
真巧,昨天刚刚公布了GPT-4(现已集成到微软新Bing中),今天百度又发布了“文心一言”,也即将集成到百度搜索引擎中。 搜索世界已经很久没有这么活跃了。

图片来源Giphy
你不妨想一想,在具有AI语言对话功能的百度搜索中提问:“李彦宏为什么能永远年轻?” 它会如何回答,会向你推荐一家抗衰老医疗美容医院吗?
过去几周,“脑力劳动者”尝到了这一轮AI技术爆发与信息搜索产品结合的好处,发现用它们作为“私人助理”干苦力活也不错。
当你有疑问,不想查很多文献的时候,它会帮你查,“消化”后,用“人性化”的方式给你总结。 在新的 Bing 界面中,您现在一次最多可以与其对话 15 轮。 它具有“理解”上下文的能力,因此您可以提出未回答的问题。
对话新Bing丨图片来源微软Bing
这是与传统搜索引擎体验上最大的区别。 进一步解释一下,新必应的工作原理是将用户问题转换为“搜索语句”。 在传统搜索引擎中搜索查找信息,结合用户的位置、时间信息和上下文,对用户的问题进行有针对性的答复,并标记参考资料的来源。
被诟病的是其引用的来源质量没有保障,存在大量UGC(普通用户生产的内容)和未经权威机构认证的内容。 然后它把这些东西“编出来”。
但至少有一个良好的心态。 想想吧,算了,毕竟你才“刚毕业”。 人们立即将其与传统搜索引擎进行比较。 对于完全公开的事实和信息查询,至少可以节省你查看和阅读材料的时间。
如果再这样下去,传统搜索引擎会被“抛弃”吗? 它是如何慢慢变得越来越难用的?
搜索引擎如何工作
人们总是在寻找获得更准确答案的方法。 在万维网出现之前,人们依靠ftp协议来共享文件资源。 当出现可搜索的文件名列表(称为)时 - 您必须逐字输入文件名,返回的是可以下载该文件的 ftp 地址。
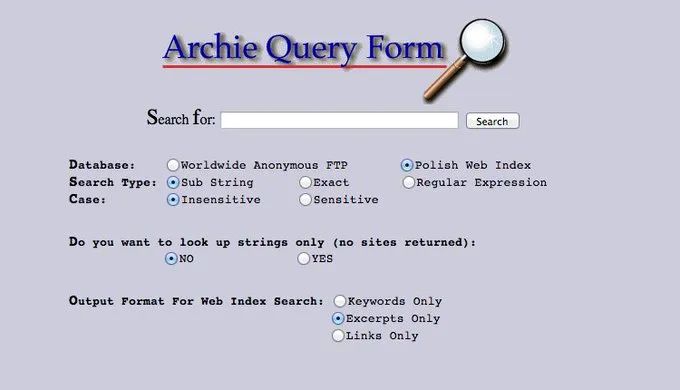
丨图片来源@
听起来很费力,但毕竟直到1990年人们才开始“搜索”互联网。 由此产生的网络搜索需求促使开发人员想到了两种解决方案。
一是手动收集编译URL(学名是 ,可以理解为成果就是一个URL),比如曾经大家都熟悉的Yahoo; 另一种是开发一个自动程序来搜索万维网并返回与用户搜索匹配的查找结果。 这种自动化程序称为爬虫。

爬虫机器人丨图源101
并不是爬虫收到用户查询指令后去海量的万维网寻找“答案”,而是爬虫定期抓取新的网页,将其收集到原始页面数据库中,然后进行预处理。 最后根据查询关键词,排序后返回网页。 由于数据存储限制,一开始无法保存所有爬取的数据。 仅抓取 URL、标题和简介。 后来出现了可以抓取全文的爬虫,这让它们更接近今天搜索引擎的概念。
如果你想知道“为什么这些网页会排名在第一页?”,你首先必须知道搜索引擎是如何工作的。
如上所述,爬虫完成第一步采集工作后,需要对数据进行预处理,例如去重、删除营销账号内容、判断后续采集的网页是否抄袭等。
那怎样才能快速“匹配”呢? 数据还需要分类。 搜索引擎处理页面和用户搜索时,都是基于单词的。
页面被转换成许多关键词的集合,反过来说,每个关键词对应一系列文件。 当用户搜索某个关键字时,程序不仅能在“倒排索引”中找到该关键字,而且还知道包含该关键字的所有文件,以及该关键字在每个页面出现的频率、格式和位置。 ETC。
但搜索引擎如何知道“如何分词”呢? 尤其是在中文上下文中,比如输入“香蕉牛奶”时,你就知道它不仅指“香蕉和牛奶”,还指“香蕉味牛奶”。 这是通过研究大量网页上的文本样本并计算单词彼此相邻出现的概率来完成的。 彼此相邻的单词越多,它们形成单词的可能性就越大。
卡内基梅隆大学的一位计算机科学家将搜索定义为“信息的检索和选择性传递”。 选择向用户展示内容的关键词是“相关性”。
最初,搜索引擎只是按照在数据库中找到匹配信息的顺序对搜索结果进行排名。 后来通过简单的内容分析,增加了更多的相关性维度。
我们知道用户的问题需要被分解成一串关键词。 词频和密度是因素。 页面上出现的搜索词越多,密度就越高,这意味着页面与搜索词更相关。 同样,如果关键字具有特殊格式(标题、标签、粗体、H标签、锚文本),则关键字出现得越早,与网页内容相关的可能性就越大。
搜索引擎怎么知道我要搜索的“苹果”是“”?
