表,[200w,400w]个主键在另一张表。优点是单表数据量可控。缺点是流量无法分散,写入操作集中在最后一张表。
中间表映射:可以任意拆分表,引入一个中间表,记录查询的字段值,对应数据在哪个表,优点是灵活,中间表的引入使得流程更加复杂。
Hash :%N,优点是数据分得比较均匀,流量共享,缺点是扩容需要数据迁移,跨节点查询问题。
按分区拆分:哈希、范围等。不建议这样做,因为数据难以水平扩展。
(分表字段)选取:尽量选取查询频率最高的字段,然后按照分表方式进行字段选取。
代码改造:修改代码中的查询、更新语句,适应分片后的情况。
数据迁移:最简单的是停机迁移,比较复杂的是不停工迁移,需要考虑增量同步、全量同步的问题。
全量同步:从旧库迁移数据到新库时,需要控制迁移效率,并解决增量数据的一致性问题。
计划任务:计划任务检查旧库,写入新库 中间件:使用中间件迁移数据
增量同步:从旧数据库迁移到新数据库过程中,新增、删除、修改命令必须正确存储,不能有错误。
同步双写:同步写入新旧数据库;异步双写(推荐):写入旧数据库,监听新数据库异步同步。中间件同步工具:按照一定的规则将数据同步到目标数据库表。
数据一致性校验与补偿:假设采用异步双写方案,迁移完成后,逐条比对新旧库数据,如果一致则跳过;如果不一致则进行补偿:
新库存在,旧库不存在:删除新库数据。新库不存在,旧库存在:在新库插入数据。新库存在,旧库存在:对比所有字段,若不一致,则更新新库为旧库数据
灰度切换:灰度发布是指黑(旧版本)和白(新版本)之间的过渡,让一部分用户继续使用旧版本,一部分用户开始使用新版本,如果用户对新版本没有异议,再逐步将所有用户迁移到新版本,实现平滑过渡发布。原则:
如果出现问题及时切换回旧库,释放音量时先慢后快,每次观察一段时间,支持灵活规则:存储维度灰度、百分比灰度
停旧用新:将旧数据库脱机,使用新数据库进行读写。
3.2 表设计优化 3.2.1 混合业务表、冷热数据表
例如可以将一个大的任务表分离成一个任务表和一个历史任务表,任务表中的任务完成后就移动到历史任务表中,任务表是热数据,历史任务表是冷数据,这样可以提高查询性能。
3.2.2 联合查询改为中间关系表
例如属性表与属性组表不采用连接查询,而是采用“属性-属性组表”来存储各个属性的ID以及“属性关系”。
3.2.3 遵循三大范式
每个属性不能再分,表必须有且只有一个主键,非主键列必须直接依赖于主键
3.2.4 字段推荐Not Null约束
①查询可能存在空指针问题;
②由于忽略了null,导致聚合函数不准确
③不能用“=”来判断,只能用判断;
④null等值运算只能为null,这可能会导致你误以为它被当成了0;
⑤空值比空字符占用的空间更大,空值的长度为0,空字符的长度为1位;
⑥ 如果索引没有被覆盖,is not null 则不能使用索引
3.2.5 使用冗余字段
虽然列不能太多,但是为了查询效率,可以添加冗余字段。
3.2.6 数据类型优化
整数类型:
考虑取值范围,前期可以使用int保证稳定性,尽量使用非负类型,相同字节数的情况下,存储取值范围更大,主键一般使用类型
如果可以使用整数,请不要使用文本类型:
大整数往往比文本类型数据占用更少的存储空间。
避免使用 TEXT 和 BLOB 数据类型:
这两个大数据类型排序时不能使用内存临时表,只能使用磁盘临时表,效率很低,建议不要使用,或者将表分成单独的扩展表,该类型可以存储4G的文件;
避免使用枚举类型:
排序很慢。
使用保存时间:
使用4个字节,使用8个字节,具有自动赋值,自动更新的特点,缺点是只能保存到2038年,.6.4版本可以通过配置参数自动改为类型。
存储浮点数:
