
前言 在后端开发中,为了防止一次性加载过多的数据,造成内存和磁盘IO开销过大,经常需要分页,这时候就需要用到MySQL的LIMIT关键字了。但是你以为LIMIT分页就可以了吗?太年轻了,要
前言
在后端开发中,为了防止一次性加载过多的数据,造成内存和磁盘IO开销过大,经常需要分页,这时候就需要用到MySQL的LIMIT关键字了。但是你以为LIMIT分页就可以了吗?太年轻,太多了。当数据量很大的时候,LIMIT可能带来的一个问题就是深度分页。
案件
这里我以电商订单详情的展示为例,新建的表格如下:
CREATE TABLE `cps_user_order_detail` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键', `user_id` varchar(32) NOT NULL DEFAULT '' COMMENT '用户ID', `order_id` bigint(20) DEFAULT NULL COMMENT '订单id', `sku_id` bigint(20) unsigned NOT NULL COMMENT '商品ID', `order_time` datetime DEFAULT NULL COMMENT '下单时间,格式yyyy-MM-dd HH:mm:ss', PRIMARY KEY (`id`), KEY `idx_time_user` (`order_time`,`user_id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='用户订单详情';
然后手动向表中插入120万条记录。
现在有个需求:分页展示用户的订单详情,按照订购时间倒序排列。
表结构精简,需求简单,于是我赶紧写好了代码,放到网上测试,前期一切运行正常,但随着订单量的不断增加,我发现系统变得越来越慢,有时候会报出几个慢查询。
此时你应该想到是LIMIT偏移量的问题了,是的,不是你的SQL不够优美,而是MySQL本身的机制。
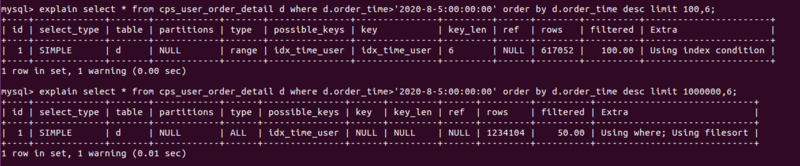
这里我简单拿两条SQL来举例,如下图,分别从100和100万的位置进行分页,可以看到时间差别非常大,这还不包括其他数据计算和处理的时间,单条SQL的查询就需要1秒以上的时间,这在提供给用户的功能上是无法容忍的(电商往往要求一个接口的RT不超过200ms)。
下面我们看一下执行计划,如下所示:
这里我们先介绍一下执行计划中Extra列的可能取值及含义:
Using where:表示优化器需要通过索引来查询数据。Using index:即覆盖索引,表示直接访问索引就足以获取需要的数据,不需要通过索引去查询表,通常是通过对需要查询的字段建立联合索引来实现的。Using index:5.6版本之后加入的新特性,大名鼎鼎的索引下推,是MySQL为了减少表查询次数的一项重大优化。Using:文件排序,这个一般在ORDER BY的时候用,数据量过大,MySQL会把所有数据调到内存中进行排序,比较消耗资源。
再看上图,同样的一条语句,仅仅因为不同,就导致执行计划有很大差异(我稍微夸张一点),第一条语句中,LIMIT 100,6type列的值为range,也就是范围扫描,性能比ref低一个级别,但是也算是使用了索引,也应用了索引下推:也就是WHERE之后的排序时间都是使用索引进行删除选择,并且后续的ORDER BY也是基于索引下推进行优化,在WHERE条件过滤的时候同步进行(不进行表回退)。
第二条语句 LIMIT,6 根本没用到索引,而且 type 列的值为 ALL,明显是全表扫描。而且 Extra 字段中的 Using where 表示发生了表返回,Using 表示 ORDER BY 时发生了文件排序。所以这里慢的原因有两个:一是文件排序耗时过长,二是按照条件筛选相关数据后,还需要按照偏移量返回表才能获得所有的值。不管以上哪一点都是因为 LIMIT 偏移量过大导致的,所以实际开发环境中经常会遇到非统计表级别不能超过百万的需求。
优化
既然分析完了原因,那在实际开发中该如何优化 LIMIT 深度分页呢?下面介绍两种解决方案。
第一种是通过主键索引进行优化,什么意思呢?就是将上面的语句修改成:
SELECT * FROM cps_user_order_detail d WHERE d.id > #{maxId} AND d.order_time>'2020-8-5 00:00:00' ORDER BY d.order_time LIMIT 6;
如上代码所示,同样是分页,但是有一个maxId的限制,这个是什么意思呢?maxId是前一页中最大的主键ID。所以使用该方法的前提是:1)主键必须是自增的,不能是UUID。前端除了传递基本的分页参数外,还必须带上前每一页的最大ID。2)该方法不支持随机页面跳转,即只能上下翻页。下图是某知名电商中实际的页面。
第二种是通过搜索引擎(基于倒排索引)。其实像淘宝这样的电商基本上把所有商品都放到了 ES 的搜索引擎里(这么大的数据量不可能放到 MySQL 里,放到 Redis 里也不现实)。但即便是使用 ES 的搜索引擎,还是有可能出现深度分页的情况。这时候该怎么办呢?答案就是通过游标。这点我这里就不多说了,有兴趣的可以研究一下。
概括
写这篇博客是因为前段时间在开发中也遇到过,在字节跳动的面试中也和面试官讨论过。知道 LIMIT 的限制和优化,在面试中是一个加分项。不能说 MySQL 优化就是建索引、调 SQL(其实这两种优化方案在实际开发中作用不大),毕竟如果 MySQL 优化这么牛逼,也不会有这么多中间件。
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 