但你发现似乎没有什么“相关性”可以解决“链接质量”的问题。 它借助(超链接分析算法)解决了这个问题,从而声名鹊起。 该算法评估网页传入链接的质量和数量。 就好像,不仅科技巨头在研究它,就连你用快手快手版的奶奶也想问,“这个东西怎么发音?”
因此,基于“指向网页A的网页越多,说明网页A越重要”和“指向网页A的优质网页越多,说明网页A越重要”这两点,算法对网页进行评分(PR值),PR值越高的网页越多,可以排名靠前。 无论是《纽约时报》引用还是机器人大量制作的网页引用,权重都是不同的。

图片来源Giphy
当然,排序程序是一个“复杂的算法”,超链接分析只是其中一个“因素”。 一家数字营销公司总结了最影响搜索排名的13个因素:
· 内容质量
· 独特的内容
· 完全可抓取的页面
· 适用于任何设备
· 超链接数量
· 域名权重,域名权重越高,网站所有网页排名越高
· 不知道
· 网页加载速度
· 关键词匹配度
·(语义理解算法,能够理解关键字背后的概念,而不是局限于单词本身。这关系到搜索引擎在被问到以前从未问过的问题时如何理解你想问的内容。)
· 匹配搜索意图(如果您从第一个搜索结果中点击并快速返回,则表明该结果不满足您的要求。)
· 内容新鲜度
· 专业、权威、可信
这些只是众多影响因素中的一部分。 一一拆解之后,我们需要仔细研究。 例如,如何识别内容的质量? 您可以参考以下标准。 文章越长,应该越全面; 客观事实的呈现比“主观抒情”更有用; 结构化内容更易于阅读(对于人类和机器而言)。
根据上述,“排名算法”决定是否推荐“带手柄的红色水果”或“苹果公司”。 当您搜索“苹果价格”时; 这也决定了今天的结果是更高的,而不是原来的价格。
搜索引擎“变坏了”
2006年,研究人员在Ask、MSN和Yahoo上进行了12,570个“查询”的首页搜索结果,发现84.9%的结果对于每个搜索引擎来说都是唯一的,1.1%的结果对于所有搜索引擎来说都是通用的。 只有 7% 的热门搜索结果是相似的。
2011 年,研究人员收集了 Bing 上 40,000 个查询返回的结果。 域名重叠度达29%,且独特域名较多。 无论排名如何,结果集之间的相似性都会增加。 “这表明 Bing 和 Bing 有不同的排名偏好,但索引的来源大多相同。”
同样,2016年的一项研究表明,Bing上的67个“信息查询”的前10名结果具有较高的重叠度,前5名结果的相似度稍高。
这些研究进展并不能完全回答“为什么百度和搜狗搜索到的第一条结果不同”。 但它们似乎表明,不同搜索引擎上搜索结果的重叠随着时间的推移而增加,排序算法是结果差异的主导因素。 原因。
原因是爬虫和索引都是纯技术部分。 截至目前,各家公司的技术已经成熟,几乎相同。 在整理和展示阶段,有资本和商业的考虑。 这会让你意识到,“为什么排名靠前的要么是广告(竞价排名),要么是搜索引擎自己的内容?”