该类型为精确浮点数,计算时不会丢失精度,特别适合金融数据。占用空间由定义宽度决定,每4个字节可存储9位数字,小数点占一个字节,可用于存储较大的整数数据。
3.3 索引优化 3.3.1 考虑索引失败的11种情况
详细信息请参考:
MySQL高级版-索引失效的11种情况博客 - CSDN博客
尝试匹配完整值:
当查询年龄和姓名时,(age,,name)索引比(age,)更快。
考虑最左边的前缀:
联合索引把经常查询的列放在左边,索引 (a,b,c) 只能搜索 (a,b,c), (a,b), (a)。
主键应该按以下顺序排列:
如果主键不按顺序,需要找到目标位置再插入,如果目标位置所在的数据页已满,则必须分页,造成性能损耗,可以选择自增策略或者.0有序UUID策略。
计算和函数导致索引失败:
诸如 num+1=2 之类的计算,诸如 abs(num) 之类的函数用于取绝对值
类型转换导致索引无效:
例如,name=123 而不是 name='123'。另一个示例是使用不同的字符集。
范围条件右侧的列索引无效:
例如使用联合索引(a,b,c),查询条件为a,b,c,如果b使用范围查询,则b右边的c索引将失效。建议将需要范围查询的字段放在最后。范围包括:(=)且。
当索引没有被覆盖时,“不等于”会导致索引无效:
由于“不等于”无法精确匹配,因此扫描二级索引树再返回表的效率不如直接扫描聚集索引树。但是使用覆盖索引时,联合索引的数据量较少,加载到内存中所需的空间比聚集索引树要小,而且不需要返回表,因此索引效率比全表扫描聚集索引树要好。
覆盖索引:包含满足查询结果的数据的索引称为覆盖索引,不需要返回表等操作。
当索引没有被覆盖时,左模糊查询导致索引失效:
例如LIKE '%abc'。因为无法准确匹配字符串的开头。原因同上。
当没有覆盖索引、不为空且不类似时不能使用索引:
因为无法准确匹配。原因同上。
“OR”前后有非索引列,导致索引无效:
在MySQL中,即使or左边的条件满足,右边的条件仍然需要被评估。
字符集不同导致索引失败:
建议不同的字符集需要转换后再进行比较,否则索引会失效。
3.3.2 遵循索引设计原则
详细信息请参考:
MySQL进阶版-索引创建与设计原则博客 - CSDN博客
命名:索引字段个数尽量不超过5个,命名格式为“”。索引经常查询的列(特别是分组、范围、排序查询);对于经常更新的表,不要创建过多的具有索引唯一特征的字段,适合创建索引;对于非常长的字段,适合根据区分和长度创建前缀索引;当多个字段需要建立索引时,联合索引比单值索引要好;避免创建过多的索引,避免索引失效;尽量使用有序字段作为主键索引:防止在顺序混乱的情况下,新的主键前移到完整的数据页,导致插入后数据页分裂,造成性能损失;3.3.3 连接查询优化
详细信息请参考:
MySQL进阶版-索引失效的11种情况博客 - CSDN博客
当进行外连接时,优先对驱动表的连接字段建立索引:
外连接查询时,右表为驱动表,建议加索引。因为左表是查询全部数据,右表是按条件查询,所以在右表的条件字段上建立索引更有价值。
inner join的时候优化器自动用无索引驱动索引表,小表驱动大表:
首先选择有索引的表作为驱动表,当两个表都没有索引的时候,查询优化器会自动让小表驱动大表,在驱动表的JOIN字段上建立索引会大大提高查询效率。
两张表的连接字段类型必须一致:
两张表JOIN字段的数据类型必须绝对一致,防止自动类型转换导致索引失效。
3.3.4 子查询优化
详细信息请参考:
MySQL进阶版-索引失效的11种情况博客 - CSDN博客
用连接替换子查询:如果多个表可以直接连接,则直接连接,而不使用子查询。(减少查询次数)。子查询是用作另一个语句的条件的查询结果。
#取所有不为班长的同学
