
演示视频介绍
中间层主要依靠语言构建,设置这样一个中间层的原因是什么?由于涉及AI的组件和外部库大多已经提供或者能够提供,虽然也可以用java编写这些逻辑,但所需付出的成本极高。本代码涵盖了向量化处理、向量数据库保存、调用等功能。所依赖的外部库有,,,,等等。
这份资料意在引发思考,为众多兴趣人士或业内人员提供参考,便于他们研究或参考。
代码讲解
这个时期,由于某个事物迅速走红,许多依托于大型语言模型的应用如雨后竹笋般涌现,进而再次点燃了人们对语言的关注,并促进了相关技术的普及。经过这段时间的深入探索,了解到围绕语言构建的第三方工具极为丰富,其中多数工具已相当完善,它们都曾服务于众多实际项目。比如当前项目所依赖的关键模块,它是一个面向微信机器人开发的公开资源。它能够同微信软件进行沟通,可以自动传送信息、获取信息、照管用户、应对团体聊天等跟微信有关的动作。
的主要功能包括:
消息处理功能支持收发各种格式的信息,包括文字、图像、音频和视频等,能够应对一对一和多人交流的场景。
联系人维护:能够调取全部联系人记录,可以搜寻特定联系人,能够增设新的联系人,能够移除已有联系人,能够查询联系人的详细资料,例如个人网名和照片。
群聊维护:能够取得群组清单、搜寻群组、发起群组、参与群组、终止群组等行为,能够取得群组的参与人员清单、传送群组信息等。
事件处理能够应对各类与微信相关的情形,包括账号的接入情形、账号的离开情形、信息的接收情形、联系人的变动情形等。
插件扩展能够借助编程实现功能拓展,支持个性化消息管理,以及事件响应等操作。
能够轻松创建各类微信助手,包括自动应答助手、群组维护助手、信息通知助手等。它配备了简明的应用程序接口和多样的功能特性,让技术人员可以迅速构建并调整个性化的微信助手。必须留意的是,这是一个外部开发工具,并非微信官方推出的接口,因此在运用时须遵循微信的操作准则和约束,以保障合法合理地运用微信相关服务。
该项目还运用了某个图像操作工具,该工具源自于名为PIL的图像库的一个分支,它具备多样的图像处理能力,能够对多种不同格式的图像文件进行读取、编辑以及存储操作。
库可以用于各种图像处理任务,包括但不限于以下功能:
图片的打开和存储功能,能够处理包括JPEG、PNG、BMP、GIF在内的多种不同格式图像文件,支持读取和写入操作。
图像尺寸调节:能够改变图片的尺寸,对图片进行放大或缩小处理,也可以选取图片中的某个区域进行裁减。
图像能够进行角度转动,也可以实施水平方向或者垂直方向的颠倒处理。
图片处理时,能够运用多种处理方式,包括使画面变得朦胧,增强清晰度,以及突出轮廓线条等。
图像可以进行亮度调整, 对比度处理, 色彩平衡更改, 还能实施颜色空间转换
图像组合与覆盖:能够把好几个画面整合为单个画面,亦可在画面上增加文字、图案等物件。
图像资料及其加工:能够取得图像的规格、色彩类型、像素数据等资料,也能够实施像素层面的调整。
这个库操作简便,用途十分广泛,涵盖了许多方面,例如对图像进行加工、对视觉信息进行分析、对图像内容进行识别、对图像进行创作等。不管是基础的图像编辑工作,还是高级的图像解析任务,它都提供了多种多样的工具和可调节的参数,让程序员能够轻松地处理和操作图像。
企起期团队针对预制问题的解答需求,研发了专用插件,若查询内容的相似程度符合预设条件,系统将采用预制问题进行回应,若相似程度未达标,则由相应的大型模型来承担处理工作。
以下通过问答检索和插件实现来进行代码讲解。
问答匹配检索
常规的语句比对多采用类似度比对或是搜索引擎的词语拆分技术,人工智能范畴内的文本匹配则广泛采纳向量比对技术,这种技术核心是将文本资料转化为向量形态,继而测量不同向量间的距离或角度,借此判定文本间的近似程度,常用的向量比对技术涵盖余弦相似度、欧氏距离以及相似度计算等手段各家企业采用的数值化方法不尽相同,当前市场上广受欢迎的数值化方法有:
它是一种运用神经网络技术实现的词向量编码方案,借助模型训练将每一个词汇对应成一个预设长度的数值序列,表现良好,可以识别出词语之间蕴含的意义关联。
GloVe是一种通过全局词频统计来构建词向量的方法,采用矩阵分解技术将词语转化为向量形式。这种方法具有较高的准确度,能够有效识别并表现词语之间的语义关联性。
它是一种以子词为单位的词向量方法,把词语分解成子词,再把子词的向量值进行算术平均或加权平均,从而得到整个词语的向量表示。这种方法的精确度较高,可以应对新出现的词汇以及词语的各种变化形态。
BERT是一种预训练语言模型,它将每个词语表示成与上下文相关的向量,这种表示方法准确性较高,并且能够捕捉到词语的上下文信息。
不同企业的巨型语言模型的训练数据在体量与品质以及构造设计上有所区别,致使向量式配对的精确程度不尽相同,不过随着时间发展,往后必然会产生愈发精准的配对方法,现阶段来看,较为精准的有,文心一言,BERT等等。
这个项目利用指定的接口执行数据向量化处理,向量化后的信息保存在专门的数据库里,相似度问题的比对则使用了自定义的函数。
代码如下:
import psycopg2
import configparser
import openai
import os
from common.log import logger
当前目录路径赋值给变量长句,通过os.path.dirname函数获取,参数为文件所在位置字符串
# 读取配置文件
创建一个配置解析器对象,命名为config
配置文件路径是当前目录与文件名组合的结果,文件名为配置文件,后缀为ini
config.read(config_path)
# 从配置文件中获取数据库连接信息
主机名通过配置获取,默认值为数据库设置中的主机字段
配置文件中获取数据库端口号,若未指定则默认为某个值
数据库 = 配置获取的值,如果未指定则默认为数据库
获取配置信息,首先定位到数据库部分,然后从中提取用户名,如果没有指定则默认为用户
密码是从配置中获取的,根据数据库键值,如果没有指定则使用默认密码
配置文件中获取数据库相关的api_key值,如果没有找到则默认为api_key
从配置文档中取得预设的相近程度,若问题的匹配值低于此数值,就将该问题剔除掉
预期相似度值从配置中获取,默认为expect_similarity
def getAnswer(question):
# 连接数据库
conn = psycopg2.connect(
host=host,
port=port,
database=database,
user=user,
password=password
)
# 创建游标
cur = conn.cursor()
# 调用OpenAI的嵌入API获取嵌入值
openai.api_key = api_key
回应由openai.Embedding发起创建
模型是文本嵌入ada002版本,
input=question
)
# 提取嵌入值
嵌入向量等于响应数据中的第一个元素的嵌入部分
#print(embedding)
# 执行查询语句
数据库查询指令执行,选取问答内容,包括问题,答案,以及标记数据,从表格中获取信息
# 执行函数
执行查询操作,传入向量参数,相似度阈值设为0.5,返回最多三个结果,按第一列排序,查询语句为SELECT所有列FROMmatch_questions函数,参数依次为 embedding,0.5,3,1
# 获取查询结果
results = cur.fetchall()
answer = ''
if len(results)>0:
相似度等于结果列表第一个元素的第五个值
记录日志信息,内容为从数据存储里查找向量相合情况,查询事项是{question},查到数据存储里相合的事项是{results[0][1]},相合事项的应答是{results[0][2]},相合程度是{results[0][4]},需要达到的相合程度是{expect_similarity}