竞价排名可以追溯到一家名为GoTo(后来更名)的公司,该公司通过拍卖关键词和收取点击次数赚了很多钱。 当然,其他搜索引擎后来也纷纷效仿。
搜索引擎广告丨图片来源主营
“找不到”的事情不仅仅是因为搜索引擎想要赚钱。 在互联网的发展过程中,诞生了一个叫做搜索引擎优化(SEO)的“职业”。
既然搜索引擎设计了一套排名算法,那么应该可以利用“规则”来提高网站在搜索引擎内的自然排名。 但更多时候它是反面教材。 低权重、低质量的网页会伺机“欺骗”搜索引擎系统以获得更高的排名。
由于搜索引擎将入站链接视为主要排名因素之一,因此从其他网站获得“自然链接”并不那么容易。 有些人干脆建立多个网站,然后将其指向自己想要提高排名的网站——大量“垃圾链接”应运而生。
再比如“人为创建”的关键词,被搜索引擎抓取到,但用户点击后发现没有想要的信息。 在网页的HTML文件中,编写只能被搜索引擎“看到”而用户看不到的关键字,以增加关键字密度以及网页与搜索请求之间的“相关性”。
提高排名有多重要? 据报告显示,自然搜索(无广告干预)排名第一的搜索结果点击率为27.6%,前三名占总点击次数的54.4%,只有0.63%的人会点击到第二页。
渐渐地,你发现很多网站并没有提供有效的信息,却排名靠前,“废话文学”等低质量内容在其中泛滥。
如果说竞价(或人工干预)排名是搜索引擎“选择”的结果,那么搜索范围的缩小则改变了搜索引擎的存在。
每个人都有自己的“搜索引擎”
2008年,淘宝禁止百度爬虫。 类似的例子在国内外并不少见。 这涉及到谁是“流量入口”以及商业利益的权衡。 对于用户来说,搜索引擎并不好用。 这一点在移动互联网时代更加明显。
在数据垄断的划分下,用户被期望直接在各自的App内完成行为闭环。 新添加的互联网内容被“锁定”在各自的应用程序中。
想知道KOL刚才说了什么吗? 去微博和。 如果你想剧透《黑暗荣耀》的结局,就去豆瓣吧。 搜索引擎只能找到XX号“鸡汤谈”。 当你产生“吃川菜”的念头时,你很可能想找到一家价格实惠、性价比高、离你近的餐厅。 最好知道怎么去,而不是“你知道川菜八大菜系是哪一个吗?” ?”。
图片来源Giphy
您知道通常可以在哪里获得更“具体”的答案。 这个时候,我们往往“不想要一个事实,或者一个客观存在的结果”。 某老牌股权投资机构合伙人塔利亚将这种搜索行为解释为“主观搜索”( )。
严格来说,小红书等并不是“搜索引擎”,但是当我们想要解决生活中遇到的大部分问题时,它们已经非常有用了。 它们涵盖了新闻资讯、评论、生活经历等动态信息,保证了我们想要获取的“新知识”的时效性。 它更像是对各种公共信息(传统搜索引擎)进行“加工”后的实用建议和详细操作指南。
小红书搜索丨图片来源小红书
但如果你对“推荐算法”心存疑虑,“主动搜索”仍然是冲破信息茧、警惕技术的有效途径。
网络上的内容冗余、复杂,需要耐心去搜索。 以下是搜索技术指南:
· 使用搜索词 site: link 在特定网站内搜索
注意:站点后必须使用英文字符
例:人工智能站:,指在国科网搜索人工智能相关文章
·“搜索词-排除内容”排除您不想在搜索结果中看到的内容。
注意:搜索词后面必须跟一个空格。 - 是英文减号,后面不能有空格。
示例:滑盖手机 - 诺基亚,指有关滑盖手机的页面,但不包括与诺基亚相关的部分
(同样,“和”可以用“空格”表示,“或”可以用“或”表示)
前两种搜索语法也可以混合使用
示例:滑盖手机网站:,指滑盖手机相关页面,但不包括淘宝
·“搜索词”搜索的是作品,而不是文字
· ": term" 仅显示标题中包含搜索词的结果
注:“:”为英文字符
示例::三体动画版,指标题中含有三体动画版的内容
·“搜索词:格式后缀”搜索特定格式的文件
注:“:”为英文字符
示例:简历模板:doc,指Word格式的简历模板。
人们的搜索习惯已经改变。 但目的仍然是一样的。 也就是缩短提问和回答之间的时间。 2012年,创建“知识图谱”项目。 这意味着一切事物都可以形成一个关系网络。 当用户搜索A时,与A“相关”的信息片段将呈现在结果页面上。 直接片段呈现的目的是让搜索引擎直接回答用户问题,而无需用户点击链接。
拉里·佩奇和布林已经被召回参与公司业务(他们以前是写算法的),布林甚至还亲自去为聊天机器人编写代码。
看来人们需要一种新的获取信息的手段来取代传统的搜索引擎,“就像搜索引擎杀死了黄页一样”。
参考
[1]
[2]
[3]
[4]
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 