SELECT a.* FROM student a WHERE a.stuno NOT IN (
SELECT monitor FROM class b
WHERE monitor IS NOT NULL
);
#优化成关联查询
SELECT a.* FROM student a LEFT OUTER JOIN class b
ON a.stuno = b.monitor WHERE b.monitor IS NULL;多重查询代替子查询:不建议使用子查询,建议将子查询SQL拆分后与程序合并进行多重查询,或者使用JOIN代替子查询。
3.3.5 排序优化
详细信息请参考:
MySQL高级版-排序、分组、分页优化博客-CSDN博客
3.3.6 分组优化
它的想法基本上和排序相同。
排序和分组会消耗大量的 CPU,所以如果可以的话就不要使用它们。
where 比 where 是先分组后过滤,where 是先分组后过滤更有效。
3.3.7 深度分页查询优化
要求归还
有序主键的表,按照主键排序,先过滤,再排序:直接查范围后的数据。
EXPLAIN SELECT * FROM student WHERE id > 2000000 LIMIT 10;
将无序主键的表按主键排序,先按主键分页,再inner join到原表:inner join到当前表的排序截取的主键表,join字段为主键,因为在聚集索引树中查找主键,不需要返回表,所以排序和分页都很快
EXPLAIN SELECT * FROM student t,(SELECT id FROM student ORDER BY id LIMIT 2000000,10) a WHERE t.id = a.id;
主键有序的表,按照非主键排序:获取上一页最后一条记录x,则目标页面上所有记录id都小于x.id(因为是倒序,而排序依据其实是age,id,主键是自增的),且目标页面上所有记录age都小于或等于x.age。
EXPLAIN SELECT * FROM student WHERE id<#{x.id} AND age>=#{x.age} ORDER BY age DESC LIMIT 10;3.3.8 尝试覆盖索引
详细信息请参考:
MySQL进阶版——覆盖索引、前缀索引、索引下推、SQL优化、主键设计博客——CSDN博客
索引里有满足查询结果的数据,由于不需要返回表,查询效率高,覆盖索引时,“左模糊”、“不等于”都不能使索引失效。
例子:
#没覆盖索引的情况下,左模糊查询导致索引失效
CREATE INDEX idx_age_name ON student(age, NAME);
EXPLAIN SELECT * FROM student WHERE NAME LIKE '%abc';
覆盖索引:包含满足查询结果的数据的索引称为覆盖索引,不需要返回表等操作。
索引是一种高效查找行的方法,但一般的数据库也可以使用索引来查找某一列的数据,因此不必读取整行。毕竟索引叶子节点存储的是它们索引的数据;当你可以通过读取索引来获取所需的数据时,就没有必要读取整行了。
覆盖索引是一种非聚集索引,它包含了查询、JOIN、WHERE子句中用到的所有列(即建立索引的字段正好是覆盖查询条件中涉及的字段)。简单来说,索引列+主键包含了从FROM中查询出来的列。
3.3.9 字符串前缀索引
例如(email(6)),对字符串前缀而不是整个字符串添加索引,前缀长度要根据区分度和长度来决定。
例子:
MySQL支持前缀索引,默认情况下,如果在创建索引的语句中没有指定前缀长度,则索引将包含整个字符串。
mysql> alter table teacher add index index1(email);
#或