如果相似度值大于等于期望相似度值
答案就是结果列表第一个元素的第三个项
# 关闭游标和连接
cur.close()
conn.close()
return answer
这段程序首先引入了必要的组件和工具包,涵盖、以及、os、.log等,接着,它构建了一个特定的功能模块。
程序首先从.ini配置文件中获取数据,内容包括数据库连接参数和所需的匹配精度。接着,程序建立与数据库的连接,并基于该连接生成一个数据库操作指针。
接着针对收到的疑问,调用相应的接口,获取关联问题的数值表示,然后借助指针运行对应的程序,得到反馈信息。
结果列表非空,需评估其相似程度,若符合预设标准,则输出匹配项,否则继续后续流程。
以下是的函数:
新增或者替换一个名为匹配问题的函数,该函数接收四个参数,第一个参数是名为嵌入的向量类型数据,第二个参数是名为匹配阈值的浮点数类型数据,第三个参数是名为匹配计数的整数类型数据,第四个参数是名为最小内容长度的整数类型数据 返回一个表格,其中包含以下列,列名分别为编号,问题内容,答案内容,标识符,相似度值,该表格通过以下代码生成,代码块开始于$BODY$ 出现变量冲突的情况时,需要调用变量 begin return query select tb_qa.id, tb_qa.question, tb_qa.answer, tb_qa.tokens, (tb_qa.embedding <#>嵌入乘以负一作为相似度 from tb_qa 当tb_qa.question的长度大于等于最小内容长度时 and (tb_qa.embedding <#>嵌入向量乘以负一,结果大于匹配阈值 order by tb_qa.embedding <#> embedding limit match_count; end; $BODY$ LANGUAGE plpgsql VOLATILE COST 100 ROWS 1000
根据前述数据源的运算方法可知,依据输入的因子,经由运算可得出相应的数据条目,该方法的参数共计四个:
: 问题的向量数据
:期望的匹配度
:返回的结果集数量限制
:最小的内容限制
其中就是表示2个向量的相似度运算符
插件
在微信传输相关内容时,必须保存信息以便对照预设问题进行核对,倘若未能找到对应项,就依照既定步骤由通用人工智能模型来回应。下面是关于插件的部分程序代码:
# encoding:utf-8
import plugins
从桥的上下文中导入上下文类型
在桥的回复模块中导入回复类和回复类型枚举
从通道聊天消息中导入聊天消息
from common.log import logger
from plugins import *
从pgvector库中获取答案
@plugins.register(
name="QIQIQI",
desire_priority=800,
hidden=True,
desc="企起期微信助手",
version="0.1",
author="qiqiqi",
)
class QIQIQI(Plugin):
def __init__(self):
super().__init__()
self.handlers[事件类型.处理上下文] = self.处理上下文
记录器输出信息,内容为方括号内包含特定标识的初始化完成提示,标识内容为QIQIQI
处理事件上下文时,调用特定函数,参数为事件上下文对象
如果上下文信息中的类型不在以下列表之中
ContextType.TEXT,
加入群组类型,
特定情形类型为那个,具体为这个
]:
return
当e_context中的context属性值为ContextType.JOIN_GROUP时
e_context的context属性值设定为文本类型,该类型属于上下文类别