mysql> alter table teacher add index index2(email(6));
这两种定义在数据结构和存储上有什么区别呢?下图是这两种索引的示意图。
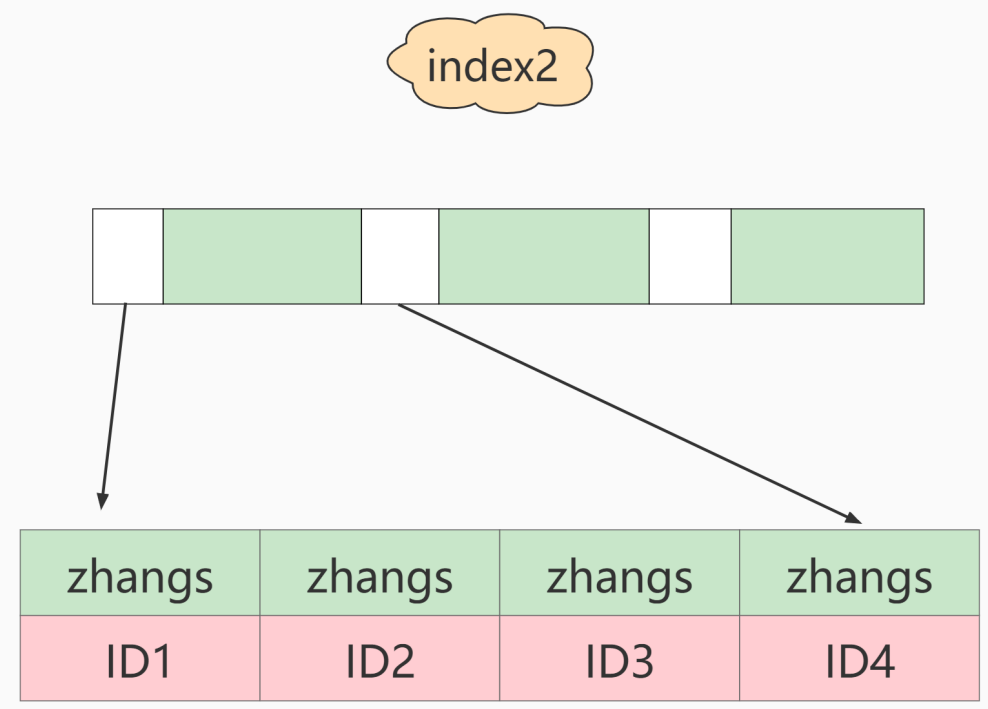
如果使用(index包含整个字符串),则执行顺序如下:
从索引树中找到索引值为' '的记录,并获取ID2的值;回到表中查找主键值为ID2的行,确定email的值正确,将此行添加到结果集中;在索引树上刚刚找到的位置获取下一条记录,发现已经不再满足email=' '的条件,因此循环结束。
在这个过程中,只需要回到主键索引检索一次数据,因此系统认为只扫描了一行。
如果使用(index包含字符串前缀email(6)),则执行顺序如下:
从索引树中查找满足索引值 '' 的记录,找到的第一条为 ID1。回到表中查找主键值为 ID1 的行,判断 email 的值不为 '',丢弃此行。获取刚刚找到的位置的下一条记录,发现仍为 ''。获取 ID2 后回到表中从 ID 索引处获取整行,判断本次值正确,将此行添加到结果集中。重复上一步,直到获取的值不为 '',循环结束。
也就是说,通过使用前缀索引,并定义长度,可以节省空间,而不会增加太多额外的查询成本。歧视性我们已经讲过了,越高越好,因为歧视性越高,重复的键值就越少。
3.3.10 尽量使用.6支持的索引下推
当联合索引的某个字段为模糊查询(非左模糊)时,对该字段进行条件判断后,可直接通过条件判断后面的字段,经过判断过滤后,再返回表格,判断联合索引中未包含的字段条件。
比如索引为(name,age),查询为name like 'z%' and age and ,模糊查询会导致age乱序。
在查询组合索引树时,不仅检查name,还要检查后面的age,过滤后将判断返回到表中。如果关闭索引下推,组合索引中模糊查询(非left)后面的字段在组合索引树中不能直接用条件判断,必须返回到表后再进行判断。
详细解释:
索引下推(ICP,Index)是MySQL 5.6新推出的特性,是在存储引擎层面利用索引过滤数据的一种优化手段。
如果没有 ICP,存储引擎将遍历索引来定位基表中的行并将它们返回给 MySQL 服务器,该服务器将评估 WHERE 语句后的条件来查看是否应该保留这些行。
当启用 ICP 时,如果 WHERE 条件的一部分仅能使用索引中的列进行过滤,则 MySQL 服务器将把 WHERE 条件的这一部分放入存储引擎过滤器中。然后,存储引擎使用索引条目过滤数据,并且只有满足此条件时才从表中读取行。
好处:ICP可以减少存储引擎访问基表的次数,减少MySQL服务器访问存储引擎的次数,但是ICP的加速效果取决于存储引擎内部通过ICP过滤的数据比例。
例子:
不支持下推联合索引:比如索引是(name,age),查询是name like 'z%' and age=?,模糊查询会导致age乱序,查询联合索引树时只会查询name,后面的age会乱序,无法直接判断,必须回表后再判断age。
支持索引下推的组合索引有:比如索引(name,age)查询name like 'z%' and age and,在查询组合索引树的时候,不仅查询name,还会判断后面的age,然后过滤后再返回表进行判断。
CREATE INDEX idx_name_age ON student(name,age);
#索引失败;非覆盖索引时,左模糊导致索引失效
EXPLAIN SELECT * FROM student WHERE name like '%bc%' AND age=30;
#索引成功;MySQL5.6引入索引下推,where后面的name和age都在联合索引里,可以又过滤又索引,不用回表,索引生效
EXPLAIN SELECT * FROM student WHERE `name` like 'bc%' AND age=30;
#索引成功;name走索引,age用到索引下推过滤,classid不在联合索引里,需要回表。
EXPLAIN SELECT * FROM student WHERE `name` like 'bc%' AND age=30 AND classid=2;好处:在某些场景下,ICP可以大大减少表返回次数,提升性能。ICP可以减少存储引擎访问基表的次数,减少MySQL服务器访问存储引擎的次数。但是ICP的加速效果取决于存储引擎中通过ICP筛选的数据占比。
3.3.11 在写比读多的场景下,尽量使用普通索引
在查询的时候,普通索引和唯一索引的效率差不多;在更新的时候,普通索引的效率更高,因为更新的数据页会被缓存在内存中(写缓存),下次访问时或者后台定期进行合并操作,将数据页写入磁盘。
事务提交时会写入重做日志,保证数据持久化。 普通索引:没有限制,如index on(name)。 唯一索引:带参数的索引唯一,如index on(name)。
详细解释:
写入缓存():
当需要更新某个数据页时,如果该数据页在内存中,则直接进行更新。如果该数据页尚未在内存中,这些更新操作会缓存在内存中,不会影响数据的一致性,这样就不需要从磁盘读取该数据页。下次查询需要访问这个数据页时,就会将该数据页读入内存,然后执行这个页相关的操作。这样就可以保证数据逻辑的正确性。
merge:将 中的操作应用到原始数据页上,得到最新结果的过程称为merge。除了访问此数据页触发merge外,系统还有一个后台线程定期进行merge。在数据库正常()过程中也会执行merge操作。
如果能先记录更新操作,可以减少磁盘读取,语句的执行速度可以明显提高。另外数据读入内存时需要占用池子,所以这种方式也能避免占用内存,提高内存利用率。
不能使用对唯一索引的更新,实际上只能使用普通索引。
做出区分:
3.4 SQL优化
详细信息请参考:
MySQL进阶版——覆盖索引、前缀索引、索引下推、SQL优化、主键设计博客 - CSDN博客
合理选择与IN:
遵循小表带大表的原则,如果左表较小,则使用 IN,如果左表较大,则使用 IN。
尝试 COUNT(1) 或 COUNT(*):
当 COUNT(1) 或者 COUNT(*) 时,查询优化器会优先使用空间最小的带索引二级索引树进行统计,只有当找不到非聚集索引树时,才会使用聚集索引树进行统计,这会占用很大的空间。当然也可以使用 COUNT(最小空间二级索引字段),不过让优化器自动选择比较麻烦。当 COUNT(1) 或者 COUNT(*) 时,无所谓,不管哪个,时间复杂度都是 O(1)。
尝试(清除字段):
建议指定字段。查询优化器会花时间解析所有列名的“*”符号,并且“*”符号不能使用覆盖索引。
扫描整个表时尝试使用“LIMIT”:
当扫描全表时,如果知道结果集的记录数,使用limit,这样达到足够多的记录数后就停止扫描,不再扫描全表。如果有索引,就不需要使用limit。
使用极限 N,并使用极限 M,N 较小:
特别是当表很大或者M比较大的时候。
将一个长事务拆分成多个小事务:
尽量使用编程式事务,而不是声明式事务,以减少事务粒度。提交事务可以释放的资源:用于恢复数据的回滚段信息、锁以及重做/撤消日志中的空间。
先勾选后删除修改:
,语句必须有一个明确的WHERE条件。
尝试使用 UNION ALL 代替 UNION:
UNION ALL 不会删除重复项,而且速度更快。
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 