消息内容,即ChatMessage类型,是从事件上下文中的上下文键值对中提取的msg字段获取的
e_context["context"].content等于用软件企业客户服务人员的口吻表达欢迎新成员"{msg.actual_user_nickname}"加入团队的问候。
事件完成,触发终止动作,程序开始遵循预设流程执行
return
当e_context中的context属性类型为PATPAT时
e_context["context"].type = ContextType.TEXT
msg: ChatMessage = e_context["context"]["msg"]
e_context["context"].content = "请你以软件企业服务部门的口吻说明你的身份。"
e_context.action = EventAction.BREAK # 事件结束,进入默认处理逻辑
return
内容等于上下文信息中的上下文部分的内容
记录器调试信息显示,在处理上下文时,内容为百分之百准确的数据
答案通过调用getAnswer函数获取内容的结果
若回答并非空字符串,
reply = Reply()
回复的类型是文本类型,回复的内容是文字信息,回复的性质属于文本格式,回复的类别被定义为文本。
msg: ChatMessage = e_context["context"]["msg"]
回复内容等于答案
上下文信息中的回复字段被赋值为该回复内容,
事件终止,不再执行后续的常规操作,直接越过针对上下文的预设流程
else:
e_context的行为设置为事件动作的继续状态
获取帮助文本,根据不同参数动态生成内容,具体实现方式如下
输入你的疑问,我将提供相应的解答,所有的问题和答案都由qiqiqi智能助手系统负责管理维护
return help_text
根据上文代码分析,需先确认信息类型,判断其是否属于文字信息、群组加入通知或微信轻拍提示,若不属于这三种情形,则无需操作直接结束程序。
若收到的信息是邀请入群的通知,或者是微信轻拍的动作,就依照事先准备好的话语,选用合适的大型语言模型来回应。
收到的微信信息若为文字类型,就采用前面说明过的方式准备问题的应答,倘若资料库里有相配的回应,便直接输出该回应并且不再执行后续的相关操作,倘若资料库中找不到相应的回应,就依照程序的基本流程继续开展。
微信客户端展示情况如下,采用"/"字符发起疑问,此符号可在设定文档中调整。
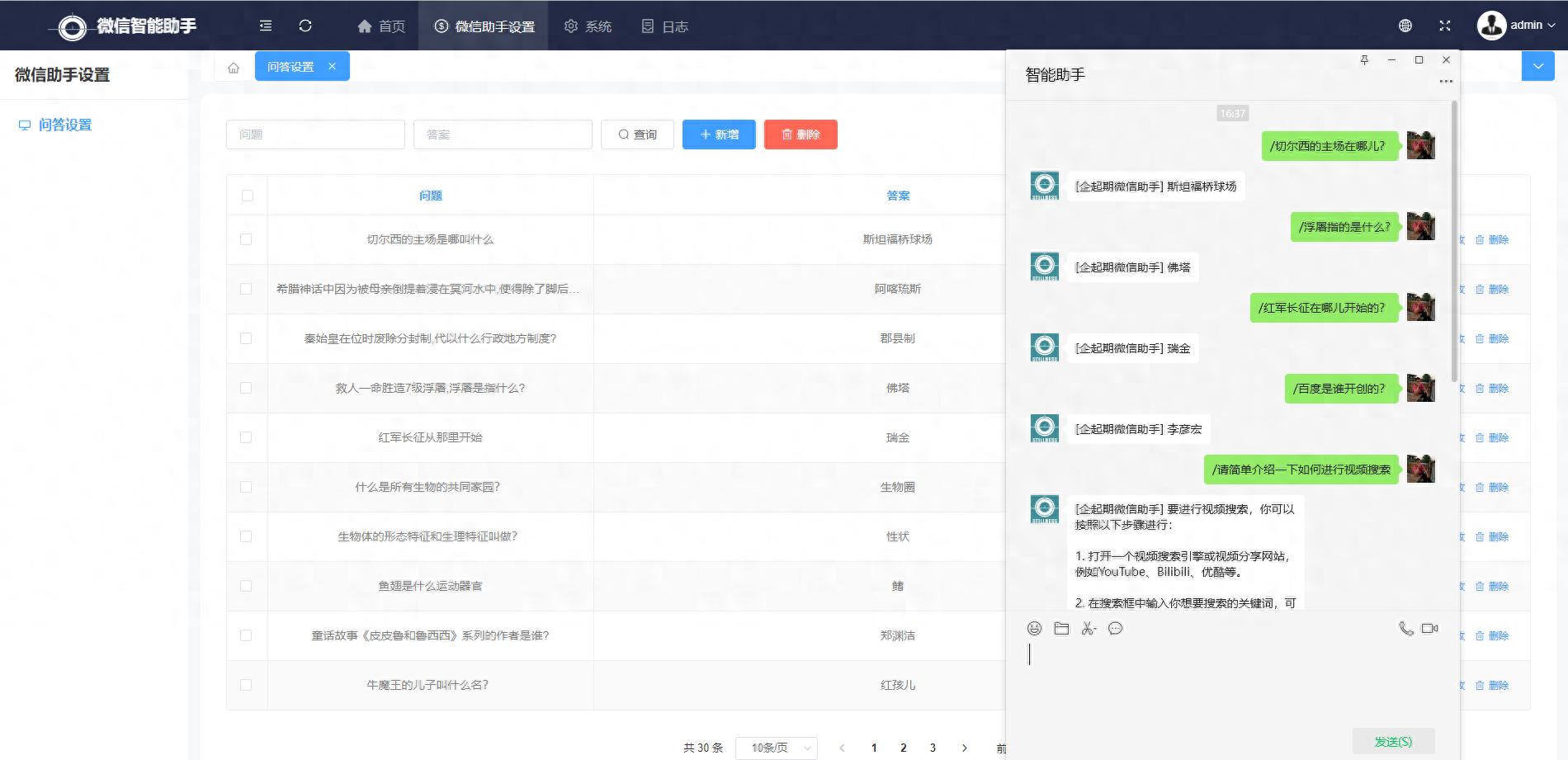
从图片中可以观察到,所提疑问与数据库内记录的疑问并非完全一致,然而匹配过程产生的结果精确度达到了百分之百,这充分展现了向量匹配的强大功能!
通过之前的微信截屏内容可以发现,当查询的问题在资料库中寻不到现成回复时,系统会自主启动大型语言模型来处理提问。实际上,在具体工作中,这个环节可以换成请求企业的其他服务接口来应对问题,或者发送关联通知,并借助人工介入开展客户服务。
这项计划意在启发思考,在现实操作中,能够构建机器人客服系统,或者实现企业数据即时检索,亦或是提供其他关联性服务。可以通过微信平台,或其公众号,乃至企业专属账号来运用,亦可进行直接对接,等等,当然,网页形式和手机应用同样适用。交互方式并非局限于文字传递,同样兼容语音的录入,语音的输出,以及图像的展示等等。当然,需要进行对应的开发工作!
诚邀有志之士洽谈合作,促使人工智能切实造福社会,实现其应有的贡献!!!
扫一扫在手机端查看
我们凭借多年的网站建设经验,坚持以“帮助中小企业实现网络营销化”为宗旨,累计为4000多家客户提供品质建站服务,得到了客户的一致好评。如果您有网站建设、网站改版、域名注册、主机空间、手机网站建设、网站备案等方面的需求,请立即点击咨询我们或拨打咨询热线: 13761152229,我们会详细为你一一解答你心中的疑难。
 客服1
客服1 